 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTools for Verifying Neural Models' Training Data
Jul 02, 2023



It is important that consumers and regulators can verify the provenance of large neural models to evaluate their capabilities and risks. We introduce the concept of a "Proof-of-Training-Data": any protocol that allows a model trainer to convince a Verifier of the training data that produced a set of model weights. Such protocols could verify the amount and kind of data and compute used to train the model, including whether it was trained on specific harmful or beneficial data sources. We explore efficient verification strategies for Proof-of-Training-Data that are compatible with most current large-model training procedures. These include a method for the model-trainer to verifiably pre-commit to a random seed used in training, and a method that exploits models' tendency to temporarily overfit to training data in order to detect whether a given data-point was included in training. We show experimentally that our verification procedures can catch a wide variety of attacks, including all known attacks from the Proof-of-Learning literature.
On Implicit Bias in Overparameterized Bilevel Optimization
Dec 28, 2022Many problems in machine learning involve bilevel optimization (BLO), including hyperparameter optimization, meta-learning, and dataset distillation. Bilevel problems consist of two nested sub-problems, called the outer and inner problems, respectively. In practice, often at least one of these sub-problems is overparameterized. In this case, there are many ways to choose among optima that achieve equivalent objective values. Inspired by recent studies of the implicit bias induced by optimization algorithms in single-level optimization, we investigate the implicit bias of gradient-based algorithms for bilevel optimization. We delineate two standard BLO methods -- cold-start and warm-start -- and show that the converged solution or long-run behavior depends to a large degree on these and other algorithmic choices, such as the hypergradient approximation. We also show that the inner solutions obtained by warm-start BLO can encode a surprising amount of information about the outer objective, even when the outer parameters are low-dimensional. We believe that implicit bias deserves as central a role in the study of bilevel optimization as it has attained in the study of single-level neural net optimization.
Meta-Learning to Improve Pre-Training
Nov 02, 2021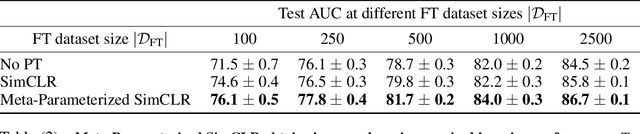

Pre-training (PT) followed by fine-tuning (FT) is an effective method for training neural networks, and has led to significant performance improvements in many domains. PT can incorporate various design choices such as task and data reweighting strategies, augmentation policies, and noise models, all of which can significantly impact the quality of representations learned. The hyperparameters introduced by these strategies therefore must be tuned appropriately. However, setting the values of these hyperparameters is challenging. Most existing methods either struggle to scale to high dimensions, are too slow and memory-intensive, or cannot be directly applied to the two-stage PT and FT learning process. In this work, we propose an efficient, gradient-based algorithm to meta-learn PT hyperparameters. We formalize the PT hyperparameter optimization problem and propose a novel method to obtain PT hyperparameter gradients by combining implicit differentiation and backpropagation through unrolled optimization. We demonstrate that our method improves predictive performance on two real-world domains. First, we optimize high-dimensional task weighting hyperparameters for multitask pre-training on protein-protein interaction graphs and improve AUROC by up to 3.9%. Second, we optimize a data augmentation neural network for self-supervised PT with SimCLR on electrocardiography data and improve AUROC by up to 1.9%.
Complex Momentum for Learning in Games
Feb 16, 2021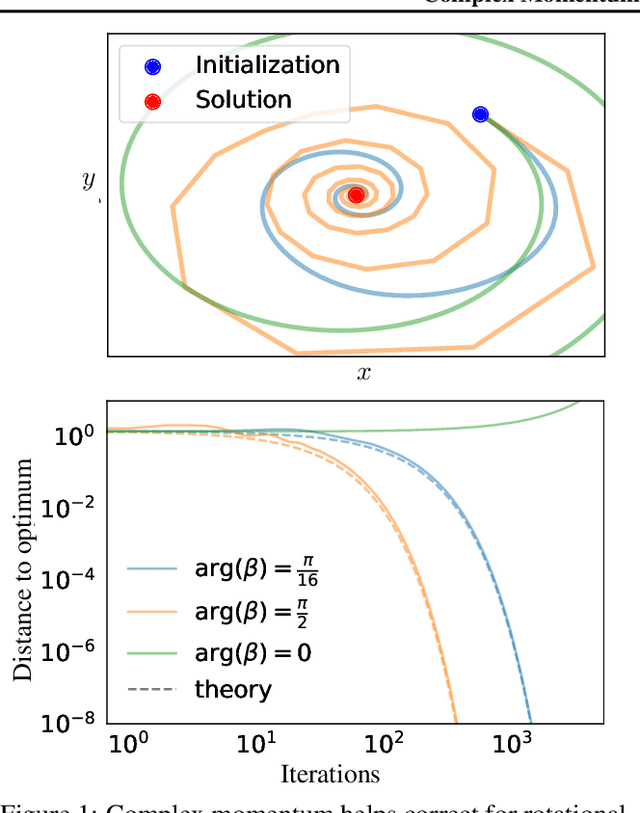

