 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Methods for Distributionally Robust Optimization
Oct 12, 2020
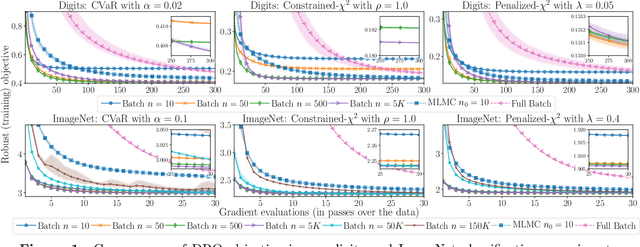
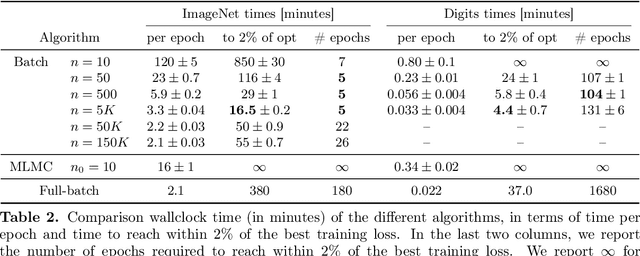

We propose and analyze algorithms for distributionally robust optimization of convex losses with conditional value at risk (CVaR) and $\chi^2$ divergence uncertainty sets. We prove that our algorithms require a number of gradient evaluations independent of training set size and number of parameters, making them suitable for large-scale applications. For $\chi^2$ uncertainty sets these are the first such guarantees in the literature, and for CVaR our guarantees scale linearly in the uncertainty level rather than quadratically as in previous work. We also provide lower bounds proving the worst-case optimality of our algorithms for CVaR and a penalized version of the $\chi^2$ problem. Our primary technical contributions are novel bounds on the bias of batch robust risk estimation and the variance of a multilevel Monte Carlo gradient estimator due to [Blanchet & Glynn, 2015]. Experiments on MNIST and ImageNet confirm the theoretical scaling of our algorithms, which are 9--36 times more efficient than full-batch methods.
Necessary and Sufficient Geometries for Gradient Methods
Oct 28, 2019We study the impact of the constraint set and gradient geometry on the convergence of online and stochastic methods for convex optimization, providing a characterization of the geometries for which stochastic gradient and adaptive gradient methods are (minimax) optimal. In particular, we show that when the constraint set is quadratically convex, diagonally pre-conditioned stochastic gradient methods are minimax optimal. We further provide a converse that shows that when the constraints are not quadratically convex---for example, any $\ell_p$-ball for $p < 2$---the methods are far from optimal. Based on this, we can provide concrete recommendations for when one should use adaptive, mirror or stochastic gradient methods.
Generalizing Hamiltonian Monte Carlo with Neural Networks
Mar 02, 2018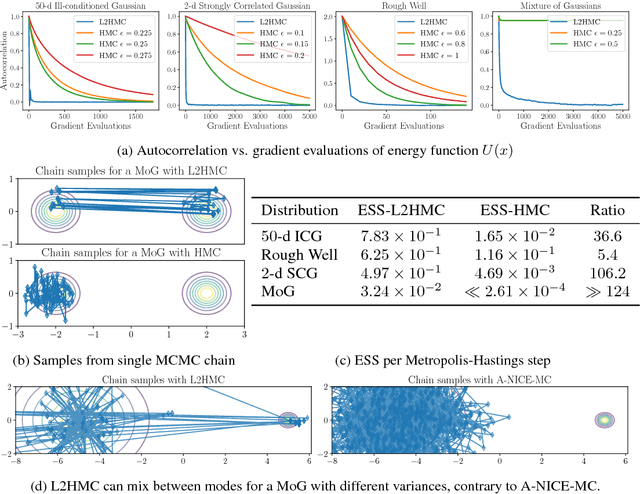

