 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantitatively Evaluating GANs With Divergences Proposed for Training
Apr 28, 2018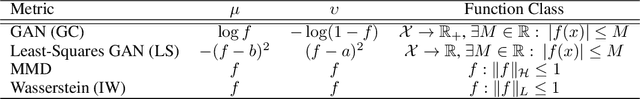
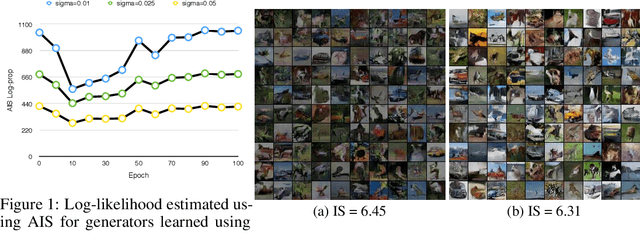
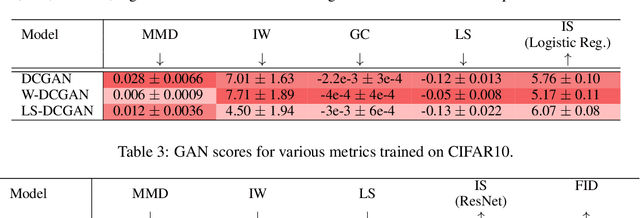

Generative adversarial networks (GANs) have been extremely effective in approximating complex distributions of high-dimensional, input data samples, and substantial progress has been made in understanding and improving GAN performance in terms of both theory and application. However, we currently lack quantitative methods for model assessment. Because of this, while many GAN variants are being proposed, we have relatively little understanding of their relative abilities. In this paper, we evaluate the performance of various types of GANs using divergence and distance functions typically used only for training. We observe consistency across the various proposed metrics and, interestingly, the test-time metrics do not favour networks that use the same training-time criterion. We also compare the proposed metrics to human perceptual scores.
An empirical analysis of the optimization of deep network loss surfaces
Dec 07, 2017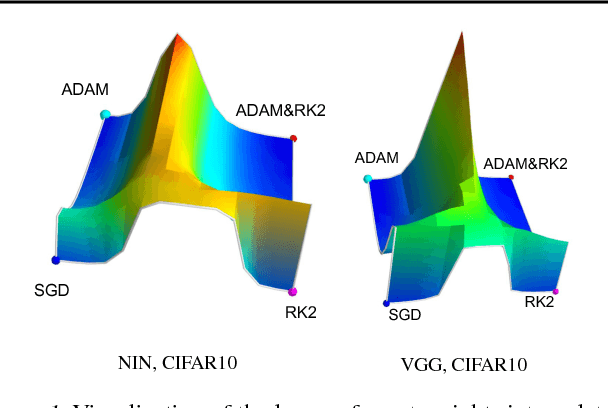
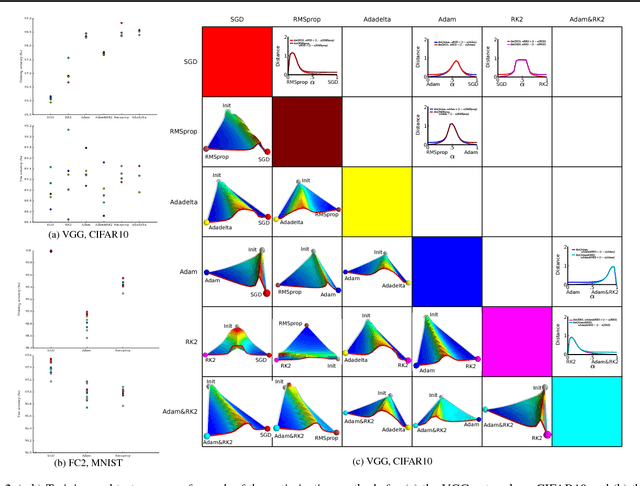
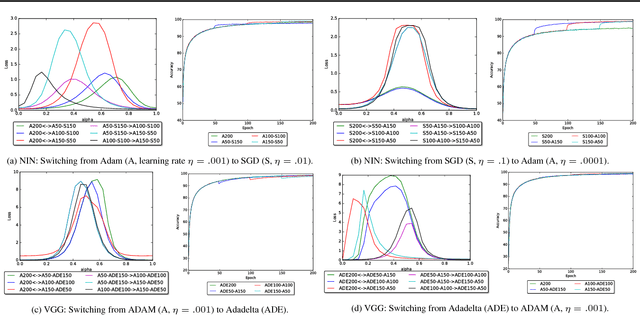
