 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Augmented Control Networks
Feb 14, 2018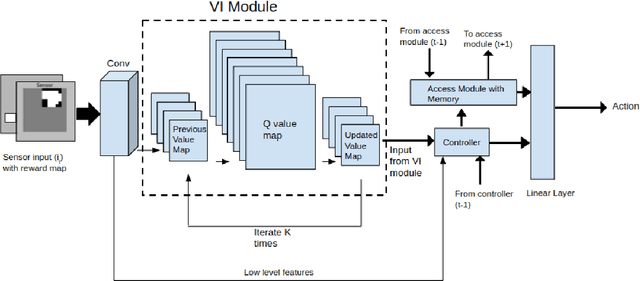
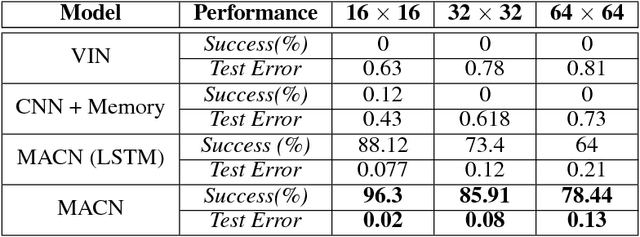

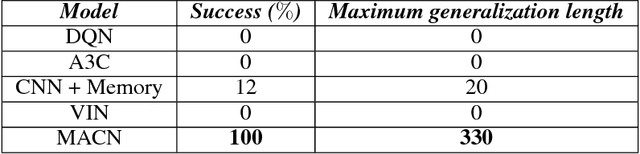
Planning problems in partially observable environments cannot be solved directly with convolutional networks and require some form of memory. But, even memory networks with sophisticated addressing schemes are unable to learn intelligent reasoning satisfactorily due to the complexity of simultaneously learning to access memory and plan. To mitigate these challenges we introduce the Memory Augmented Control Network (MACN). The proposed network architecture consists of three main parts. The first part uses convolutions to extract features and the second part uses a neural network-based planning module to pre-plan in the environment. The third part uses a network controller that learns to store those specific instances of past information that are necessary for planning. The performance of the network is evaluated in discrete grid world environments for path planning in the presence of simple and complex obstacles. We show that our network learns to plan and can generalize to new environments.
End-to-End Navigation in Unknown Environments using Neural Networks
Jul 24, 2017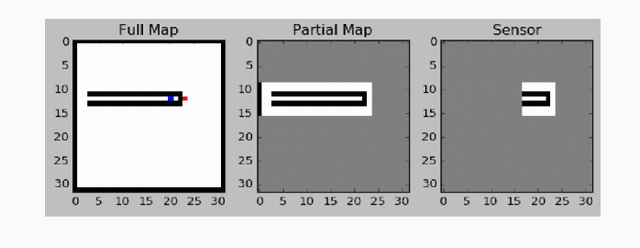
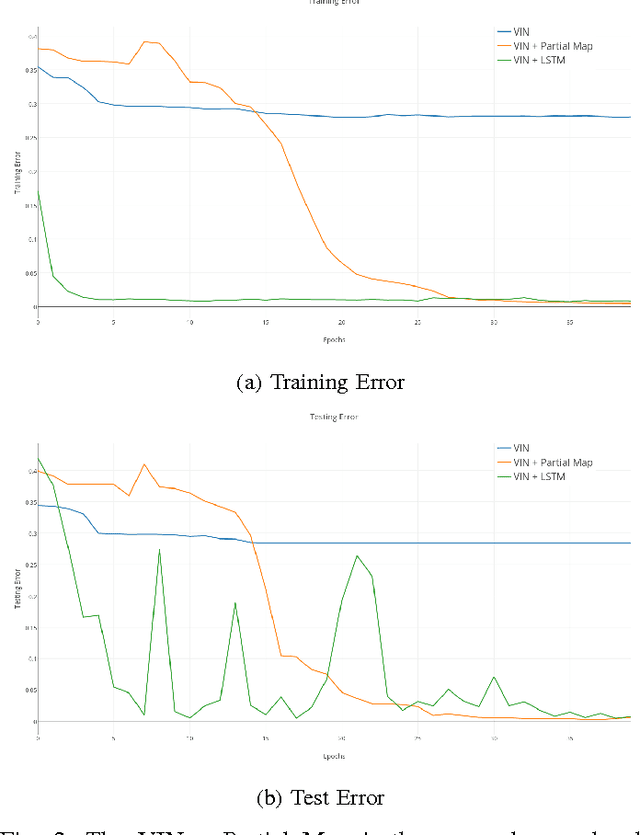
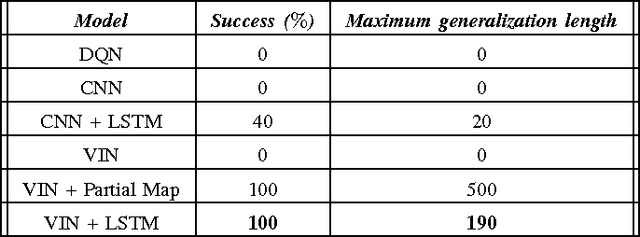
We investigate how a neural network can learn perception actions loops for navigation in unknown environments. Specifically, we consider how to learn to navigate in environments populated with cul-de-sacs that represent convex local minima that the robot could fall into instead of finding a set of feasible actions that take it to the goal. Traditional methods rely on maintaining a global map to solve the problem of over coming a long cul-de-sac. However, due to errors induced from local and global drift, it is highly challenging to maintain such a map for long periods of time. One way to mitigate this problem is by using learning techniques that do not rely on hand engineered map representations and instead output appropriate control policies directly from their sensory input. We first demonstrate that such a problem cannot be solved directly by deep reinforcement learning due to the sparse reward structure of the environment. Further, we demonstrate that deep supervised learning also cannot be used directly to solve this problem. We then investigate network models that offer a combination of reinforcement learning and supervised learning and highlight the significance of adding fully differentiable memory units to such networks. We evaluate our networks on their ability to generalize to new environments and show that adding memory to such networks offers huge jumps in performance
