 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-evaluating Evaluation
Oct 30, 2018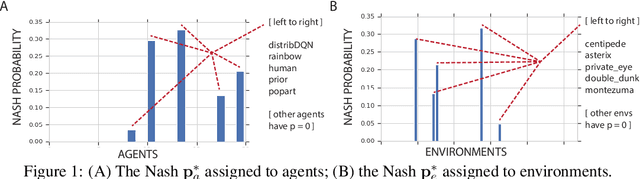
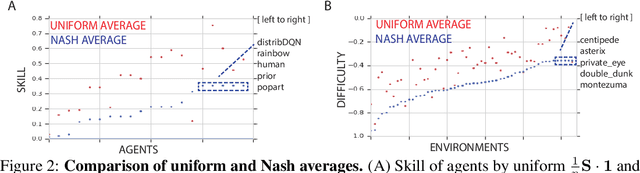
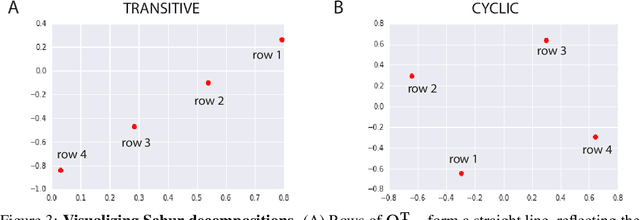
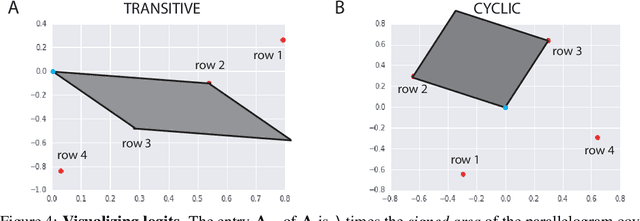
Progress in machine learning is measured by careful evaluation on problems of outstanding common interest. However, the proliferation of benchmark suites and environments, adversarial attacks, and other complications has diluted the basic evaluation model by overwhelming researchers with choices. Deliberate or accidental cherry picking is increasingly likely, and designing well-balanced evaluation suites requires increasing effort. In this paper we take a step back and propose Nash averaging. The approach builds on a detailed analysis of the algebraic structure of evaluation in two basic scenarios: agent-vs-agent and agent-vs-task. The key strength of Nash averaging is that it automatically adapts to redundancies in evaluation data, so that results are not biased by the incorporation of easy tasks or weak agents. Nash averaging thus encourages maximally inclusive evaluation -- since there is no harm (computational cost aside) from including all available tasks and agents.
The Mechanics of n-Player Differentiable Games
Jun 06, 2018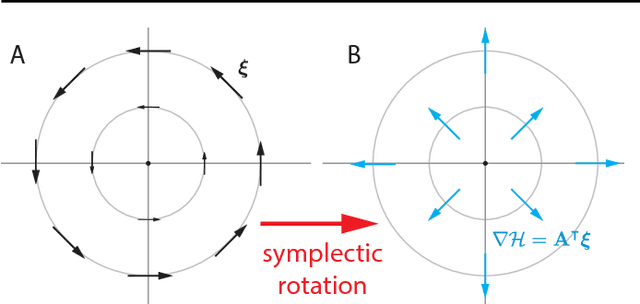
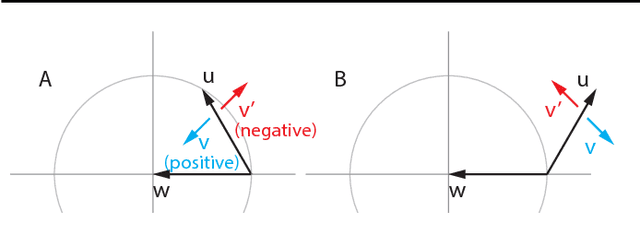
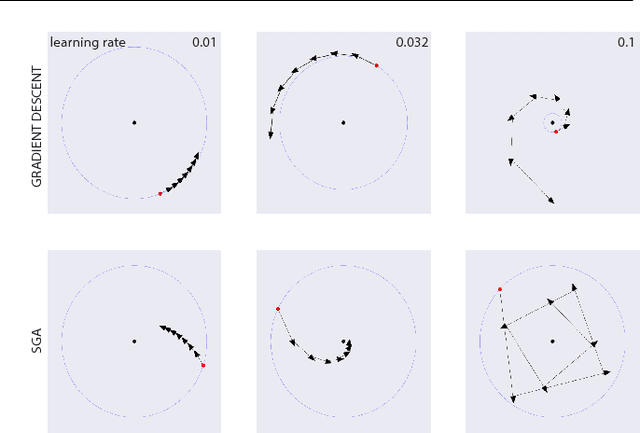
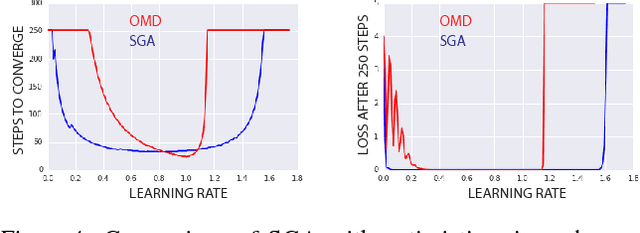
The cornerstone underpinning deep learning is the guarantee that gradient descent on an objective converges to local minima. Unfortunately, this guarantee fails in settings, such as generative adversarial nets, where there are multiple interacting losses. The behavior of gradient-based methods in games is not well understood -- and is becoming increasingly important as adversarial and multi-objective architectures proliferate. In this paper, we develop new techniques to understand and control the dynamics in general games. The key result is to decompose the