 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Neural Local Lossless Compression
Jan 23, 2022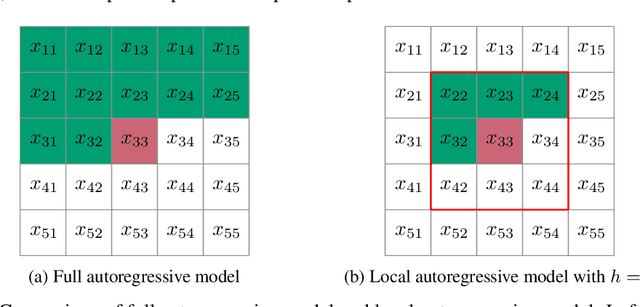
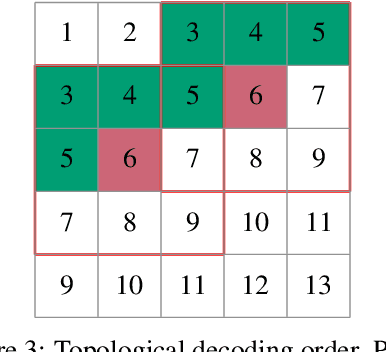

The recently proposed Neural Local Lossless Compression (NeLLoC), which is based on a local autoregressive model, has achieved state-of-the-art (SOTA) out-of-distribution (OOD) generalization performance in the image compression task. In addition to the encouragement of OOD generalization, the local model also allows parallel inference in the decoding stage. In this paper, we propose a parallelization scheme for local autoregressive models. We discuss the practicalities of implementing this scheme, and provide experimental evidence of significant gains in compression runtime compared to the previous, non-parallel implementation.
Adaptive Optimization with Examplewise Gradients
Nov 30, 2021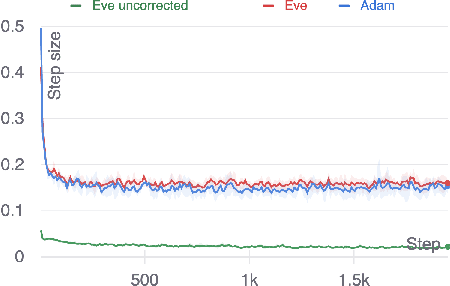

We propose a new, more general approach to the design of stochastic gradient-based optimization methods for machine learning. In this new framework, optimizers assume access to a batch of gradient estimates per iteration, rather than a single estimate. This better reflects the information that is actually available in typical machine learning setups. To demonstrate the usefulness of this generalized approach, we develop Eve, an adaptation of the Adam optimizer which uses examplewise gradients to obtain more accurate second-moment estimates. We provide preliminary experiments, without hyperparameter tuning, which show that the new optimizer slightly outperforms Adam on a small scale benchmark and performs the same or worse on larger scale benchmarks. Further work is needed to refine the algorithm and tune hyperparameters.
Sample Efficient Model Evaluation
Sep 24, 2021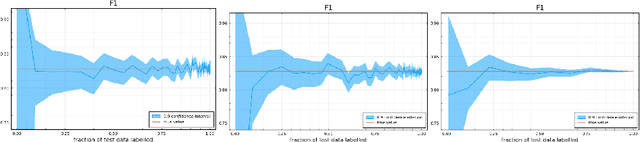
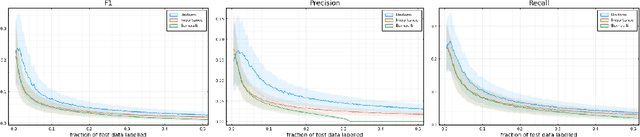
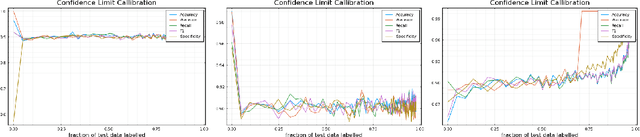
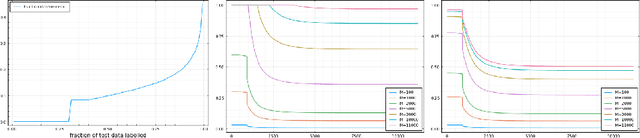
Labelling data is a major practical bottleneck in training and testing classifiers. Given a collection of unlabelled data points, we address how to select which subset to label to best estimate test metrics such as accuracy, $F_1$ score or micro/macro $F_1$. We consider two sampling based approaches, namely the well-known Importance Sampling and we introduce a novel application of Poisson Sampling. For both approaches we derive the minimal error sampling distributions and how to approximate and use them to form estimators and confidence intervals. We show that Poisson Sampling outperforms Importance Sampling both theoretically and experimentally.
Locally-Contextual Nonlinear CRFs for Sequence Labeling
Mar 30, 2021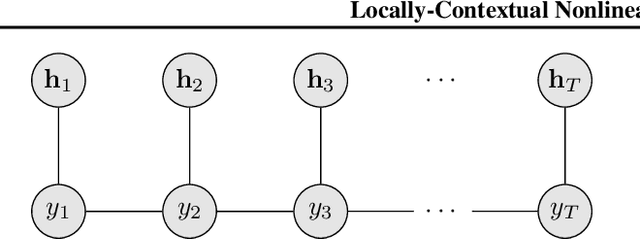