Learning Data Manifolds with a Cutting Plane Method
May 28, 2017We consider the problem of classifying data manifolds where each manifold represents invariances that are parameterized by continuous degrees of freedom. Conventional data augmentation methods rely upon sampling large numbers of training examples from these manifolds; instead, we propose an iterative algorithm called M_{CP} based upon a cutting-plane approach that efficiently solves a quadratic semi-infinite programming problem to find the maximum margin solution. We provide a proof of convergence as well as a polynomial bound on the number of iterations required for a desired tolerance in the objective function. The efficiency and performance of M_{CP} are demonstrated in high-dimensional simulations and on image manifolds generated from the ImageNet dataset. Our results indicate that M_{CP} is able to rapidly learn good classifiers and shows superior generalization performance compared with conventional maximum margin methods using data augmentation methods.
Neural Network Memory Architectures for Autonomous Robot Navigation
May 23, 2017
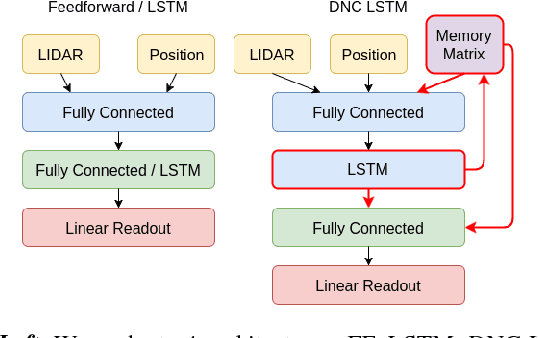

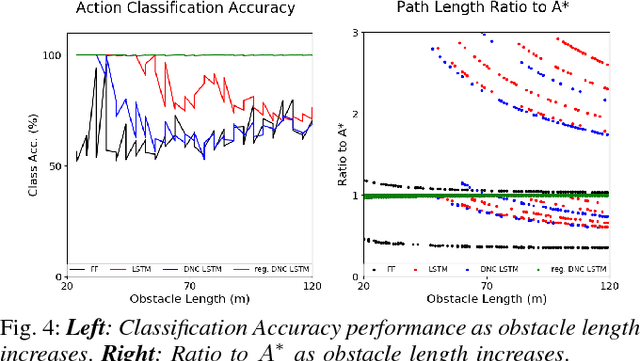
This paper highlights the significance of including memory structures in neural networks when the latter are used to learn perception-action loops for autonomous robot navigation. Traditional navigation approaches rely on global maps of the environment to overcome cul-de-sacs and plan feasible motions. Yet, maintaining an accurate global map may be challenging in real-world settings. A possible way to mitigate this limitation is to use learning techniques that forgo hand-engineered map representations and infer appropriate control responses directly from sensed information. An important but unexplored aspect of such approaches is the effect of memory on their performance. This work is a first thorough study of memory structures for deep-neural-network-based robot navigation, and offers novel tools to train such networks from supervision and quantify their ability to generalize to unseen scenarios. We analyze the separation and generalization abilities of feedforward, long short-term memory, and differentiable neural computer networks. We introduce a new method to evaluate the generalization ability by estimating the VC-dimension of networks with a final linear readout layer. We validate that the VC estimates are good predictors of actual test performance. The reported method can be applied to deep learning problems beyond robotics.