The success of deep neural networks hinges on our ability to accurately and efficiently optimize high-dimensional, non-convex functions. In this paper, we empirically investigate the loss functions of state-of-the-art networks, and how commonly-used stochastic gradient descent variants optimize these loss functions. To do this, we visualize the loss function by projecting them down to low-dimensional spaces chosen based on the convergence points of different optimization algorithms. Our observations suggest that optimization algorithms encounter and choose different descent directions at many saddle points to find different final weights. Based on consistency we observe across re-runs of the same stochastic optimization algorithm, we hypothesize that each optimization algorithm makes characteristic choices at these saddle points.
Neural Machine Translation with Gumbel-Greedy Decoding
Jun 22, 2017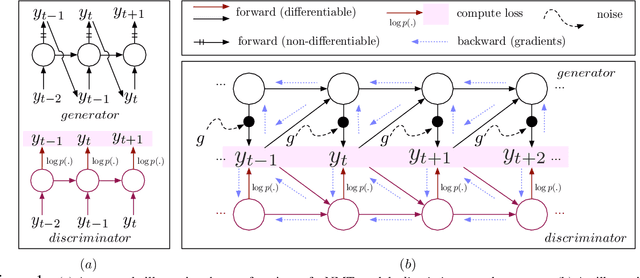
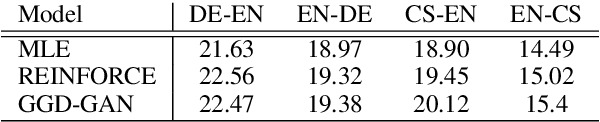
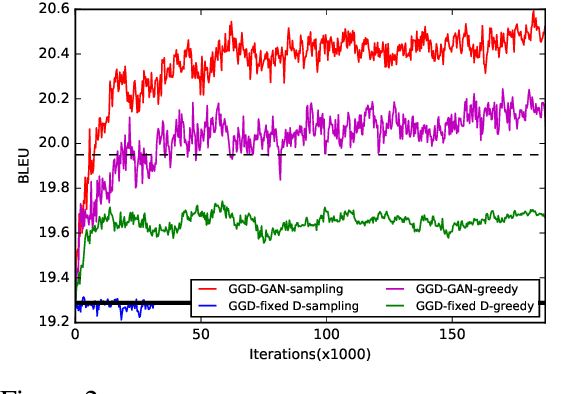

Previous neural machine translation models used some heuristic search algorithms (e.g., beam search) in order to avoid solving the maximum a posteriori problem over translation sentences at test time. In this paper, we propose the Gumbel-Greedy Decoding which trains a generative network to predict translation under a trained model. We solve such a problem using the Gumbel-Softmax reparameterization, which makes our generative network differentiable and trainable through standard stochastic gradient methods. We empirically demonstrate that our proposed model is effective for generating sequences of discrete words.
