 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructured Denoising Diffusion Models in Discrete State-Spaces
Jul 13, 2021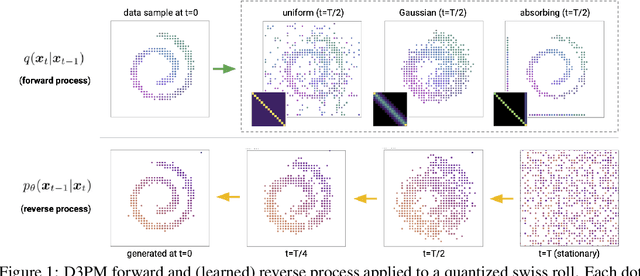
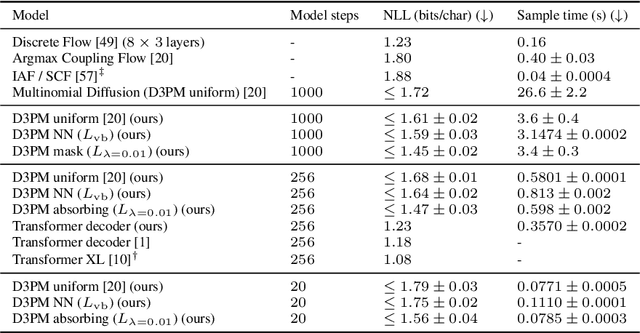

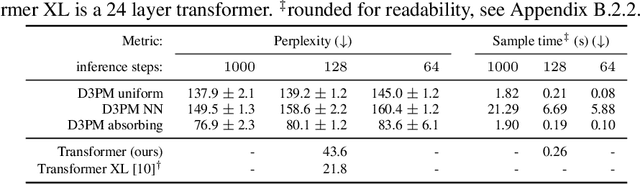
Denoising diffusion probabilistic models (DDPMs) (Ho et al. 2020) have shown impressive results on image and waveform generation in continuous state spaces. Here, we introduce Discrete Denoising Diffusion Probabilistic Models (D3PMs), diffusion-like generative models for discrete data that generalize the multinomial diffusion model of Hoogeboom et al. 2021, by going beyond corruption processes with uniform transition probabilities. This includes corruption with transition matrices that mimic Gaussian kernels in continuous space, matrices based on nearest neighbors in embedding space, and matrices that introduce absorbing states. The third allows us to draw a connection between diffusion models and autoregressive and mask-based generative models. We show that the choice of transition matrix is an important design decision that leads to improved results in image and text domains. We also introduce a new loss function that combines the variational lower bound with an auxiliary cross entropy loss. For text, this model class achieves strong results on character-level text generation while scaling to large vocabularies on LM1B. On the image dataset CIFAR-10, our models approach the sample quality and exceed the log-likelihood of the continuous-space DDPM model.
Learning to Combine Per-Example Solutions for Neural Program Synthesis
Jun 14, 2021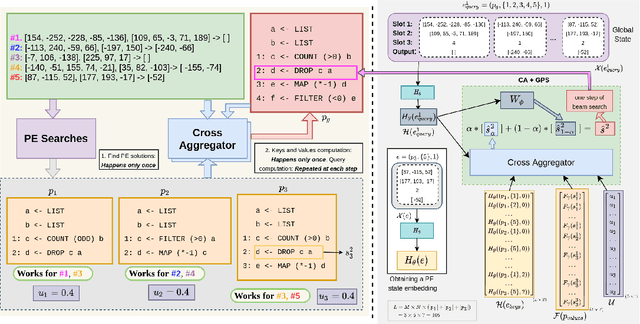

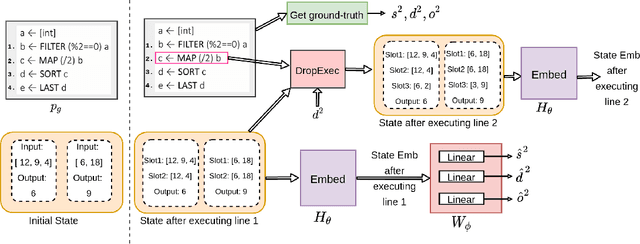
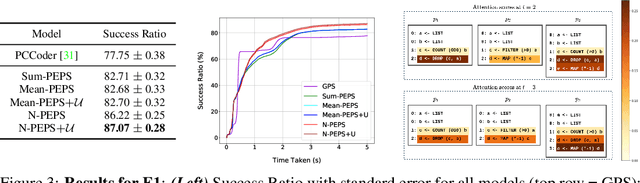
