 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Drawing Identification Complexity is Invariant to Modality in Vision-Language Models
May 14, 2025Large language models have become multimodal, and many of them are said to integrate their modalities using common representations. If this were true, a drawing of a car as an image, for instance, should map to the similar area in the latent space as a textual description of the strokes that conform the drawing. To explore this in a black-box access regime to these models, we propose the use of machine teaching, a theory that studies the minimal set of examples a teacher needs to choose so that the learner captures the concept. In this paper we evaluate the complexity of teaching visual-language models a subset of objects in the Quick, Draw! dataset using two presentations: raw images as bitmaps and trace coordinates in TikZ format. The results indicate that image-based representations generally require fewer segments and achieve higher accuracy than coordinate-based representations. But, surprisingly, the teaching size usually ranks concepts similarly across both modalities, even when controlling for (a human proxy of) concept priors, suggesting that the simplicity of concepts may be an inherent property that transcends modality representations.
Semi-supervised Learning for Word Sense Disambiguation
Aug 26, 2019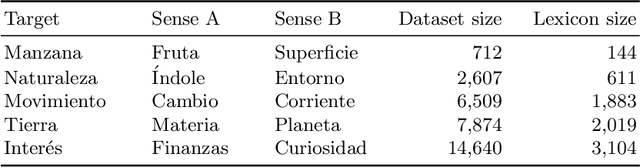
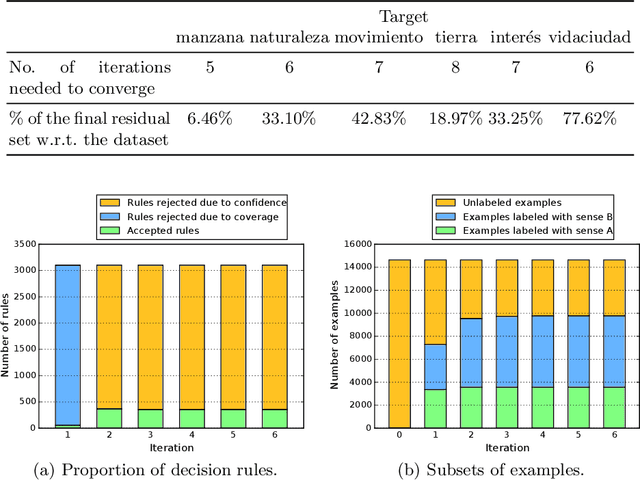

This work is a study of the impact of multiple aspects in a classic unsupervised word sense disambiguation algorithm. We identify relevant factors in a decision rule algorithm, including the initial labeling of examples, the formalization of the rule confidence, and the criteria for accepting a decision rule. Some of these factors are only implicitly considered in the original literature. We then propose a lightly supervised version of the algorithm, and employ a pseudo-word-based strategy to evaluate the impact of these factors. The obtained performances are comparable with those of highly optimized formulations of the word sense disambiguation method.
Unsupervised Context Retrieval for Long-tail Entities
Aug 05, 2019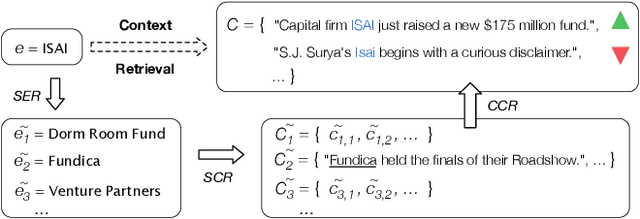
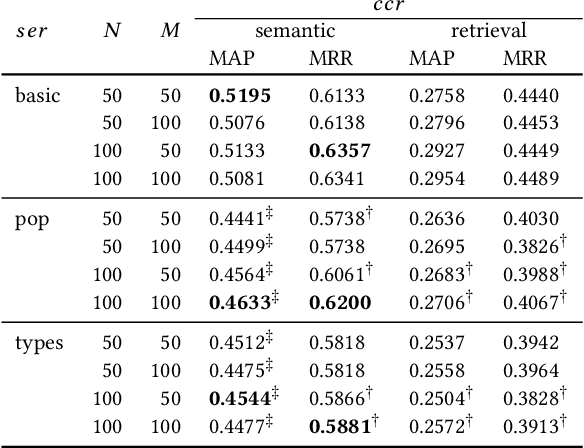
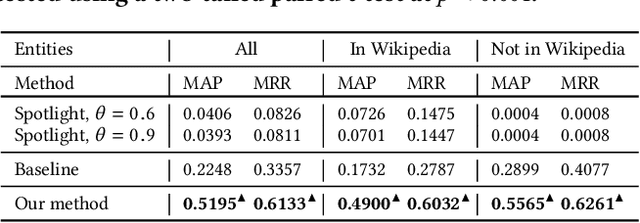
Monitoring entities in media streams often relies on rich entity representations, like structured information available in a knowledge base (KB). For long-tail entities, such monitoring is highly challenging, due to their limited, if not entirely missing, representation in the reference KB. In this paper, we address the problem of retrieving textual contexts for monitoring long-tail entities. We propose an unsupervised method to overcome the limited representation of long-tail entities by leveraging established entities and their contexts as support information. Evaluation on a purpose-built test collection shows the suitability of our approach and its robustness for out-of-KB entities.