Generative Adversarial Parallelization
Dec 13, 2016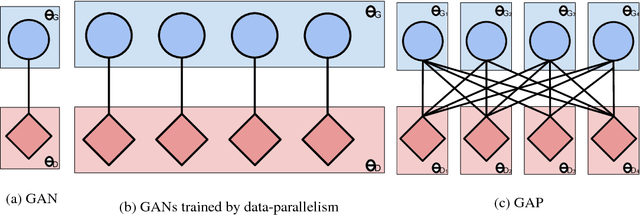


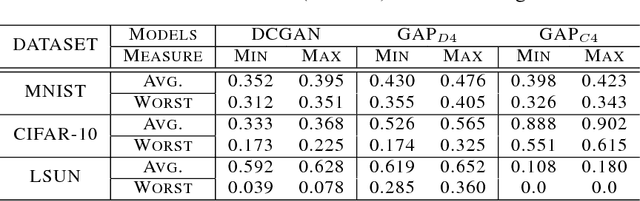
Generative Adversarial Networks have become one of the most studied frameworks for unsupervised learning due to their intuitive formulation. They have also been shown to be capable of generating convincing examples in limited domains, such as low-resolution images. However, they still prove difficult to train in practice and tend to ignore modes of the data generating distribution. Quantitatively capturing effects such as mode coverage and more generally the quality of the generative model still remain elusive. We propose Generative Adversarial Parallelization, a framework in which many GANs or their variants are trained simultaneously, exchanging their discriminators. This eliminates the tight coupling between a generator and discriminator, leading to improved convergence and improved coverage of modes. We also propose an improved variant of the recently proposed Generative Adversarial Metric and show how it can score individual GANs or their collections under the GAP model.
Generating images with recurrent adversarial networks
Dec 13, 2016
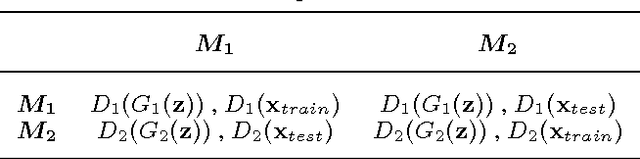
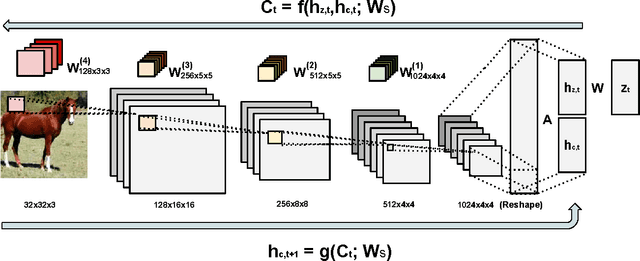
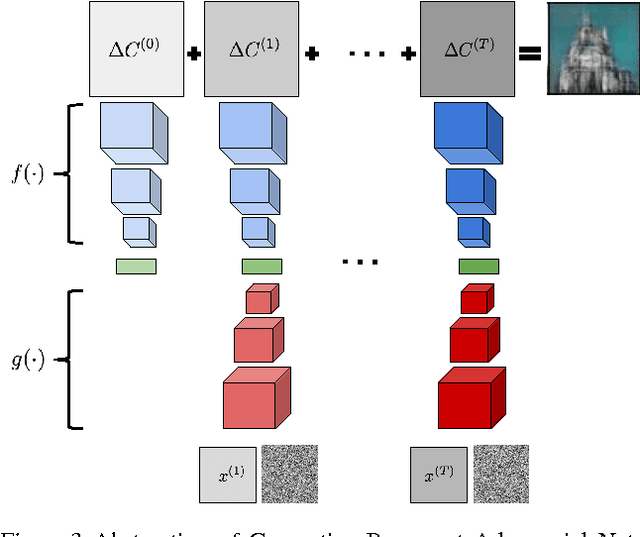
Gatys et al. (2015) showed that optimizing pixels to match features in a convolutional network with respect reference image features is a way to render images of high visual quality. We show that unrolling this gradient-based optimization yields a recurrent computation that creates images by incrementally adding onto a visual "canvas". We propose a recurrent generative model inspired by this view, and show that it can be trained using adversarial training to generate very good image samples. We also propose a way to quantitatively compare adversarial networks by having the generators and discriminators of these networks compete against each other.