The goal of program synthesis from examples is to find a computer program that is consistent with a given set of input-output examples. Most learning-based approaches try to find a program that satisfies all examples at once. Our work, by contrast, considers an approach that breaks the problem into two stages: (a) find programs that satisfy only one example, and (b) leverage these per-example solutions to yield a program that satisfies all examples. We introduce the Cross Aggregator neural network module based on a multi-head attention mechanism that learns to combine the cues present in these per-example solutions to synthesize a global solution. Evaluation across programs of different lengths and under two different experimental settings reveal that when given the same time budget, our technique significantly improves the success rate over PCCoder arXiv:1809.04682v2 [cs.LG] and other ablation baselines. The code, data and trained models for our work can be found at https://github.com/shrivastavadisha/N-PEPS.
Learning to Extend Program Graphs to Work-in-Progress Code
May 28, 2021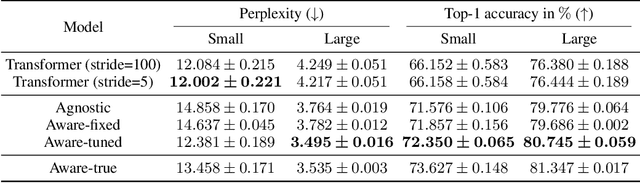
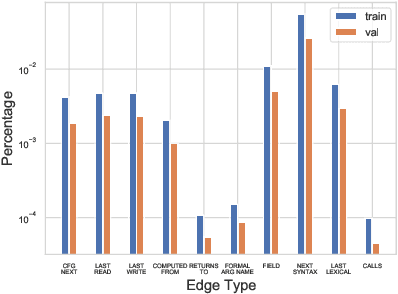
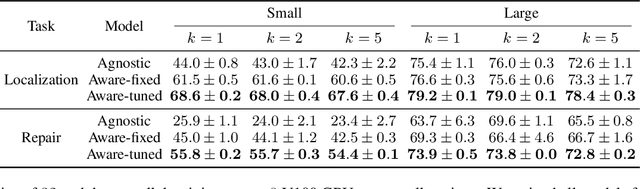
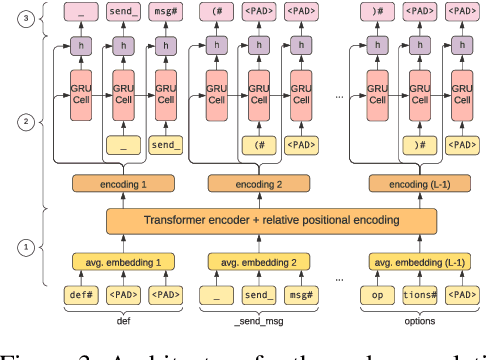
Source code spends most of its time in a broken or incomplete state during software development. This presents a challenge to machine learning for code, since high-performing models typically rely on graph structured representations of programs derived from traditional program analyses. Such analyses may be undefined for broken or incomplete code. We extend the notion of program graphs to work-in-progress code by learning to predict edge relations between tokens, training on well-formed code before transferring to work-in-progress code. We consider the tasks of code completion and localizing and repairing variable misuse in a work-in-process scenario. We demonstrate that training relation-aware models with fine-tuned edges consistently leads to improved performance on both tasks.