second-order dynamics into two components. The first is related to potential games, which reduce to gradient descent on an implicit function; the second relates to Hamiltonian games, a new class of games that obey a conservation law, akin to conservation laws in classical mechanical systems. The decomposition motivates Symplectic Gradient Adjustment (SGA), a new algorithm for finding stable fixed points in general games. Basic experiments show SGA is competitive with recently proposed algorithms for finding stable fixed points in GANs -- whilst at the same time being applicable to -- and having guarantees in -- much more general games.
* ICML 2018, final version
Neural Taylor Approximations: Convergence and Exploration in Rectifier Networks
Jun 06, 2018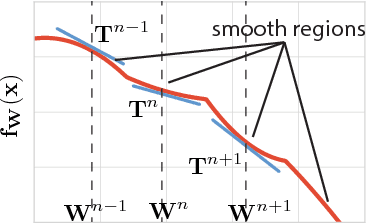
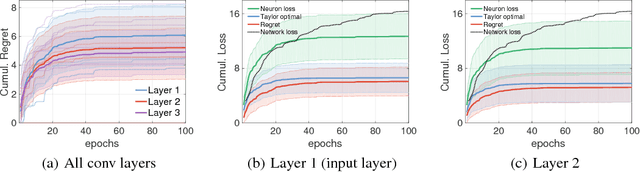
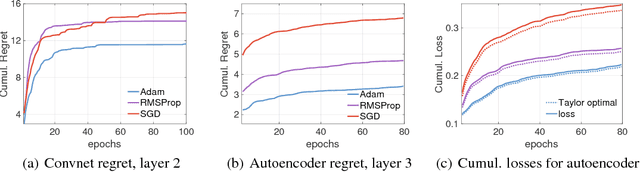
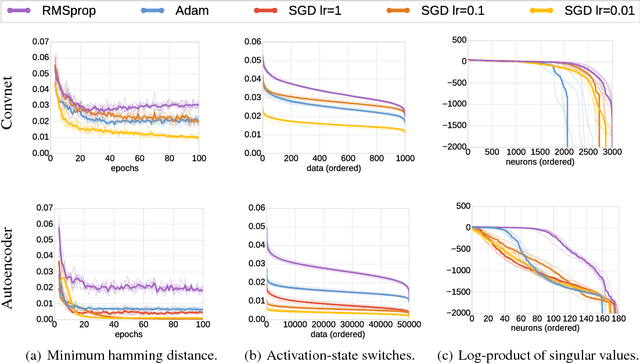
Modern convolutional networks, incorporating rectifiers and max-pooling, are neither smooth nor convex; standard guarantees therefore do not apply. Nevertheless, methods from convex optimization such as gradient descent and Adam are widely used as building blocks for deep learning algorithms. This paper provides the first convergence guarantee applicable to modern convnets, which furthermore matches a lower bound for convex nonsmooth functions. The key technical tool is the neural Taylor approximation -- a straightforward application of Taylor expansions to neural networks -- and the associated Taylor loss. Experiments on a range of optimizers, layers, and tasks provide evidence that the analysis accurately captures the dynamics of neural optimization. The second half of the paper applies the Taylor approximation to isolate the main difficulty in training rectifier nets -- that gradients are shattered -- and investigates the hypothesis that, by exploring the space of activation configurations more thoroughly, adaptive optimizers such as RMSProp and Adam are able to converge to better solutions.