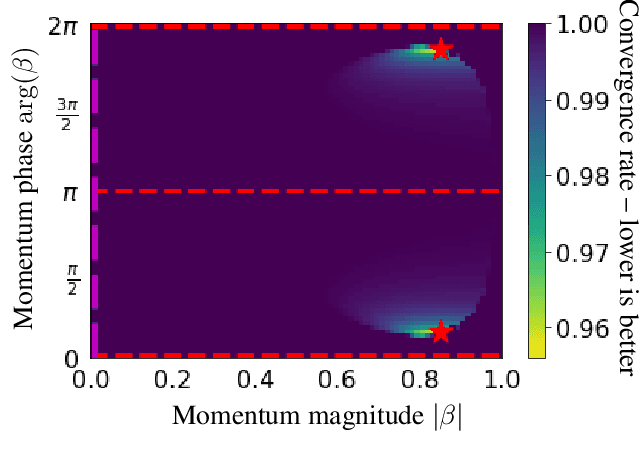

We generalize gradient descent with momentum for learning in differentiable games to have complex-valued momentum. We give theoretical motivation for our method by proving convergence on bilinear zero-sum games for simultaneous and alternating updates. Our method gives real-valued parameter updates, making it a drop-in replacement for standard optimizers. We empirically demonstrate that complex-valued momentum can improve convergence in adversarial games - like generative adversarial networks - by showing we can find better solutions with an almost identical computational cost. We also show a practical generalization to a complex-valued Adam variant, which we use to train BigGAN to better inception scores on CIFAR-10.
Infinitely Deep Bayesian Neural Networks with Stochastic Differential Equations
Feb 12, 2021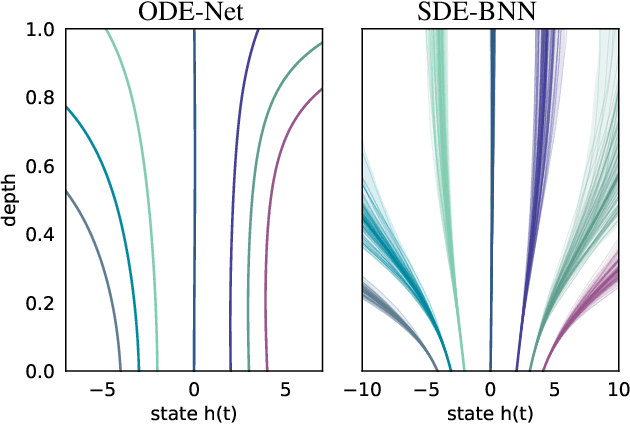