Linear Readout of Object Manifolds
Aug 21, 2016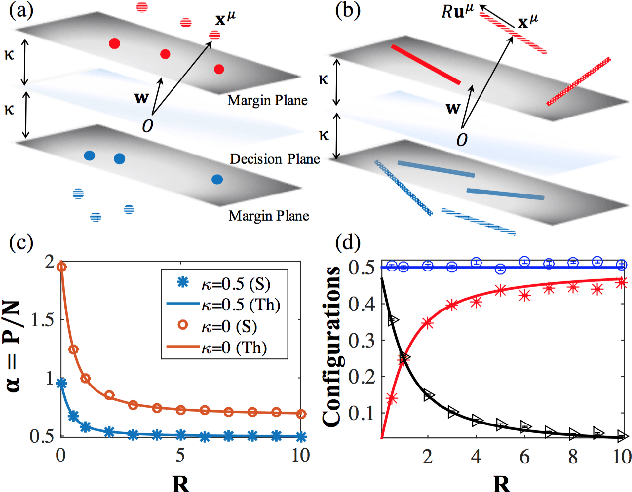
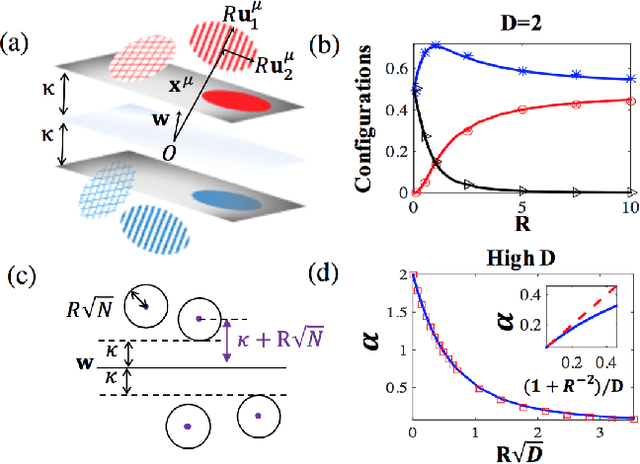
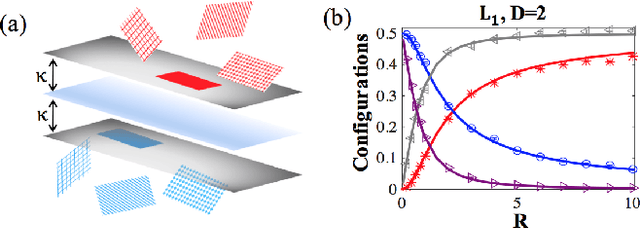
Objects are represented in sensory systems by continuous manifolds due to sensitivity of neuronal responses to changes in physical features such as location, orientation, and intensity. What makes certain sensory representations better suited for invariant decoding of objects by downstream networks? We present a theory that characterizes the ability of a linear readout network, the perceptron, to classify objects from variable neural responses. We show how the readout perceptron capacity depends on the dimensionality, size, and shape of the object manifolds in its input neural representation.
* 5 pages, 3 figures, accepted in Physical Review E as Rapid Communication on 14th May. 2016
Belief Flows of Robust Online Learning
May 26, 2015



This paper introduces a new probabilistic model for online learning which dynamically incorporates information from stochastic gradients of an arbitrary loss function. Similar to probabilistic filtering, the model maintains a Gaussian belief over the optimal weight parameters. Unlike traditional Bayesian updates, the model incorporates a small number of gradient evaluations at locations chosen using Thompson sampling, making it computationally tractable. The belief is then transformed via a linear flow field which optimally updates the belief distribution using rules derived from information theoretic principles. Several versions of the algorithm are shown using different constraints on the flow field and compared with conventional online learning algorithms. Results are given for several classification tasks including logistic regression and multilayer neural networks.
