Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating images with recurrent adversarial networks
Paper and Code

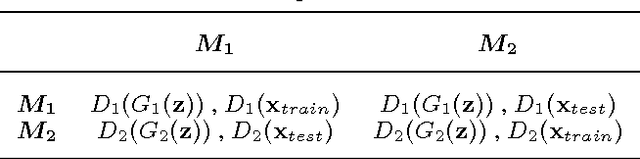
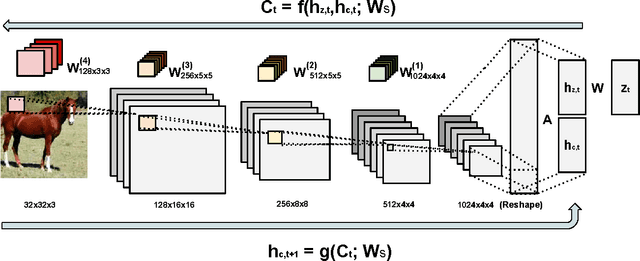
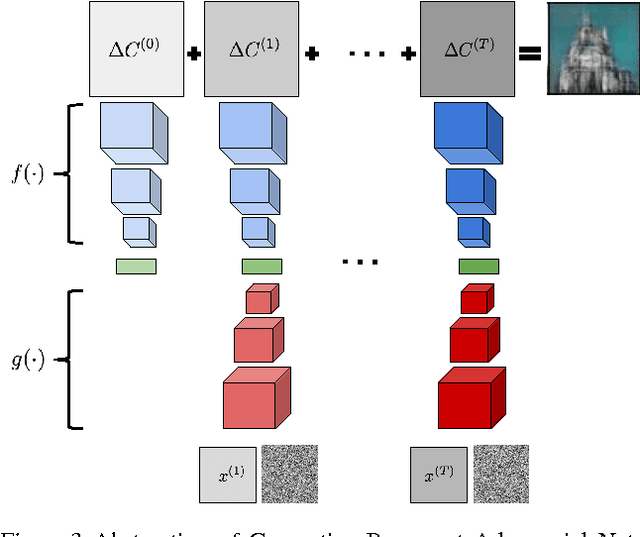
Gatys et al. (2015) showed that optimizing pixels to match features in a convolutional network with respect reference image features is a way to render images of high visual quality. We show that unrolling this gradient-based optimization yields a recurrent computation that creates images by incrementally adding onto a visual "canvas". We propose a recurrent generative model inspired by this view, and show that it can be trained using adversarial training to generate very good image samples. We also propose a way to quantitatively compare adversarial networks by having the generators and discriminators of these networks compete against each other.
View paper on