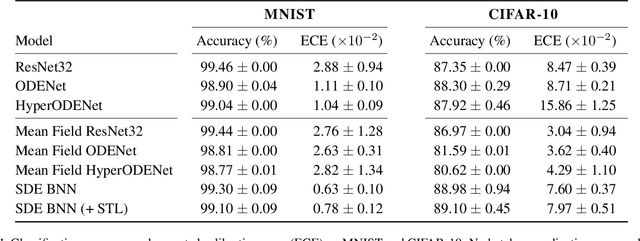
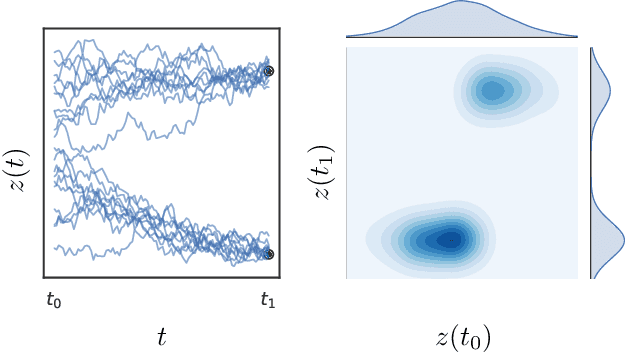
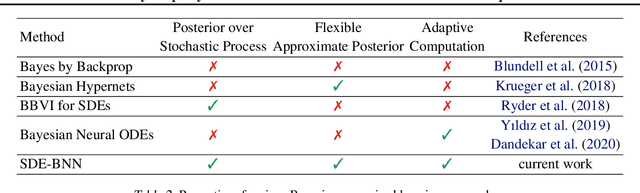
We perform scalable approximate inference in a recently-proposed family of continuous-depth Bayesian neural networks. In this model class, uncertainty about separate weights in each layer produces dynamics that follow a stochastic differential equation (SDE). We demonstrate gradient-based stochastic variational inference in this infinite-parameter setting, producing arbitrarily-flexible approximate posteriors. We also derive a novel gradient estimator that approaches zero variance as the approximate posterior approaches the true posterior. This approach further inherits the memory-efficient training and tunable precision of neural ODEs.
Oops I Took A Gradient: Scalable Sampling for Discrete Distributions
Feb 08, 2021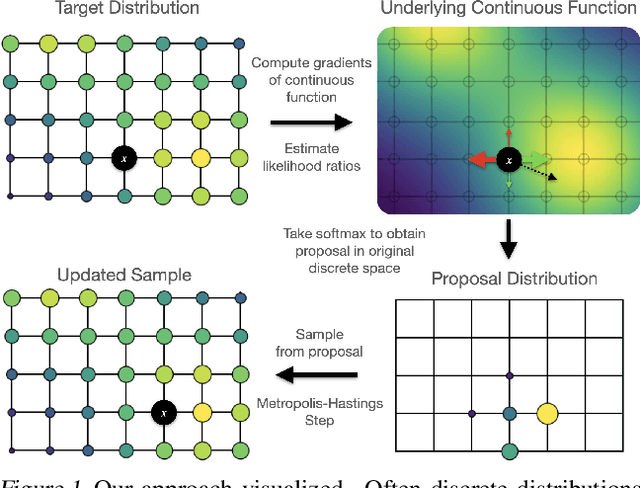