* ICML 2017, final version
Strongly-Typed Agents are Guaranteed to Interact Safely
Jun 06, 2018As artificial agents proliferate, it is becoming increasingly important to ensure that their interactions with one another are well-behaved. In this paper, we formalize a common-sense notion of when algorithms are well-behaved: an algorithm is safe if it does no harm. Motivated by recent progress in deep learning, we focus on the specific case where agents update their actions according to gradient descent. The paper shows that that gradient descent converges to a Nash equilibrium in safe games. The main contribution is to define strongly-typed agents and show they are guaranteed to interact safely, thereby providing sufficient conditions to guarantee safe interactions. A series of examples show that strong-typing generalizes certain key features of convexity, is closely related to blind source separation, and introduces a new perspective on classical multilinear games based on tensor decomposition.
* ICML 2017, final version
The Shattered Gradients Problem: If resnets are the answer, then what is the question?
Jun 06, 2018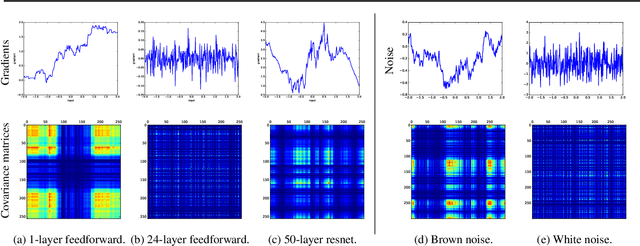
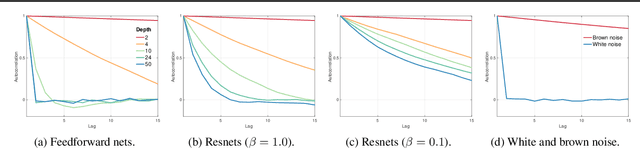
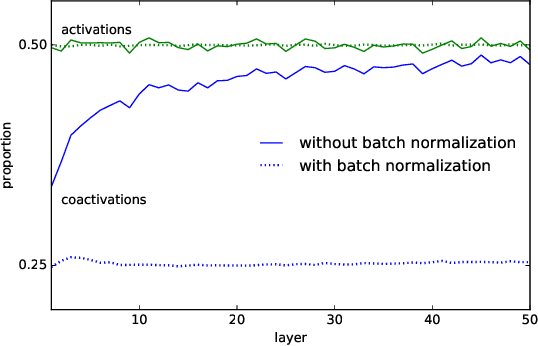
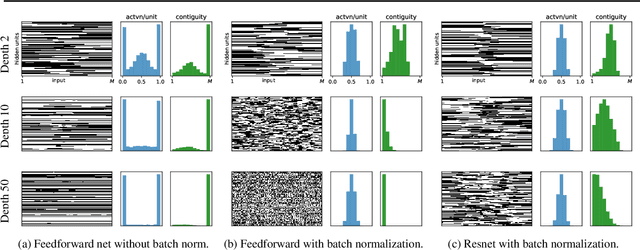
A long-standing obstacle to progress in deep learning is the problem of vanishing and exploding gradients. Although, the problem has largely been overcome via carefully constructed initializations and batch normalization, architectures incorporating skip-connections such as highway and resnets perform much better than standard feedforward architectures despite well-chosen initialization and batch normalization. In this paper, we identify the shattered gradients problem. Specifically, we show that the correlation between gradients in standard feedforward networks decays exponentially with depth resulting in gradients that resemble white noise whereas, in contrast, the gradients in architectures with skip-connections are far more resistant to shattering, decaying sublinearly. Detailed empirical evidence is presented in support of the analysis, on both fully-connected networks and convnets. Finally, we present a new "looks linear" (LL) initialization that prevents shattering, with preliminary experiments showing the new initialization allows to train very deep networks without the addition of skip-connections.