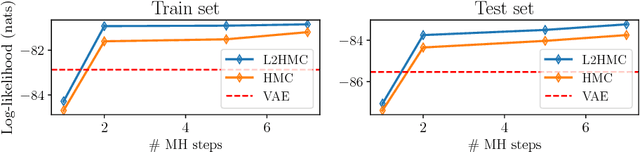

We present a general-purpose method to train Markov chain Monte Carlo kernels, parameterized by deep neural networks, that converge and mix quickly to their target distribution. Our method generalizes Hamiltonian Monte Carlo and is trained to maximize expected squared jumped distance, a proxy for mixing speed. We demonstrate large empirical gains on a collection of simple but challenging distributions, for instance achieving a 106x improvement in effective sample size in one case, and mixing when standard HMC makes no measurable progress in a second. Finally, we show quantitative and qualitative gains on a real-world task: latent-variable generative modeling. We release an open source TensorFlow implementation of the algorithm.
Deterministic Policy Optimization by Combining Pathwise and Score Function Estimators for Discrete Action Spaces
Nov 21, 2017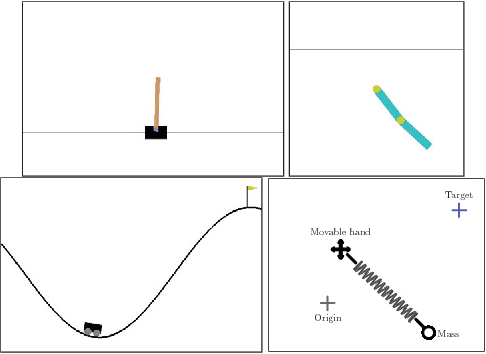
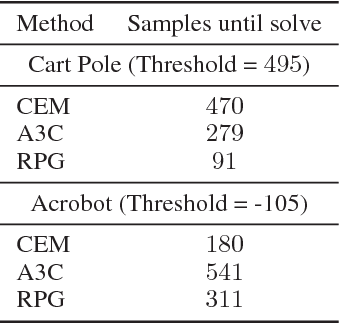
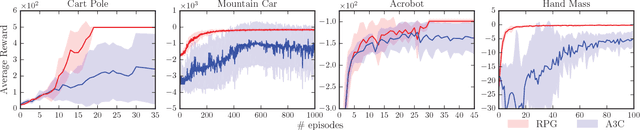
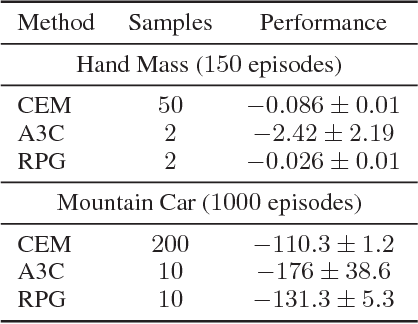
Policy optimization methods have shown great promise in solving complex reinforcement and imitation learning tasks. While model-free methods are broadly applicable, they often require many samples to optimize complex policies. Model-based methods greatly improve sample-efficiency but at the cost of poor generalization, requiring a carefully handcrafted model of the system dynamics for each task. Recently, hybrid methods have been successful in trading off applicability for improved sample-complexity. However, these have been limited to continuous action spaces. In this work, we present a new hybrid method based on an approximation of the dynamics as an expectation over the next state under the current policy. This relaxation allows us to derive a novel hybrid policy gradient estimator, combining score function and pathwise derivative estimators, that is applicable to discrete action spaces. We show significant gains in sample complexity, ranging between $1.7$ and $25\times$, when learning parameterized policies on Cart Pole, Acrobot, Mountain Car and Hand Mass. Our method is applicable to both discrete and continuous action spaces, when competing pathwise methods are limited to the latter.
Fast Amortized Inference and Learning in Log-linear Models with Randomly Perturbed Nearest Neighbor Search
Jul 11, 2017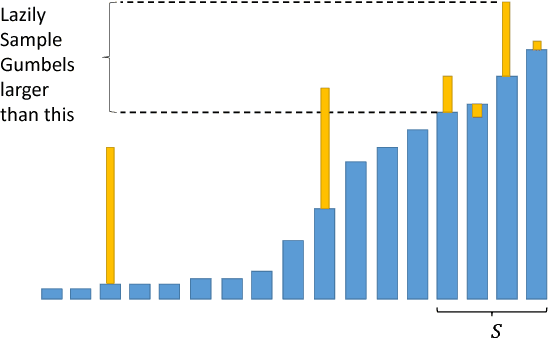

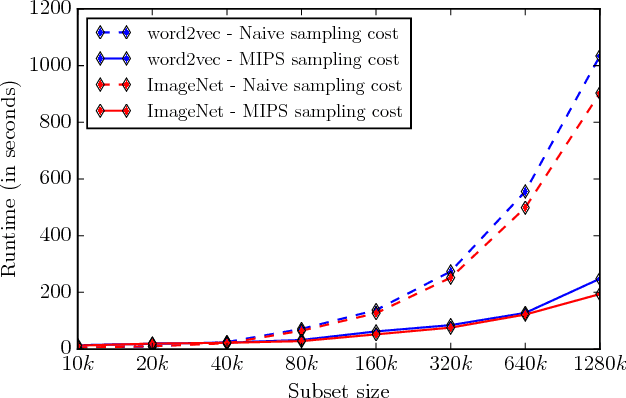

Inference in log-linear models scales linearly in the size of output space in the worst-case. This is often a bottleneck in natural language processing and computer vision tasks when the output space is feasibly enumerable but very large. We propose a method to perform inference in log-linear models with sublinear amortized cost. Our idea hinges on using Gumbel random variable perturbations and a pre-computed Maximum Inner Product Search data structure to access the most-likely elements in sublinear amortized time. Our method yields provable runtime and accuracy guarantees. Further, we present empirical experiments on ImageNet and Word Embeddings showing significant speedups for sampling, inference, and learning in log-linear models.