Learning to Execute Programs with Instruction Pointer Attention Graph Neural Networks
Oct 23, 2020

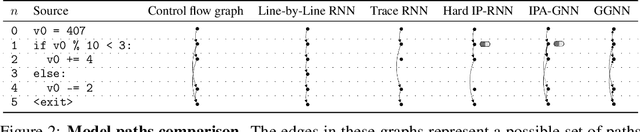
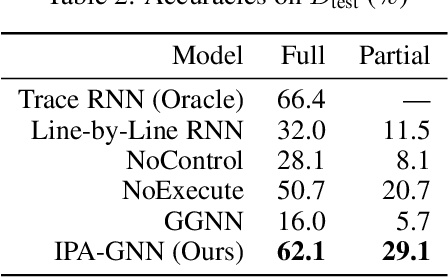
Graph neural networks (GNNs) have emerged as a powerful tool for learning software engineering tasks including code completion, bug finding, and program repair. They benefit from leveraging program structure like control flow graphs, but they are not well-suited to tasks like program execution that require far more sequential reasoning steps than number of GNN propagation steps. Recurrent neural networks (RNNs), on the other hand, are well-suited to long sequential chains of reasoning, but they do not naturally incorporate program structure and generally perform worse on the above tasks. Our aim is to achieve the best of both worlds, and we do so by introducing a novel GNN architecture, the Instruction Pointer Attention Graph Neural Networks (IPA-GNN), which achieves improved systematic generalization on the task of learning to execute programs using control flow graphs. The model arises by considering RNNs operating on program traces with branch decisions as latent variables. The IPA-GNN can be seen either as a continuous relaxation of the RNN model or as a GNN variant more tailored to execution. To test the models, we propose evaluating systematic generalization on learning to execute using control flow graphs, which tests sequential reasoning and use of program structure. More practically, we evaluate these models on the task of learning to execute partial programs, as might arise if using the model as a heuristic function in program synthesis. Results show that the IPA-GNN outperforms a variety of RNN and GNN baselines on both tasks.
Software Engineering Event Modeling using Relative Time in Temporal Knowledge Graphs
Jul 13, 2020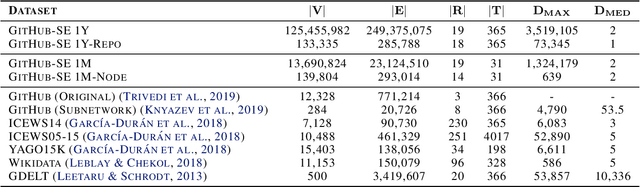
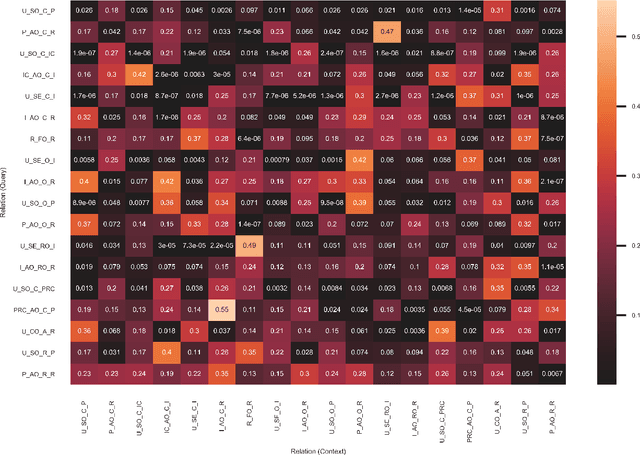
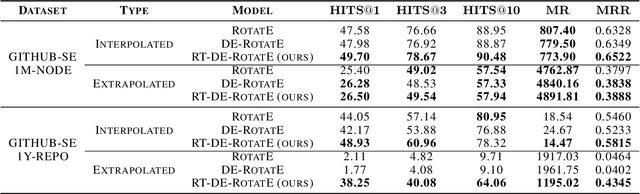
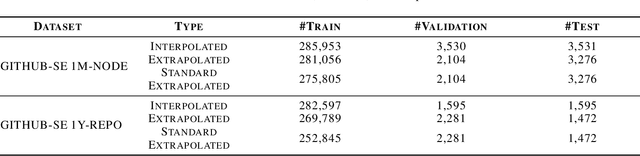
We present a multi-relational temporal Knowledge Graph based on the daily interactions between artifacts in GitHub, one of the largest social coding platforms. Such representation enables posing many user-activity and project management questions as link prediction and time queries over the knowledge graph. In particular, we introduce two new datasets for i) interpolated time-conditioned link prediction and ii) extrapolated time-conditioned link/time prediction queries, each with distinguished properties. Our experiments on these datasets highlight the potential of adapting knowledge graphs to answer broad software engineering questions. Meanwhile, it also reveals the unsatisfactory performance of existing temporal models on extrapolated queries and time prediction queries in general. To overcome these shortcomings, we introduce an extension to current temporal models using relative temporal information with regards to past events.