* ICML 2017, final version
Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation
Aug 01, 2016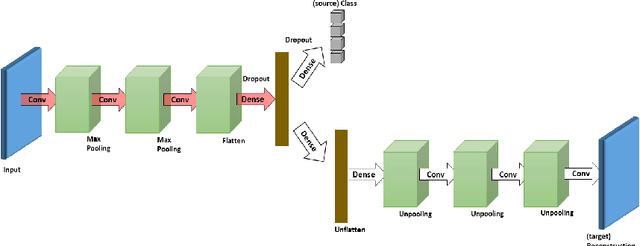
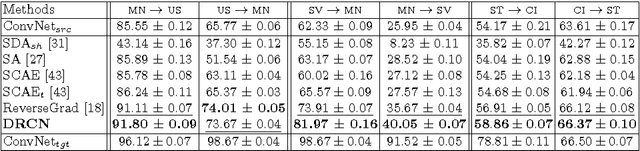


In this paper, we propose a novel unsupervised domain adaptation algorithm based on deep learning for visual object recognition. Specifically, we design a new model called Deep Reconstruction-Classification Network (DRCN), which jointly learns a shared encoding representation for two tasks: i) supervised classification of labeled source data, and ii) unsupervised reconstruction of unlabeled target data.In this way, the learnt representation not only preserves discriminability, but also encodes useful information from the target domain. Our new DRCN model can be optimized by using backpropagation similarly as the standard neural networks. We evaluate the performance of DRCN on a series of cross-domain object recognition tasks, where DRCN provides a considerable improvement (up to ~8% in accuracy) over the prior state-of-the-art algorithms. Interestingly, we also observe that the reconstruction pipeline of DRCN transforms images from the source domain into images whose appearance resembles the target dataset. This suggests that DRCN's performance is due to constructing a single composite representation that encodes information about both the structure of target images and the classification of source images. Finally, we provide a formal analysis to justify the algorithm's objective in domain adaptation context.
Scatter Component Analysis: A Unified Framework for Domain Adaptation and Domain Generalization
Jul 26, 2016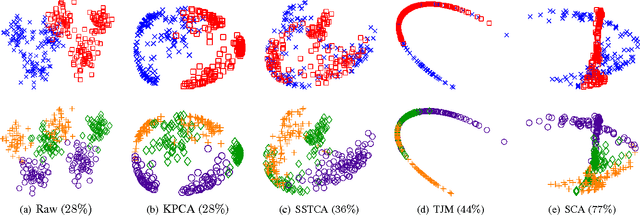

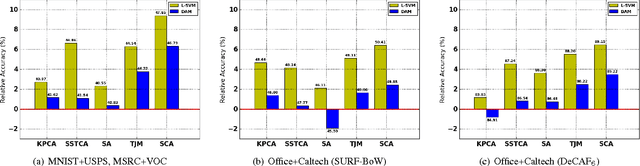
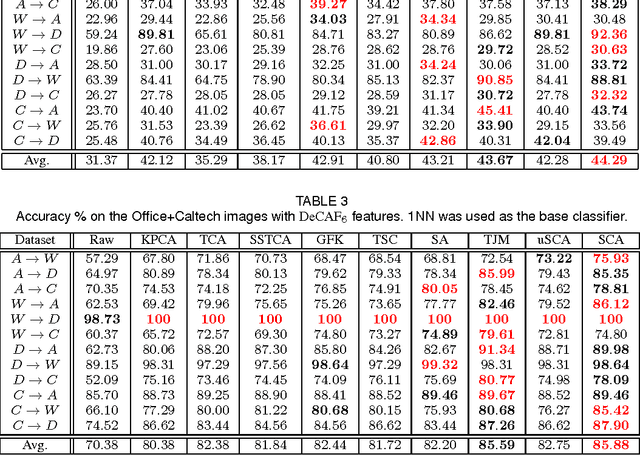
This paper addresses classification tasks on a particular target domain in which labeled training data are only available from source domains different from (but related to) the target. Two closely related frameworks, domain adaptation and domain generalization, are concerned with such tasks, where the only difference between those frameworks is the availability of the unlabeled target data: domain adaptation can leverage unlabeled target information, while domain generalization cannot. We propose Scatter Component Analyis (SCA), a fast representation learning algorithm that can be applied to both domain adaptation and domain generalization. SCA is based on a simple geometrical measure, i.e., scatter, which operates on reproducing kernel Hilbert space. SCA finds a representation that trades between maximizing the separability of classes, minimizing the mismatch between domains, and maximizing the separability of data; each of which is quantified through scatter. The optimization problem of SCA can be reduced to a generalized eigenvalue problem, which results in a fast and exact solution. Comprehensive experiments on benchmark cross-domain object recognition datasets verify that SCA performs much faster than several state-of-the-art algorithms and also provides state-of-the-art classification accuracy in both domain adaptation and domain generalization. We also show that scatter can be used to establish a theoretical generalization bound in the case of domain adaptation.
