 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Drawing Identification Complexity is Invariant to Modality in Vision-Language Models
May 14, 2025Large language models have become multimodal, and many of them are said to integrate their modalities using common representations. If this were true, a drawing of a car as an image, for instance, should map to the similar area in the latent space as a textual description of the strokes that conform the drawing. To explore this in a black-box access regime to these models, we propose the use of machine teaching, a theory that studies the minimal set of examples a teacher needs to choose so that the learner captures the concept. In this paper we evaluate the complexity of teaching visual-language models a subset of objects in the Quick, Draw! dataset using two presentations: raw images as bitmaps and trace coordinates in TikZ format. The results indicate that image-based representations generally require fewer segments and achieve higher accuracy than coordinate-based representations. But, surprisingly, the teaching size usually ranks concepts similarly across both modalities, even when controlling for (a human proxy of) concept priors, suggesting that the simplicity of concepts may be an inherent property that transcends modality representations.
Multiple Time Series Fusion Based on LSTM An Application to CAP A Phase Classification Using EEG
Dec 18, 2021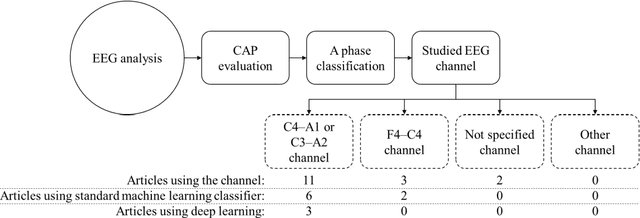

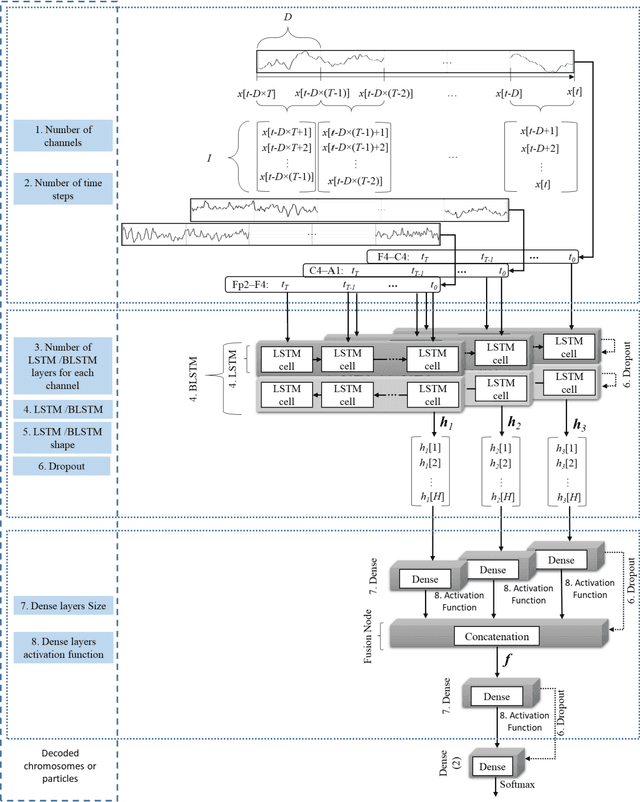

Biomedical decision making involves multiple signal processing, either from different sensors or from different channels. In both cases, information fusion plays a significant role. A deep learning based electroencephalogram channels' feature level fusion is carried out in this work for the electroencephalogram cyclic alternating pattern A phase classification. Channel selection, fusion, and classification procedures were optimized by two optimization algorithms, namely, Genetic Algorithm and Particle Swarm Optimization. The developed methodologies were evaluated by fusing the information from multiple electroencephalogram channels for patients with nocturnal frontal lobe epilepsy and patients without any neurological disorder, which was significantly more challenging when compared to other state of the art works. Results showed that both optimization algorithms selected a comparable structure with similar feature level fusion, consisting of three electroencephalogram channels, which is in line with the CAP protocol to ensure multiple channels' arousals for CAP detection. Moreover, the two optimized models reached an area under the receiver operating characteristic curve of 0.82, with average accuracy ranging from 77% to 79%, a result which is in the upper range of the specialist agreement. The proposed approach is still in the upper range of the best state of the art works despite a difficult dataset, and has the advantage of providing a fully automatic analysis without requiring any manual procedure. Ultimately, the models revealed to be noise resistant and resilient to multiple channel loss.