Learning Graph Structure With A Finite-State Automaton Layer
Jul 09, 2020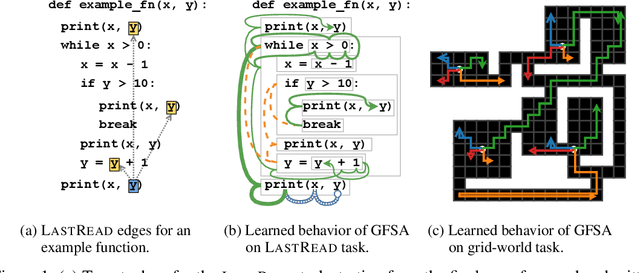
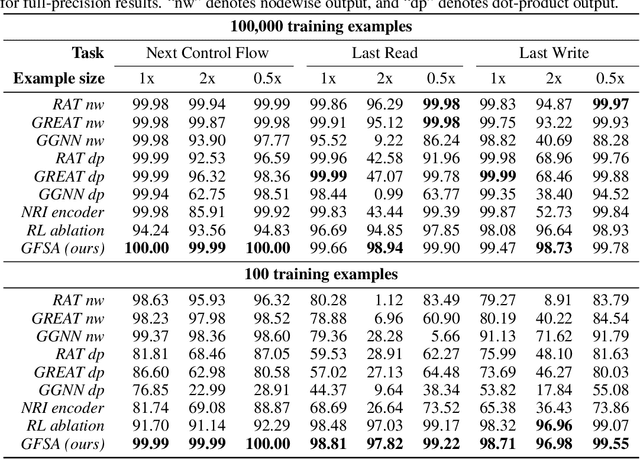
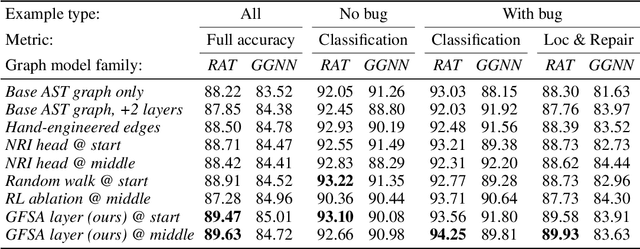
Graph-based neural network models are producing strong results in a number of domains, in part because graphs provide flexibility to encode domain knowledge in the form of relational structure (edges) between nodes in the graph. In practice, edges are used both to represent intrinsic structure (e.g., abstract syntax trees of programs) and more abstract relations that aid reasoning for a downstream task (e.g., results of relevant program analyses). In this work, we study the problem of learning to derive abstract relations from the intrinsic graph structure. Motivated by their power in program analyses, we consider relations defined by paths on the base graph accepted by a finite-state automaton. We show how to learn these relations end-to-end by relaxing the problem into learning finite-state automata policies on a graph-based POMDP and then training these policies using implicit differentiation. The result is a differentiable Graph Finite-State Automaton (GFSA) layer that adds a new edge type (expressed as a weighted adjacency matrix) to a base graph. We demonstrate that this layer can find shortcuts in grid-world graphs and reproduce simple static analyses on Python programs. Additionally, we combine the GFSA layer with a larger graph-based model trained end-to-end on the variable misuse program understanding task, and find that using the GFSA layer leads to better performance than using hand-engineered semantic edges or other baseline methods for adding learned edge types.