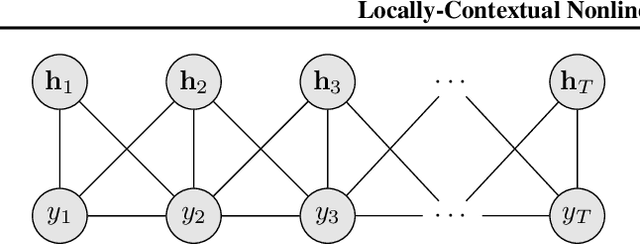
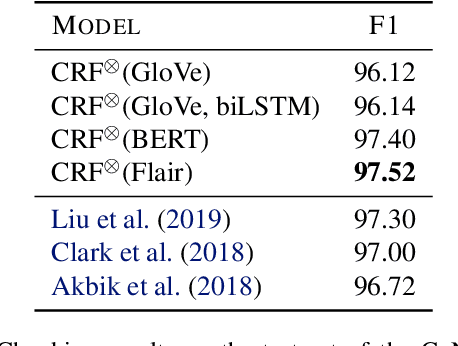
Linear chain conditional random fields (CRFs) combined with contextual word embeddings have achieved state of the art performance on sequence labeling tasks. In many of these tasks, the identity of the neighboring words is often the most useful contextual information when predicting the label of a given word. However, contextual embeddings are usually trained in a task-agnostic manner. This means that although they may encode information about the neighboring words, it is not guaranteed. It can therefore be beneficial to design the sequence labeling architecture to directly extract this information from the embeddings. We propose locally-contextual nonlinear CRFs for sequence labeling. Our approach directly incorporates information from the neighboring embeddings when predicting the label for a given word, and parametrizes the potential functions using deep neural networks. Our model serves as a drop-in replacement for the linear chain CRF, consistently outperforming it in our ablation study. On a variety of tasks, our results are competitive with those of the best published methods. In particular, we outperform the previous state of the art on chunking on CoNLL 2000 and named entity recognition on OntoNotes 5.0 English.
Reducing the Computational Cost of Deep Generative Models with Binary Neural Networks
Oct 26, 2020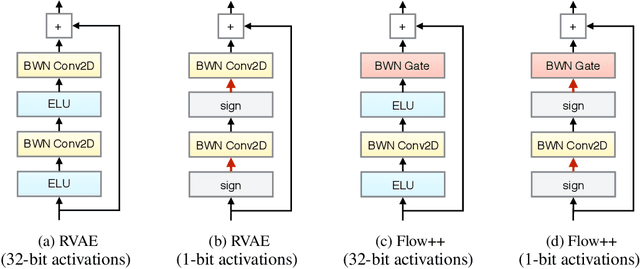