Learning a metric for class-conditional KNN
Jul 11, 2016
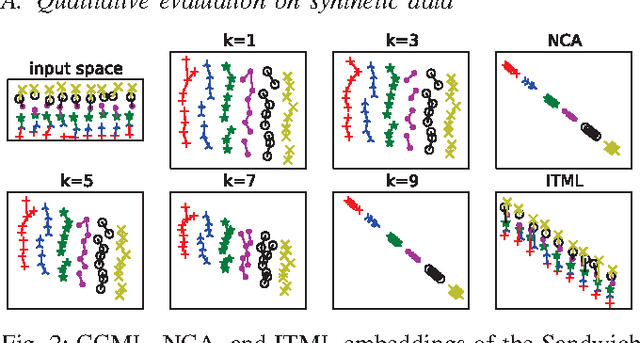
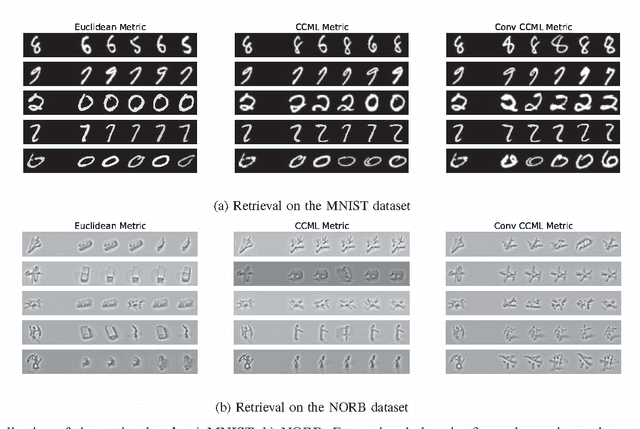
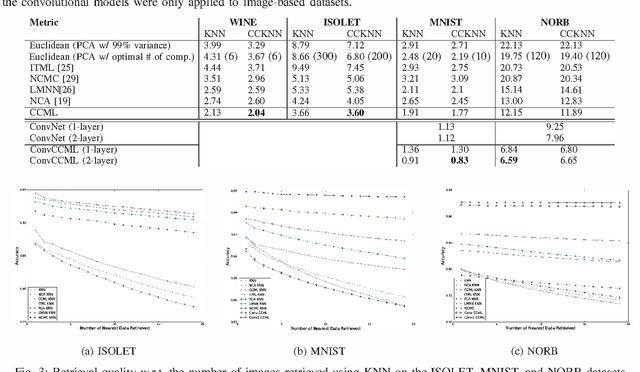
Naive Bayes Nearest Neighbour (NBNN) is a simple and effective framework which addresses many of the pitfalls of K-Nearest Neighbour (KNN) classification. It has yielded competitive results on several computer vision benchmarks. Its central tenet is that during NN search, a query is not compared to every example in a database, ignoring class information. Instead, NN searches are performed within each class, generating a score per class. A key problem with NN techniques, including NBNN, is that they fail when the data representation does not capture perceptual (e.g.~class-based) similarity. NBNN circumvents this by using independent engineered descriptors (e.g.~SIFT). To extend its applicability outside of image-based domains, we propose to learn a metric which captures perceptual similarity. Similar to how Neighbourhood Components Analysis optimizes a differentiable form of KNN classification, we propose "Class Conditional" metric learning (CCML), which optimizes a soft form of the NBNN selection rule. Typical metric learning algorithms learn either a global or local metric. However, our proposed method can be adjusted to a particular level of locality by tuning a single parameter. An empirical evaluation on classification and retrieval tasks demonstrates that our proposed method clearly outperforms existing learned distance metrics across a variety of image and non-image datasets.