Gradient Estimation with Stochastic Softmax Tricks
Jun 15, 2020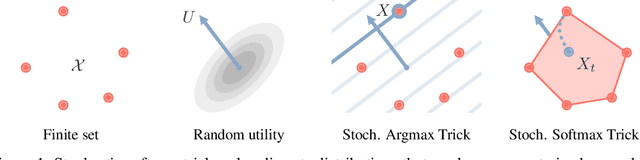
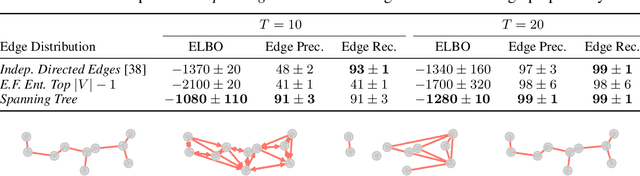
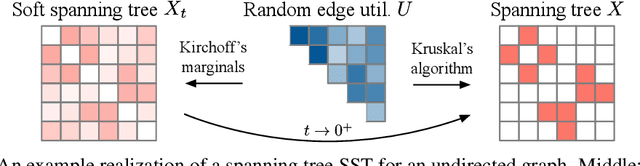
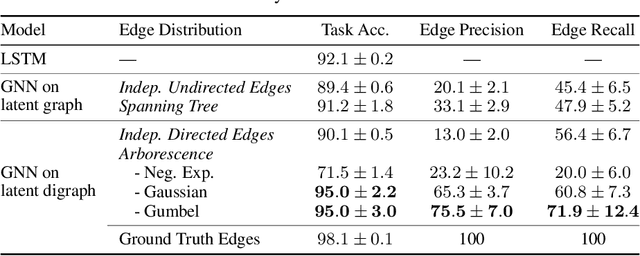
The Gumbel-Max trick is the basis of many relaxed gradient estimators. These estimators are easy to implement and low variance, but the goal of scaling them comprehensively to large combinatorial distributions is still outstanding. Working within the perturbation model framework, we introduce stochastic softmax tricks, which generalize the Gumbel-Softmax trick to combinatorial spaces. Our framework is a unified perspective on existing relaxed estimators for perturbation models, and it contains many novel relaxations. We design structured relaxations for subset selection, spanning trees, arborescences, and others. When compared to less structured baselines, we find that stochastic softmax tricks can be used to train latent variable models that perform better and discover more latent structure.
On-the-Fly Adaptation of Source Code Models using Meta-Learning
Mar 26, 2020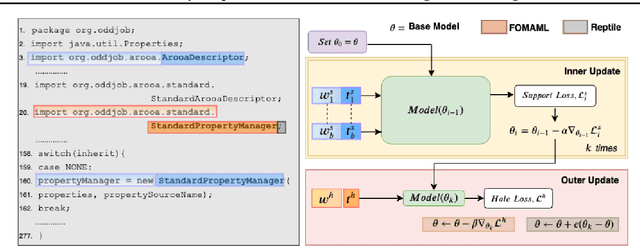

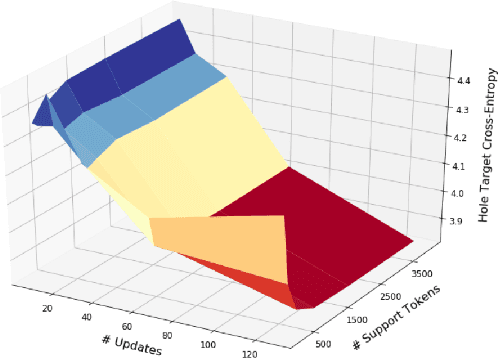
The ability to adapt to unseen, local contexts is an important challenge that successful models of source code must overcome. One of the most popular approaches for the adaptation of such models is dynamic evaluation. With dynamic evaluation, when running a model on an unseen file, the model is updated immediately after having observed each token in that file. In this work, we propose instead to frame the problem of context adaptation as a meta-learning problem. We aim to train a base source code model that is best able to learn from information in a file to deliver improved predictions of missing tokens. Unlike dynamic evaluation, this formulation allows us to select more targeted information (support tokens) for adaptation, that is both before and after a target hole in a file. We consider an evaluation setting that we call line-level maintenance, designed to reflect the downstream task of code auto-completion in an IDE. Leveraging recent developments in meta-learning such as first-order MAML and Reptile, we demonstrate improved performance in experiments on a large scale Java GitHub corpus, compared to other adaptation baselines including dynamic evaluation. Moreover, our analysis shows that, compared to a non-adaptive baseline, our approach improves performance on identifiers and literals by 44\% and 15\%, respectively. Our implementation can be found at: https://github.com/shrivastavadisha/meta_learn_source_code