NeuType: A Simple and Effective Neural Network Approach for Predicting Missing Entity Type Information in Knowledge Bases
Jul 05, 2019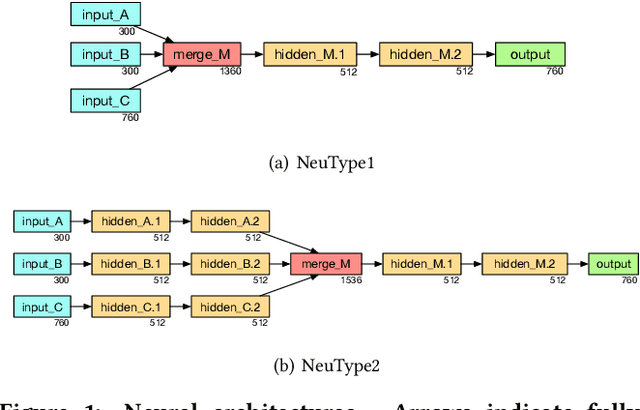
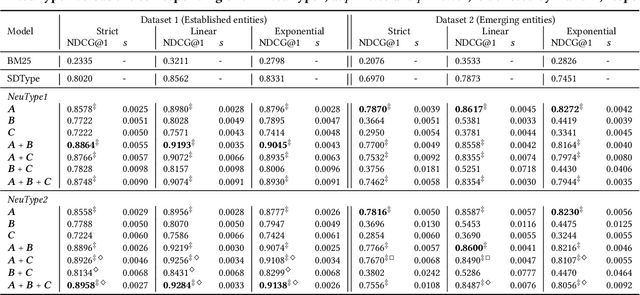
Knowledge bases store information about the semantic types of entities, which can be utilized in a range of information access tasks. This information, however, is often incomplete, due to new entities emerging on a daily basis. We address the task of automatically assigning types to entities in a knowledge base from a type taxonomy. Specifically, we present two neural network architectures, which take short entity descriptions and, optionally, information about related entities as input. Using the DBpedia knowledge base for experimental evaluation, we demonstrate that these simple architectures yield significant improvements over the current state of the art.
IntentsKB: A Knowledge Base of Entity-Oriented Search Intents
Sep 02, 2018
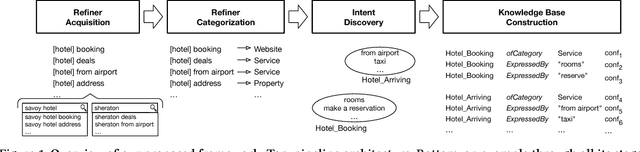

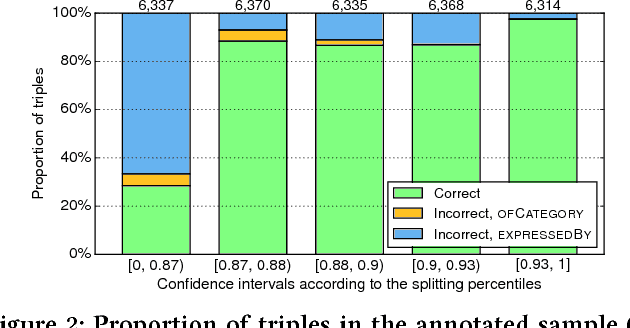
We address the problem of constructing a knowledge base of entity-oriented search intents. Search intents are defined on the level of entity types, each comprising of a high-level intent category (property, website, service, or other), along with a cluster of query terms used to express that intent. These machine-readable statements can be leveraged in various applications, e.g., for generating entity cards or query recommendations. By structuring service-oriented search intents, we take one step towards making entities actionable. The main contribution of this paper is a pipeline of components we develop to construct a knowledge base of entity intents. We evaluate performance both component-wise and end-to-end, and demonstrate that our approach is able to generate high-quality data.