Denoising Criterion for Variational Auto-Encoding Framework
Jan 04, 2016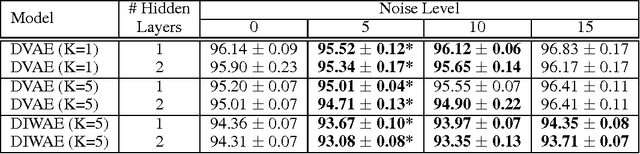
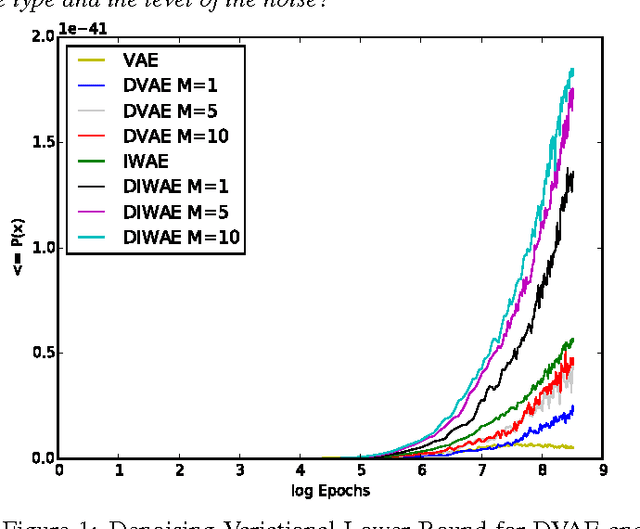
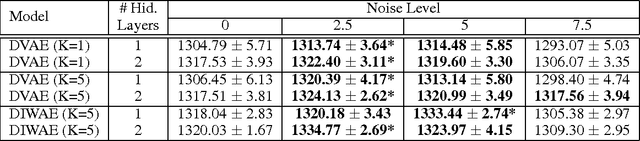

Denoising autoencoders (DAE) are trained to reconstruct their clean inputs with noise injected at the input level, while variational autoencoders (VAE) are trained with noise injected in their stochastic hidden layer, with a regularizer that encourages this noise injection. In this paper, we show that injecting noise both in input and in the stochastic hidden layer can be advantageous and we propose a modified variational lower bound as an improved objective function in this setup. When input is corrupted, then the standard VAE lower bound involves marginalizing the encoder conditional distribution over the input noise, which makes the training criterion intractable. Instead, we propose a modified training criterion which corresponds to a tractable bound when input is corrupted. Experimentally, we find that the proposed denoising variational autoencoder (DVAE) yields better average log-likelihood than the VAE and the importance weighted autoencoder on the MNIST and Frey Face datasets.
Conservativeness of untied auto-encoders
Sep 21, 2015

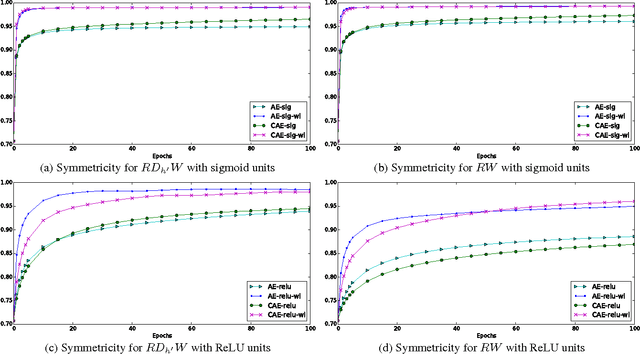
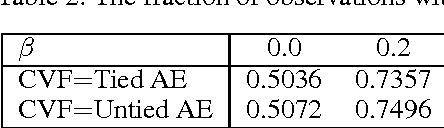
We discuss necessary and sufficient conditions for an auto-encoder to define a conservative vector field, in which case it is associated with an energy function akin to the unnormalized log-probability of the data. We show that the conditions for conservativeness are more general than for encoder and decoder weights to be the same ("tied weights"), and that they also depend on the form of the hidden unit activation function, but that contractive training criteria, such as denoising, will enforce these conditions locally. Based on these observations, we show how we can use auto-encoders to extract the conservative component of a vector field.
