 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRough Sets for Explainability of Spectral Graph Clustering
Dec 13, 2025Graph Spectral Clustering methods (GSC) allow representing clusters of diverse shapes, densities, etc. However, the results of such algorithms, when applied e.g. to text documents, are hard to explain to the user, especially due to embedding in the spectral space which has no obvious relation to document contents. Furthermore, the presence of documents without clear content meaning and the stochastic nature of the clustering algorithms deteriorate explainability. This paper proposes an enhancement to the explanation methodology, proposed in an earlier research of our team. It allows us to overcome the latter problems by taking inspiration from rough set theory.
A Method for Handling Negative Similarities in Explainable Graph Spectral Clustering of Text Documents -- Extended Version
Apr 16, 2025



This paper investigates the problem of Graph Spectral Clustering with negative similarities, resulting from document embeddings different from the traditional Term Vector Space (like doc2vec, GloVe, etc.). Solutions for combinatorial Laplacians and normalized Laplacians are discussed. An experimental investigation shows the advantages and disadvantages of 6 different solutions proposed in the literature and in this research. The research demonstrates that GloVe embeddings frequently cause failures of normalized Laplacian based GSC due to negative similarities. Furthermore, application of methods curing similarity negativity leads to accuracy improvement for both combinatorial and normalized Laplacian based GSC. It also leads to applicability for GloVe embeddings of explanation methods developed originally bythe authors for Term Vector Space embeddings.
Explainable Graph Spectral Clustering of Text Documents
Aug 01, 2023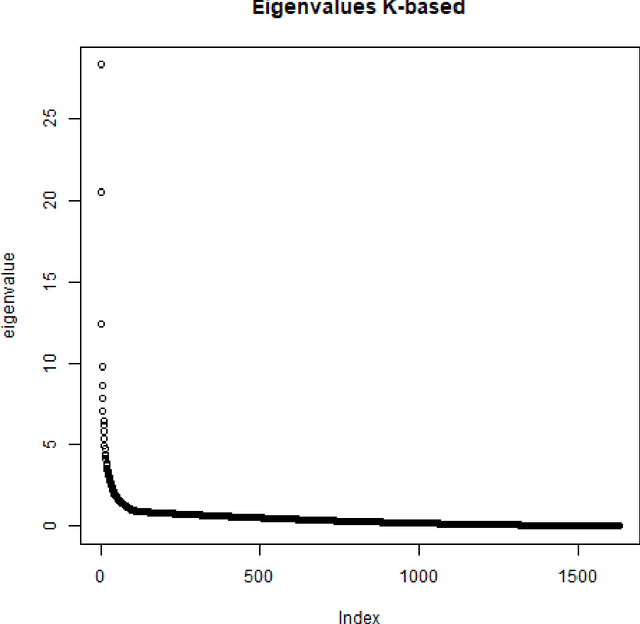
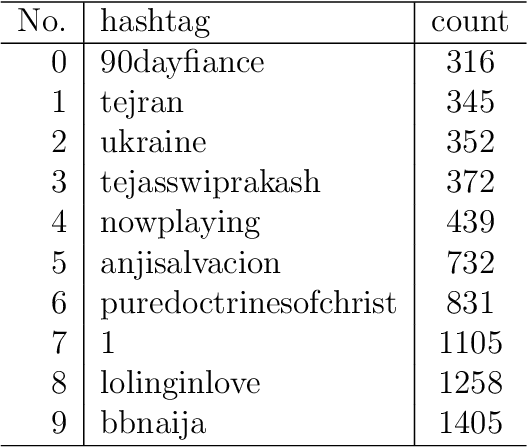
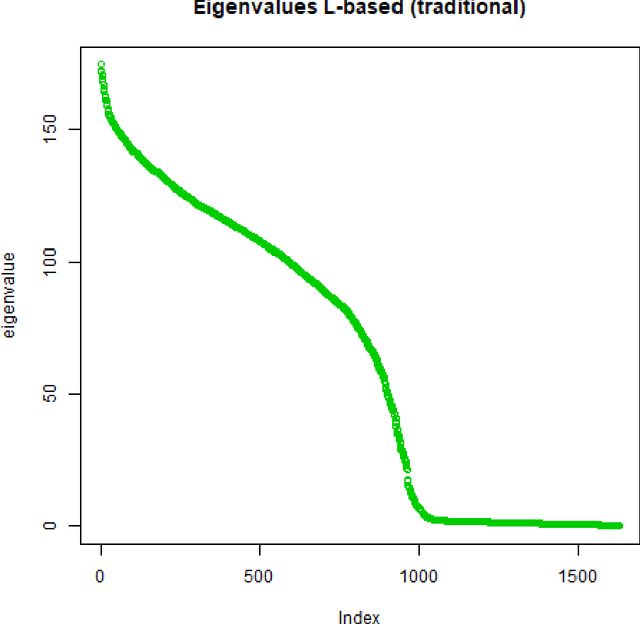
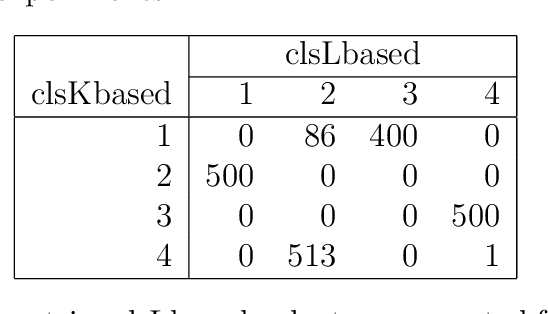
Spectral clustering methods are known for their ability to represent clusters of diverse shapes, densities etc. However, results of such algorithms, when applied e.g. to text documents, are hard to explain to the user, especially due to embedding in the spectral space which has no obvious relation to document contents. Therefore there is an urgent need to elaborate methods for explaining the outcome of the clustering. This paper presents a contribution towards this goal. We present a proposal of explanation of results of combinatorial Laplacian based graph spectral clustering. It is based on showing (approximate) equivalence of combinatorial Laplacian embedding, $K$-embedding (proposed in this paper) and term vector space embedding. Hence a bridge is constructed between the textual contents and the clustering results. We provide theoretical background for this approach. We performed experimental study showing that $K$-embedding approximates well Laplacian embedding under favourable block matrix conditions and show that approximation is good enough under other conditions.