Towards an Understanding of Entity-Oriented Search Intents
Feb 22, 2018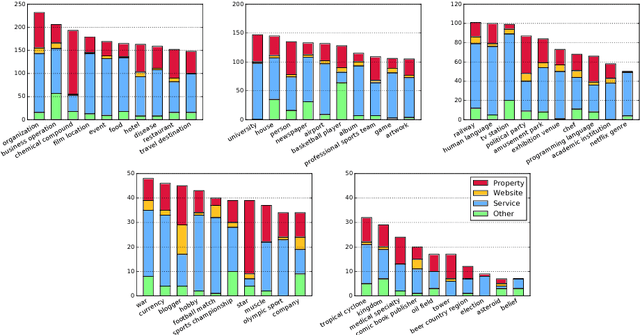
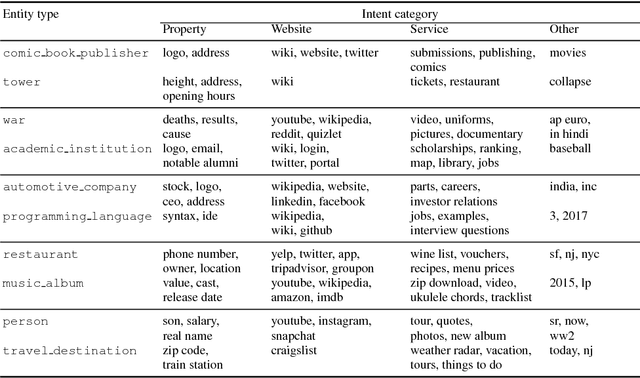
Entity-oriented search deals with a wide variety of information needs, from displaying direct answers to interacting with services. In this work, we aim to understand what are prominent entity-oriented search intents and how they can be fulfilled. We develop a scheme of entity intent categories, and use them to annotate a sample of queries. Specifically, we annotate unique query refiners on the level of entity types. We observe that, on average, over half of those refiners seek to interact with a service, while over a quarter of the refiners search for information that may be looked up in a knowledge base.
Generating High-Quality Query Suggestion Candidates for Task-Based Search
Feb 22, 2018
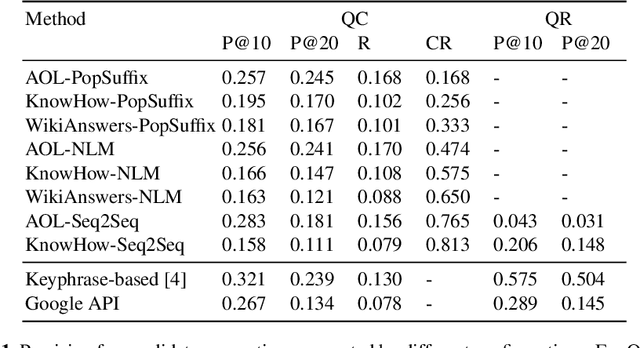
We address the task of generating query suggestions for task-based search. The current state of the art relies heavily on suggestions provided by a major search engine. In this paper, we solve the task without reliance on search engines. Specifically, we focus on the first step of a two-stage pipeline approach, which is dedicated to the generation of query suggestion candidates. We present three methods for generating candidate suggestions and apply them on multiple information sources. Using a purpose-built test collection, we find that these methods are able to generate high-quality suggestion candidates.