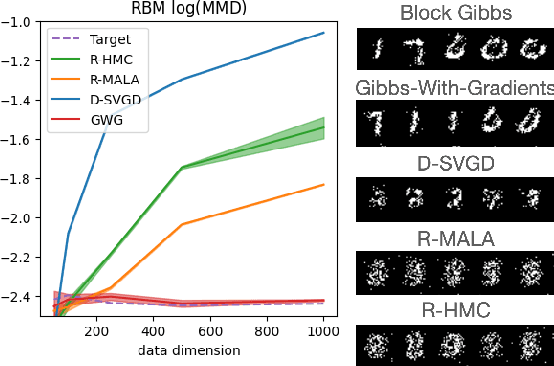
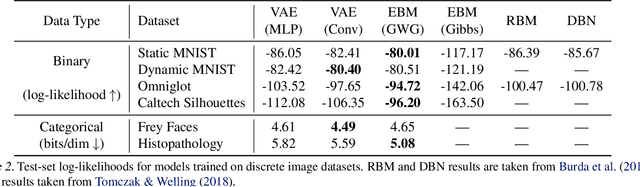
We propose a general and scalable approximate sampling strategy for probabilistic models with discrete variables. Our approach uses gradients of the likelihood function with respect to its discrete inputs to propose updates in a Metropolis-Hastings sampler. We show empirically that this approach outperforms generic samplers in a number of difficult settings including Ising models, Potts models, restricted Boltzmann machines, and factorial hidden Markov models. We also demonstrate the use of our improved sampler for training deep energy-based models on high dimensional discrete data. This approach outperforms variational auto-encoders and existing energy-based models. Finally, we give bounds showing that our approach is near-optimal in the class of samplers which propose local updates.
Self-Tuning Stochastic Optimization with Curvature-Aware Gradient Filtering
Nov 09, 2020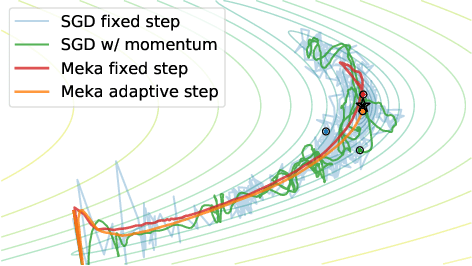
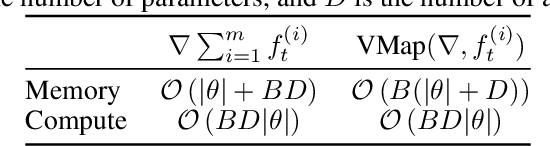
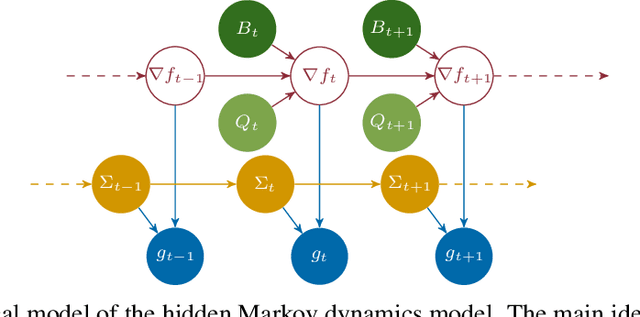

Standard first-order stochastic optimization algorithms base their updates solely on the average mini-batch gradient, and it has been shown that tracking additional quantities such as the curvature can help de-sensitize common hyperparameters. Based on this intuition, we explore the use of exact per-sample Hessian-vector products and gradients to construct optimizers that are self-tuning and hyperparameter-free. Based on a dynamics model of the gradient, we derive a process which leads to a curvature-corrected, noise-adaptive online gradient estimate. The smoothness of our updates makes it more amenable to simple step size selection schemes, which we also base off of our estimates quantities. We prove that our model-based procedure converges in the noisy quadratic setting. Though we do not see similar gains in deep learning tasks, we can match the performance of well-tuned optimizers and ultimately, this is an interesting step for constructing self-tuning optimizers.
Teaching with Commentaries
Nov 05, 2020
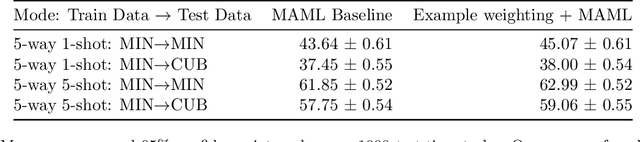
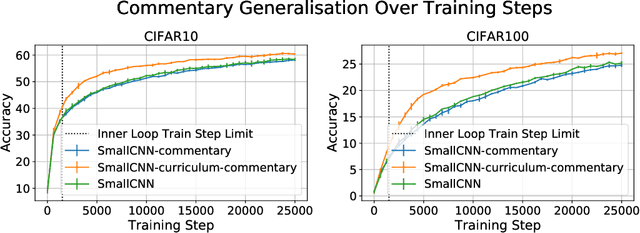