Learning to Fix Build Errors with Graph2Diff Neural Networks
Nov 04, 2019

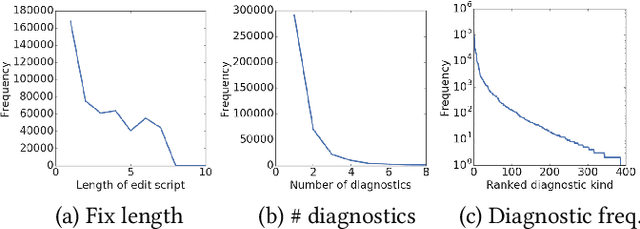

Professional software developers spend a significant amount of time fixing builds, but this has received little attention as a problem in automatic program repair. We present a new deep learning architecture, called Graph2Diff, for automatically localizing and fixing build errors. We represent source code, build configuration files, and compiler diagnostic messages as a graph, and then use a Graph Neural Network model to predict a diff. A diff specifies how to modify the code's abstract syntax tree, represented in the neural network as a sequence of tokens and of pointers to code locations. Our network is an instance of a more general abstraction that we call Graph2Tocopo, which is potentially useful in any development tool for predicting source code changes. We evaluate the model on a dataset of over 500k real build errors and their resolutions from professional developers. Compared to the approach of DeepDelta (Mesbah et al., 2019), our approach tackles the harder task of predicting a more precise diff but still achieves over double the accuracy.
Fast Training of Sparse Graph Neural Networks on Dense Hardware
Jun 27, 2019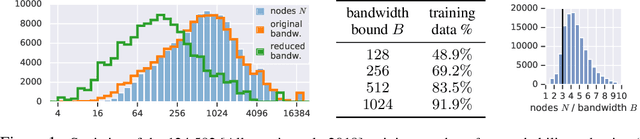

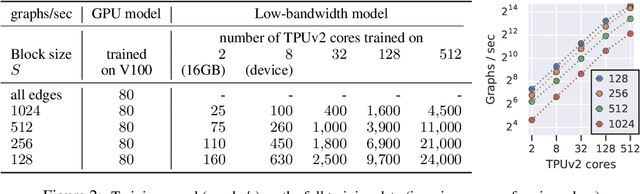
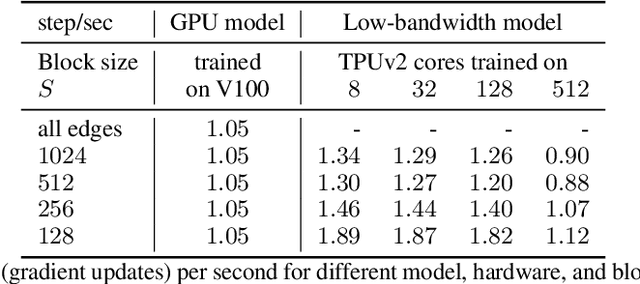
Graph neural networks have become increasingly popular in recent years due to their ability to naturally encode relational input data and their ability to scale to large graphs by operating on a sparse representation of graph adjacency matrices. As we look to scale up these models using custom hardware, a natural assumption would be that we need hardware tailored to sparse operations and/or dynamic control flow. In this work, we question this assumption by scaling up sparse graph neural networks using a platform targeted at dense computation on fixed-size data. Drawing inspiration from optimization of numerical algorithms on sparse matrices, we develop techniques that enable training the sparse graph neural network model from Allamanis et al. [2018] in 13 minutes using a 512-core TPUv2 Pod, whereas the original training takes almost a day.