 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRough Sets for Explainability of Spectral Graph Clustering
Dec 13, 2025Graph Spectral Clustering methods (GSC) allow representing clusters of diverse shapes, densities, etc. However, the results of such algorithms, when applied e.g. to text documents, are hard to explain to the user, especially due to embedding in the spectral space which has no obvious relation to document contents. Furthermore, the presence of documents without clear content meaning and the stochastic nature of the clustering algorithms deteriorate explainability. This paper proposes an enhancement to the explanation methodology, proposed in an earlier research of our team. It allows us to overcome the latter problems by taking inspiration from rough set theory.
NeoN: A Tool for Automated Detection, Linguistic and LLM-Driven Analysis of Neologisms in Polish
May 21, 2025



NeoN, a tool for detecting and analyzing Polish neologisms. Unlike traditional dictionary-based methods requiring extensive manual review, NeoN combines reference corpora, Polish-specific linguistic filters, an LLM-driven precision-boosting filter, and daily RSS monitoring in a multi-layered pipeline. The system uses context-aware lemmatization, frequency analysis, and orthographic normalization to extract candidate neologisms while consolidating inflectional variants. Researchers can verify candidates through an intuitive interface with visualizations and filtering controls. An integrated LLM module automatically generates definitions and categorizes neologisms by domain and sentiment. Evaluations show NeoN maintains high accuracy while significantly reducing manual effort, providing an accessible solution for tracking lexical innovation in Polish.
A Method for Handling Negative Similarities in Explainable Graph Spectral Clustering of Text Documents -- Extended Version
Apr 16, 2025



This paper investigates the problem of Graph Spectral Clustering with negative similarities, resulting from document embeddings different from the traditional Term Vector Space (like doc2vec, GloVe, etc.). Solutions for combinatorial Laplacians and normalized Laplacians are discussed. An experimental investigation shows the advantages and disadvantages of 6 different solutions proposed in the literature and in this research. The research demonstrates that GloVe embeddings frequently cause failures of normalized Laplacian based GSC due to negative similarities. Furthermore, application of methods curing similarity negativity leads to accuracy improvement for both combinatorial and normalized Laplacian based GSC. It also leads to applicability for GloVe embeddings of explanation methods developed originally bythe authors for Term Vector Space embeddings.
Grammatical Case Based IS-A Relation Extraction with Boosting for Polish
May 10, 2016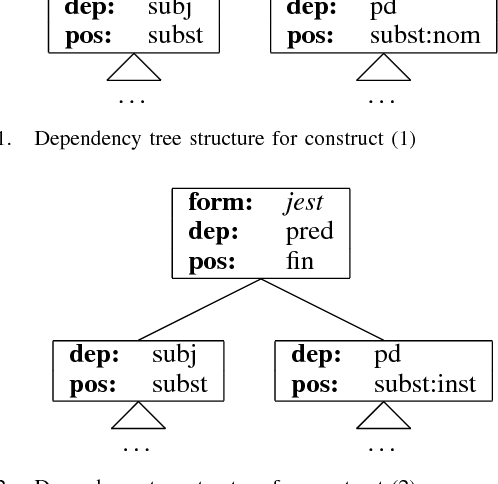
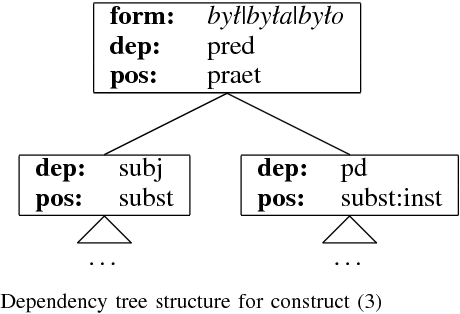

Pattern-based methods of IS-A relation extraction rely heavily on so called Hearst patterns. These are ways of expressing instance enumerations of a class in natural language. While these lexico-syntactic patterns prove quite useful, they may not capture all taxonomical relations expressed in text. Therefore in this paper we describe a novel method of IS-A relation extraction from patterns, which uses morpho-syntactical annotations along with grammatical case of noun phrases that constitute entities participating in IS-A relation. We also describe a method for increasing the number of extracted relations that we call pseudo-subclass boosting which has potential application in any pattern-based relation extraction method. Experiments were conducted on a corpus of about 0.5 billion web documents in Polish language.