Strongly-Typed Recurrent Neural Networks
May 24, 2016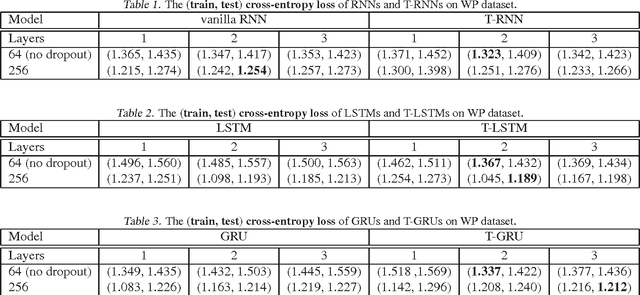
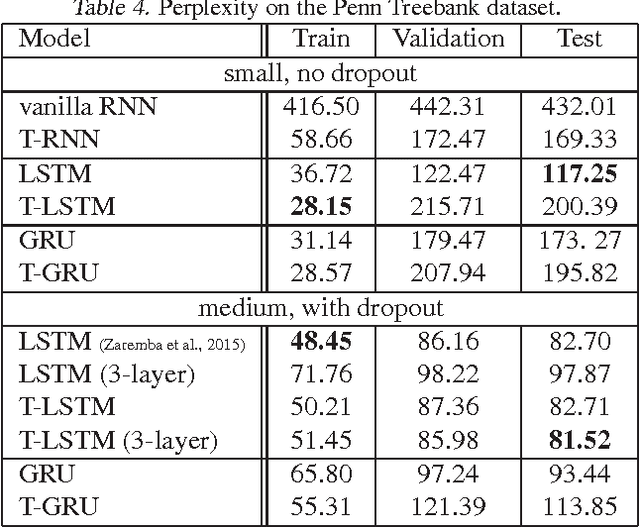
Recurrent neural networks are increasing popular models for sequential learning. Unfortunately, although the most effective RNN architectures are perhaps excessively complicated, extensive searches have not found simpler alternatives. This paper imports ideas from physics and functional programming into RNN design to provide guiding principles. From physics, we introduce type constraints, analogous to the constraints that forbids adding meters to seconds. From functional programming, we require that strongly-typed architectures factorize into stateless learnware and state-dependent firmware, reducing the impact of side-effects. The features learned by strongly-typed nets have a simple semantic interpretation via dynamic average-pooling on one-dimensional convolutions. We also show that strongly-typed gradients are better behaved than in classical architectures, and characterize the representational power of strongly-typed nets. Finally, experiments show that, despite being more constrained, strongly-typed architectures achieve lower training and comparable generalization error to classical architectures.
Deep Online Convex Optimization by Putting Forecaster to Sleep
Apr 08, 2016Methods from convex optimization such as accelerated gradient descent are widely used as building blocks for deep learning algorithms. However, the reasons for their empirical success are unclear, since neural networks are not convex and standard guarantees do not apply. This paper develops the first rigorous link between online convex optimization and error backpropagation on convolutional networks. The first step is to introduce circadian games, a mild generalization of convex games with similar convergence properties. The main result is that error backpropagation on a convolutional network is equivalent to playing out a circadian game. It follows immediately that the waking-regret of players in the game (the units in the neural network) controls the overall rate of convergence of the network. Finally, we explore some implications of the results: (i) we describe the representations learned by a neural network game-theoretically, (ii) propose a learning setting at the level of individual units that can be plugged into deep architectures, and (iii) propose a new approach to adaptive model selection by applying bandit algorithms to choose which players to wake on each round.
Deep Online Convex Optimization with Gated Games
Apr 07, 2016Methods from convex optimization are widely used as building blocks for deep learning algorithms. However, the reasons for their empirical success are unclear, since modern convolutional networks (convnets), incorporating rectifier units and max-pooling, are neither smooth nor convex. Standard guarantees therefore do not apply. This paper provides the first convergence rates for gradient descent on rectifier convnets. The proof utilizes the particular structure of rectifier networks which consists in binary active/inactive gates applied on top of an underlying linear network. The approach generalizes to max-pooling, dropout and maxout. In other words, to precisely the neural networks that perform best empirically. The key step is to introduce gated games, an extension of convex games with similar convergence properties that capture the gating function of rectifiers. The main result is that rectifier convnets converge to a critical point at a rate controlled by the gated-regret of the units in the network. Corollaries of the main result include: (i) a game-theoretic description of the representations learned by a neural network; (ii) a logarithmic-regret algorithm for training neural nets; and (iii) a formal setting for analyzing conditional computation in neural nets that can be applied to recently developed models of attention.