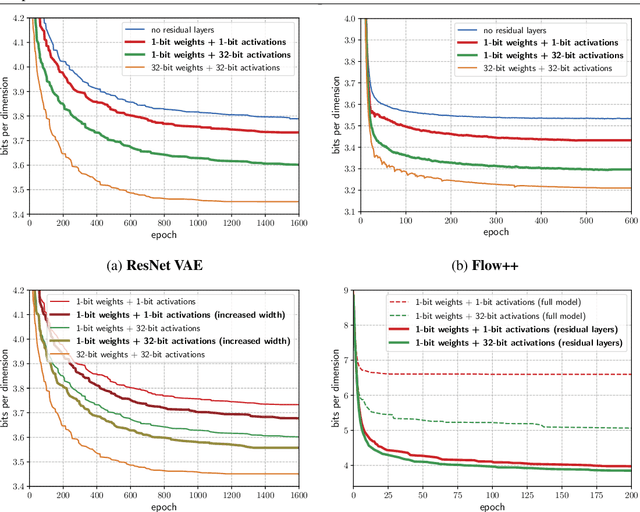

Deep generative models provide a powerful set of tools to understand real-world data. But as these models improve, they increase in size and complexity, so their computational cost in memory and execution time grows. Using binary weights in neural networks is one method which has shown promise in reducing this cost. However, whether binary neural networks can be used in generative models is an open problem. In this work we show, for the first time, that we can successfully train generative models which utilize binary neural networks. This reduces the computational cost of the models massively. We develop a new class of binary weight normalization, and provide insights for architecture designs of these binarized generative models. We demonstrate that two state-of-the-art deep generative models, the ResNet VAE and Flow++ models, can be binarized effectively using these techniques. We train binary models that achieve loss values close to those of the regular models but are 90%-94% smaller in size, and also allow significant speed-ups in execution time.
Learning to Noise: Application-Agnostic Data Sharing with Local Differential Privacy
Oct 23, 2020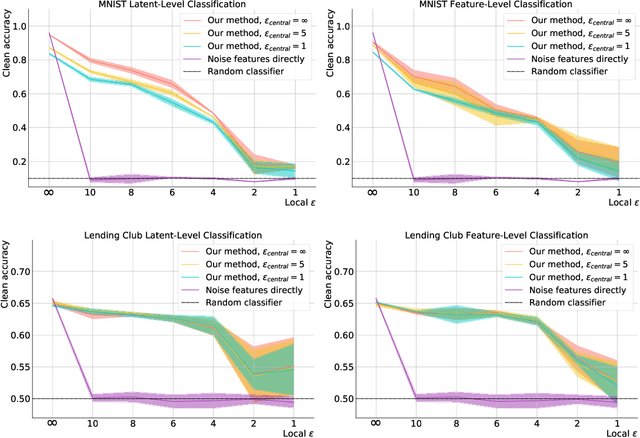
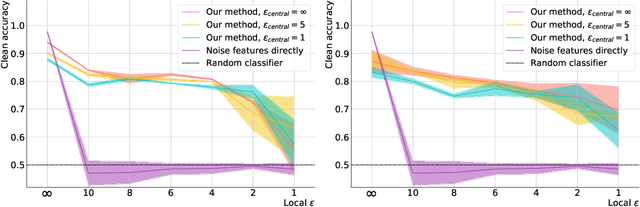
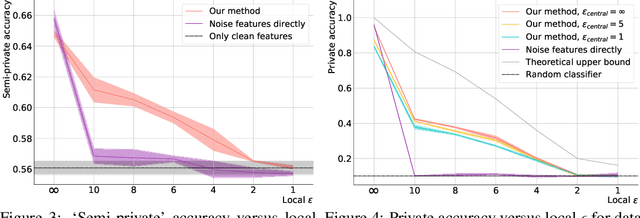
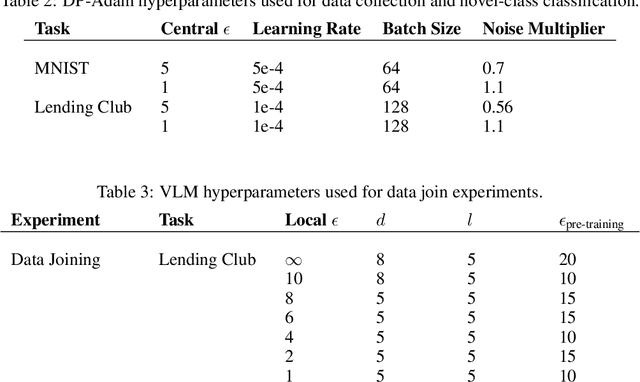
In recent years, the collection and sharing of individuals' private data has become commonplace in many industries. Local differential privacy (LDP) is a rigorous approach which uses a randomized algorithm to preserve privacy even from the database administrator, unlike the more standard central differential privacy. For LDP, when applying noise directly to high-dimensional data, the level of noise required all but entirely destroys data utility. In this paper we introduce a novel, application-agnostic privatization mechanism that leverages representation learning to overcome the prohibitive noise requirements of direct methods, while maintaining the strict guarantees of LDP. We further demonstrate that this privatization mechanism can be used to train machine learning algorithms across a range of applications, including private data collection, private novel-class classification, and the augmentation of clean datasets with additional privatized features. We achieve significant gains in performance on downstream classification tasks relative to benchmarks that noise the data directly, which are state-of-the-art in the context of application-agnostic LDP mechanisms for high-dimensional data.
Learning Deep-Latent Hierarchies by Stacking Wasserstein Autoencoders
Oct 07, 2020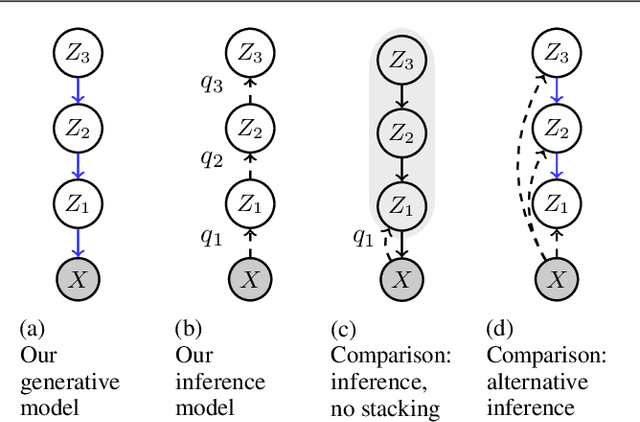



