 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn empirical analysis of the optimization of deep network loss surfaces
Paper and Code
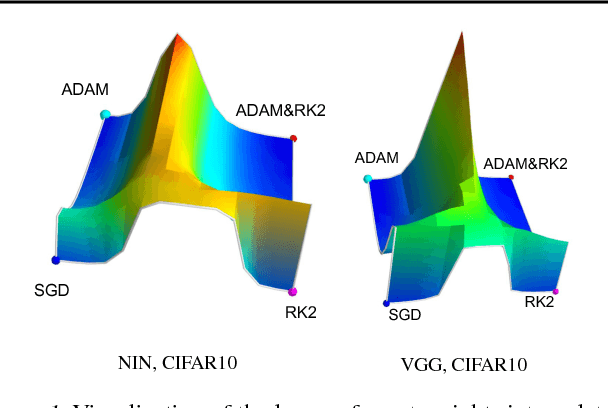
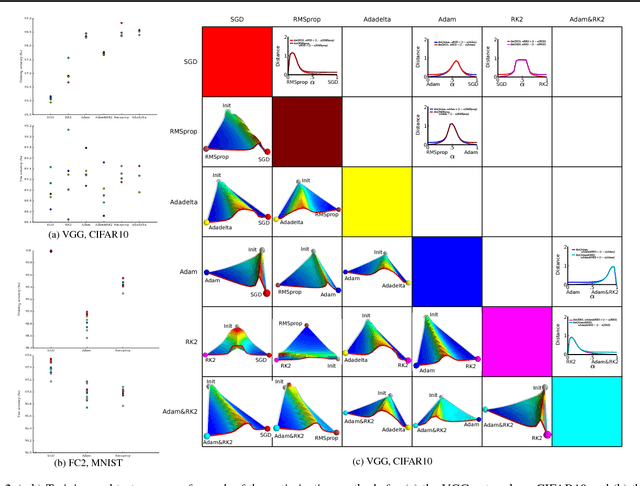
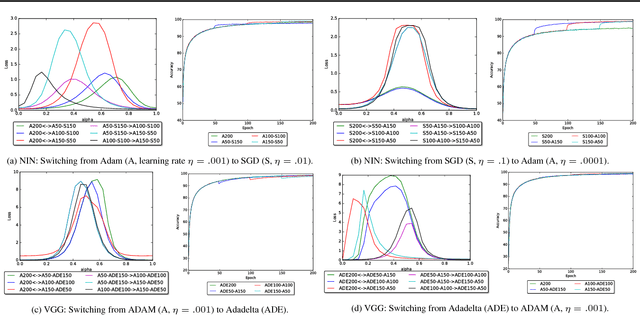
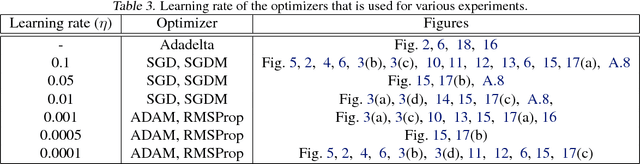
The success of deep neural networks hinges on our ability to accurately and efficiently optimize high-dimensional, non-convex functions. In this paper, we empirically investigate the loss functions of state-of-the-art networks, and how commonly-used stochastic gradient descent variants optimize these loss functions. To do this, we visualize the loss function by projecting them down to low-dimensional spaces chosen based on the convergence points of different optimization algorithms. Our observations suggest that optimization algorithms encounter and choose different descent directions at many saddle points to find different final weights. Based on consistency we observe across re-runs of the same stochastic optimization algorithm, we hypothesize that each optimization algorithm makes characteristic choices at these saddle points.