On Type-Aware Entity Retrieval
Aug 28, 2017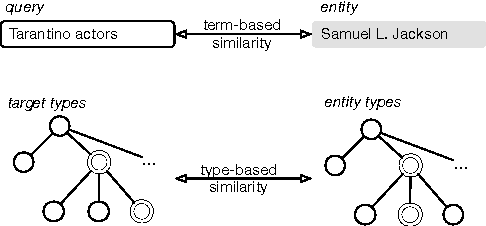
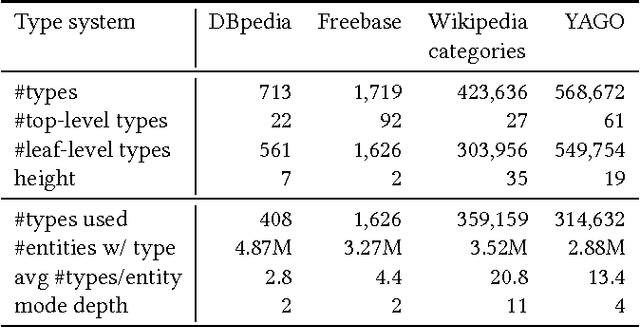
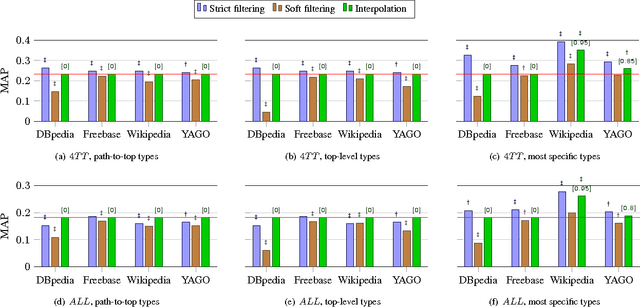
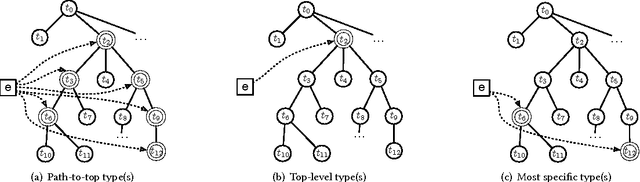
Today, the practice of returning entities from a knowledge base in response to search queries has become widespread. One of the distinctive characteristics of entities is that they are typed, i.e., assigned to some hierarchically organized type system (type taxonomy). The primary objective of this paper is to gain a better understanding of how entity type information can be utilized in entity retrieval. We perform this investigation in an idealized "oracle" setting, assuming that we know the distribution of target types of the relevant entities for a given query. We perform a thorough analysis of three main aspects: (i) the choice of type taxonomy, (ii) the representation of hierarchical type information, and (iii) the combination of type-based and term-based similarity in the retrieval model. Using a standard entity search test collection based on DBpedia, we find that type information proves most useful when using large type taxonomies that provide very specific types. We provide further insights on the extensional coverage of entities and on the utility of target types.
Generating Query Suggestions to Support Task-Based Search
Aug 28, 2017
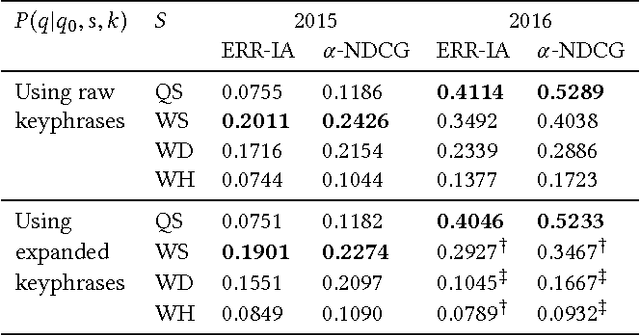
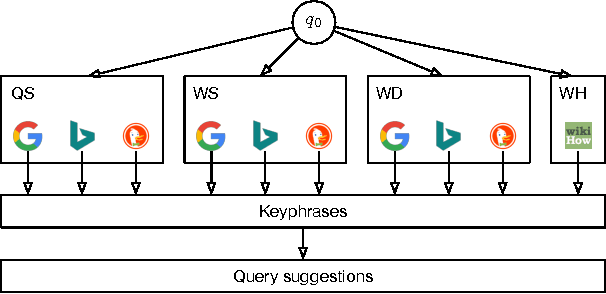
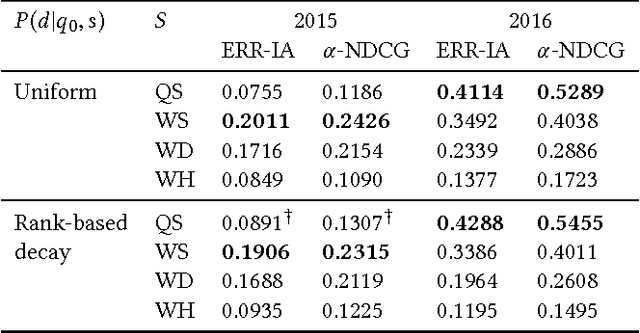
We address the problem of generating query suggestions to support users in completing their underlying tasks (which motivated them to search in the first place). Given an initial query, these query suggestions should provide a coverage of possible subtasks the user might be looking for. We propose a probabilistic modeling framework that obtains keyphrases from multiple sources and generates query suggestions from these keyphrases. Using the test suites of the TREC Tasks track, we evaluate and analyze each component of our model.