Probabilistic models with hierarchical-latent-variable structures provide state-of-the-art results amongst non-autoregressive, unsupervised density-based models. However, the most common approach to training such models based on Variational Autoencoders (VAEs) often fails to leverage deep-latent hierarchies; successful approaches require complex inference and optimisation schemes. Optimal Transport is an alternative, non-likelihood-based framework for training generative models with appealing theoretical properties, in principle allowing easier training convergence between distributions. In this work we propose a novel approach to training models with deep-latent hierarchies based on Optimal Transport, without the need for highly bespoke models and inference networks. We show that our method enables the generative model to fully leverage its deep-latent hierarchy, avoiding the well known "latent variable collapse" issue of VAEs; therefore, providing qualitatively better sample generations as well as more interpretable latent representation than the original Wasserstein Autoencoder with Maximum Mean Discrepancy divergence.
Learning disentangled representations with the Wasserstein Autoencoder
Oct 07, 2020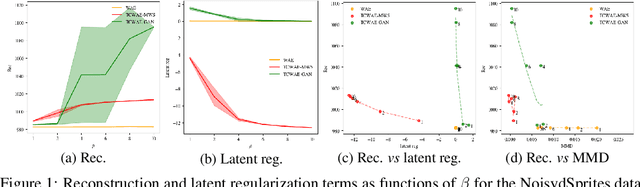
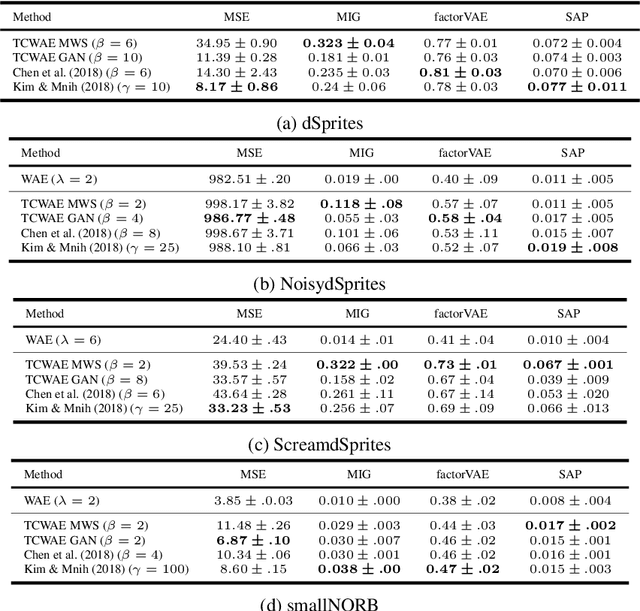

