 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Data for Neural Keyword-to-Question Models
Jul 14, 2018
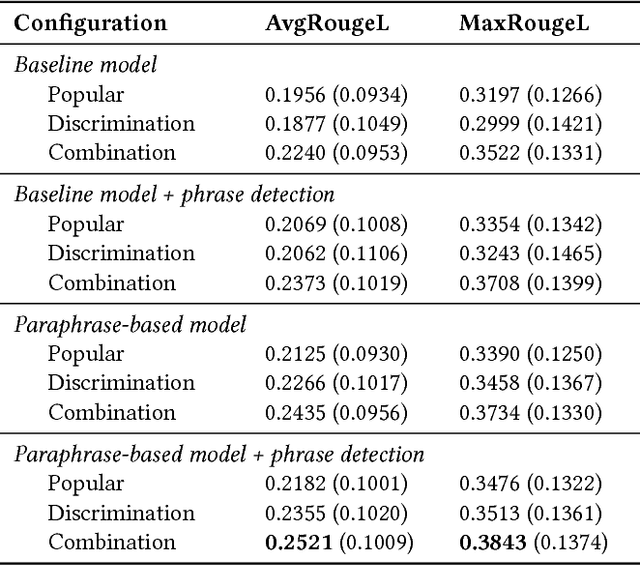
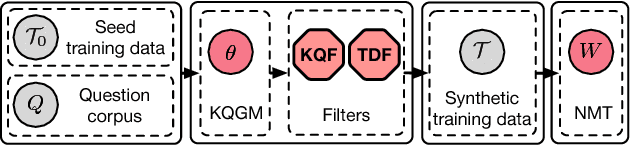
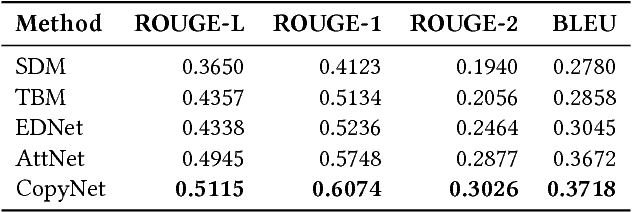
Search typically relies on keyword queries, but these are often semantically ambiguous. We propose to overcome this by offering users natural language questions, based on their keyword queries, to disambiguate their intent. This keyword-to-question task may be addressed using neural machine translation techniques. Neural translation models, however, require massive amounts of training data (keyword-question pairs), which is unavailable for this task. The main idea of this paper is to generate large amounts of synthetic training data from a small seed set of hand-labeled keyword-question pairs. Since natural language questions are available in large quantities, we develop models to automatically generate the corresponding keyword queries. Further, we introduce various filtering mechanisms to ensure that synthetic training data is of high quality. We demonstrate the feasibility of our approach using both automatic and manual evaluation. This is an extended version of the article published with the same title in the Proceedings of ICTIR'18.
Generating High-Quality Query Suggestion Candidates for Task-Based Search
Feb 22, 2018
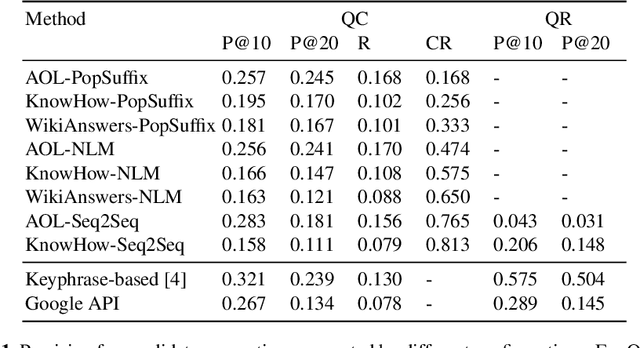
We address the task of generating query suggestions for task-based search. The current state of the art relies heavily on suggestions provided by a major search engine. In this paper, we solve the task without reliance on search engines. Specifically, we focus on the first step of a two-stage pipeline approach, which is dedicated to the generation of query suggestion candidates. We present three methods for generating candidate suggestions and apply them on multiple information sources. Using a purpose-built test collection, we find that these methods are able to generate high-quality suggestion candidates.