Effective training of deep neural networks can be challenging, and there remain many open questions on how to best learn these models. Recently developed methods to improve neural network training examine teaching: providing learned information during the training process to improve downstream model performance. In this paper, we take steps towards extending the scope of teaching. We propose a flexible teaching framework using commentaries, meta-learned information helpful for training on a particular task or dataset. We present an efficient and scalable gradient-based method to learn commentaries, leveraging recent work on implicit differentiation. We explore diverse applications of commentaries, from learning weights for individual training examples, to parameterizing label-dependent data augmentation policies, to representing attention masks that highlight salient image regions. In these settings, we find that commentaries can improve training speed and/or performance and also provide fundamental insights about the dataset and training process.
No MCMC for me: Amortized sampling for fast and stable training of energy-based models
Oct 14, 2020
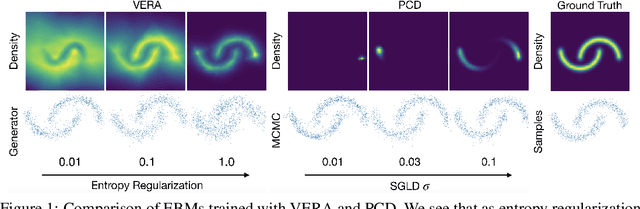


Energy-Based Models (EBMs) present a flexible and appealing way to represent uncertainty. Despite recent advances, training EBMs on high-dimensional data remains a challenging problem as the state-of-the-art approaches are costly, unstable, and require considerable tuning and domain expertise to apply successfully. In this work, we present a simple method for training EBMs at scale which uses an entropy-regularized generator to amortize the MCMC sampling typically used in EBM training. We improve upon prior MCMC-based entropy regularization methods with a fast variational approximation. We demonstrate the effectiveness of our approach by using it to train tractable likelihood models. Next, we apply our estimator to the recently proposed Joint Energy Model (JEM), where we match the original performance with faster and stable training. This allows us to extend JEM models to semi-supervised classification on tabular data from a variety of continuous domains.
A Study of Gradient Variance in Deep Learning
Jul 09, 2020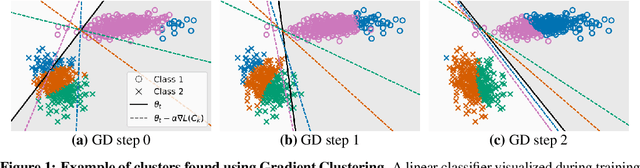


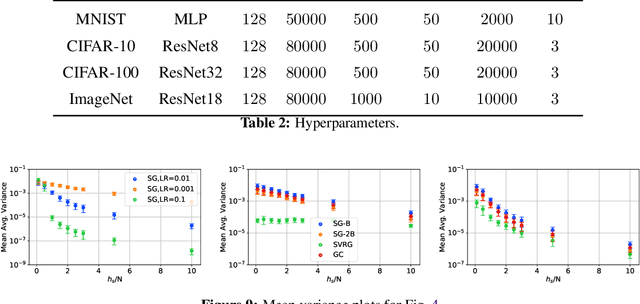
The impact of gradient noise on training deep models is widely acknowledged but not well understood. In this context, we study the distribution of gradients during training. We introduce a method, Gradient Clustering, to minimize the variance of average mini-batch gradient with stratified sampling. We prove that the variance of average mini-batch gradient is minimized if the elements are sampled from a weighted clustering in the gradient space. We measure the gradient variance on common deep learning benchmarks and observe that, contrary to common assumptions, gradient variance increases during training, and smaller learning rates coincide with higher variance. In addition, we introduce normalized gradient variance as a statistic that better correlates with the speed of convergence compared to gradient variance.