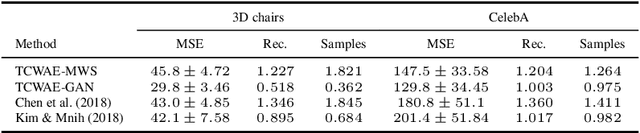
Disentangled representation learning has undoubtedly benefited from objective function surgery. However, a delicate balancing act of tuning is still required in order to trade off reconstruction fidelity versus disentanglement. Building on previous successes of penalizing the total correlation in the latent variables, we propose TCWAE (Total Correlation Wasserstein Autoencoder). Working in the WAE paradigm naturally enables the separation of the total-correlation term, thus providing disentanglement control over the learned representation, while offering more flexibility in the choice of reconstruction cost. We propose two variants using different KL estimators and perform extensive quantitative comparisons on data sets with known generative factors, showing competitive results relative to state-of-the-art techniques. We further study the trade off between disentanglement and reconstruction on more-difficult data sets with unknown generative factors, where the flexibility of the WAE paradigm in the reconstruction term improves reconstructions.
Bayesian Online Meta-Learning with Laplace Approximation
Apr 30, 2020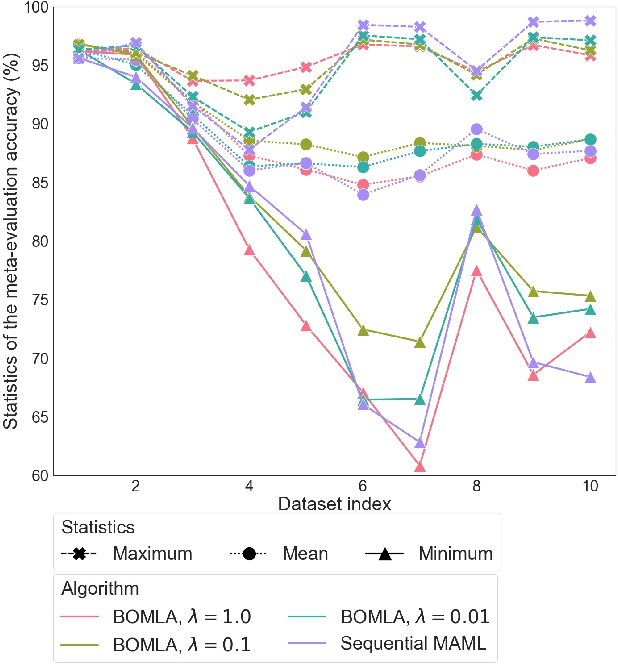

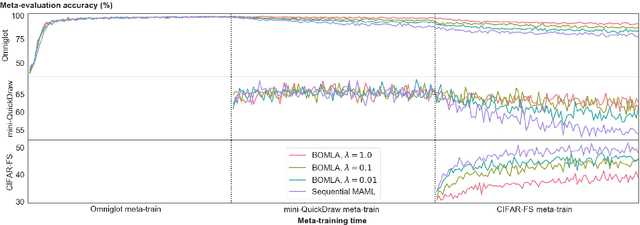
Neural networks are known to suffer from catastrophic forgetting when trained on sequential datasets. While there have been numerous attempts to solve this problem for large-scale supervised classification, little has been done to overcome catastrophic forgetting for few-shot classification problems. We demonstrate that the popular gradient-based few-shot meta-learning algorithm Model-Agnostic Meta-Learning (MAML) indeed suffers from catastrophic forgetting and introduce a Bayesian online meta-learning framework that tackles this problem. Our framework incorporates MAML into a Bayesian online learning algorithm with Laplace approximation. This framework enables few-shot classification on a range of sequentially arriving datasets with a single meta-learned model. The experimental evaluations demonstrate that our framework can effectively prevent forgetting in various few-shot classification settings compared to applying MAML sequentially.
Private Machine Learning via Randomised Response
Feb 24, 2020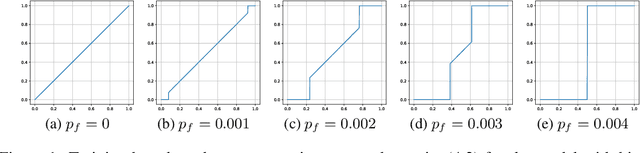

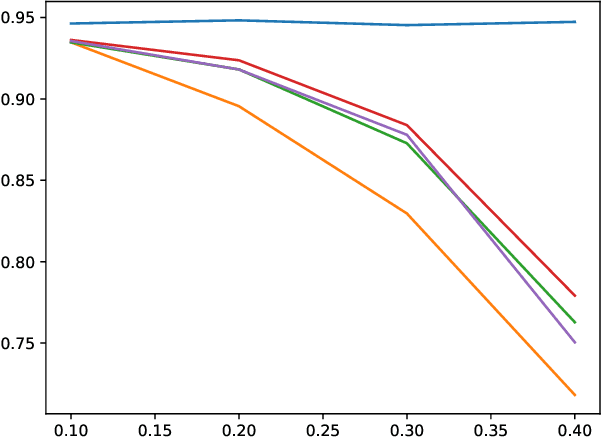

We introduce a general learning framework for private machine learning based on randomised response. Our assumption is that all actors are potentially adversarial and as such we trust only to release a single noisy version of an individual's datapoint. We discuss a general approach that forms a consistent way to estimate the true underlying machine learning model and demonstrate this in the case of logistic regression.