Scoring and Classifying with Gated Auto-encoders
Jun 15, 2015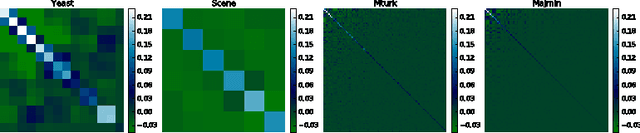
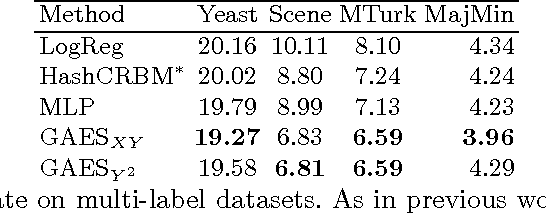
Auto-encoders are perhaps the best-known non-probabilistic methods for representation learning. They are conceptually simple and easy to train. Recent theoretical work has shed light on their ability to capture manifold structure, and drawn connections to density modelling. This has motivated researchers to seek ways of auto-encoder scoring, which has furthered their use in classification. Gated auto-encoders (GAEs) are an interesting and flexible extension of auto-encoders which can learn transformations among different images or pixel covariances within images. However, they have been much less studied, theoretically or empirically. In this work, we apply a dynamical systems view to GAEs, deriving a scoring function, and drawing connections to Restricted Boltzmann Machines. On a set of deep learning benchmarks, we also demonstrate their effectiveness for single and multi-label classification.
Understanding Minimum Probability Flow for RBMs Under Various Kinds of Dynamics
Apr 07, 2015
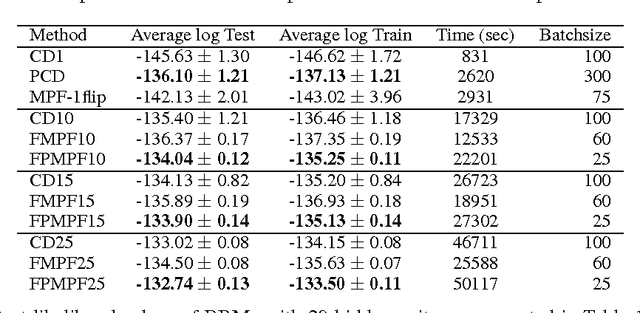

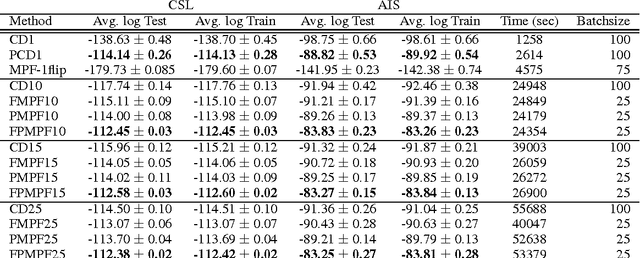
Energy-based models are popular in machine learning due to the elegance of their formulation and their relationship to statistical physics. Among these, the Restricted Boltzmann Machine (RBM), and its staple training algorithm contrastive divergence (CD), have been the prototype for some recent advancements in the unsupervised training of deep neural networks. However, CD has limited theoretical motivation, and can in some cases produce undesirable behavior. Here, we investigate the performance of Minimum Probability Flow (MPF) learning for training RBMs. Unlike CD, with its focus on approximating an intractable partition function via Gibbs sampling, MPF proposes a tractable, consistent, objective function defined in terms of a Taylor expansion of the KL divergence with respect to sampling dynamics. Here we propose a more general form for the sampling dynamics in MPF, and explore the consequences of different choices for these dynamics for training RBMs. Experimental results show MPF outperforming CD for various RBM configurations.