An Adversarial Interpretation of Information-Theoretic Bounded Rationality
Apr 22, 2014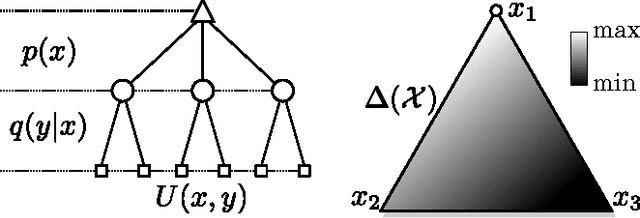
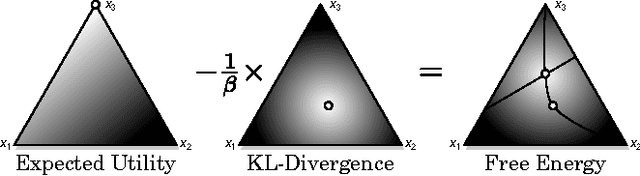
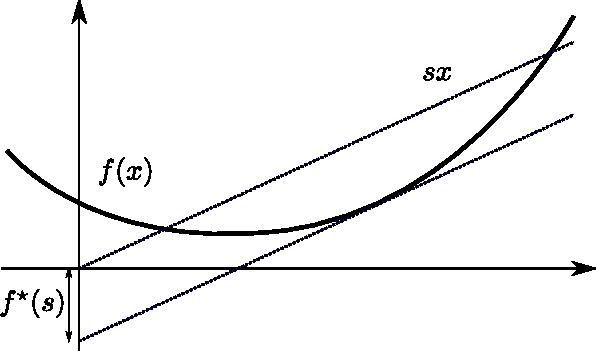
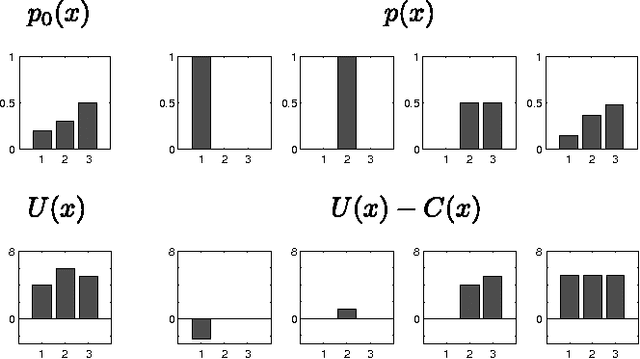
Recently, there has been a growing interest in modeling planning with information constraints. Accordingly, an agent maximizes a regularized expected utility known as the free energy, where the regularizer is given by the information divergence from a prior to a posterior policy. While this approach can be justified in various ways, including from statistical mechanics and information theory, it is still unclear how it relates to decision-making against adversarial environments. This connection has previously been suggested in work relating the free energy to risk-sensitive control and to extensive form games. Here, we show that a single-agent free energy optimization is equivalent to a game between the agent and an imaginary adversary. The adversary can, by paying an exponential penalty, generate costs that diminish the decision maker's payoffs. It turns out that the optimal strategy of the adversary consists in choosing costs so as to render the decision maker indifferent among its choices, which is a definining property of a Nash equilibrium, thus tightening the connection between free energy optimization and game theory.
Learning Discriminative Metrics via Generative Models and Kernel Learning
Sep 19, 2011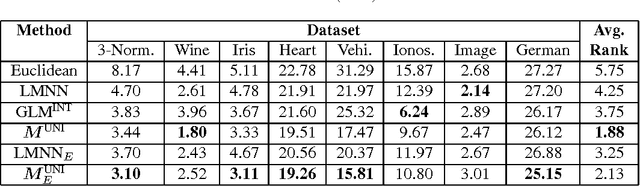
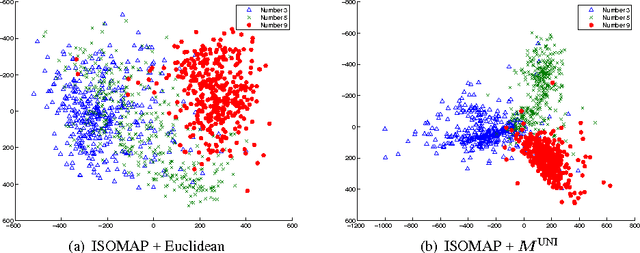
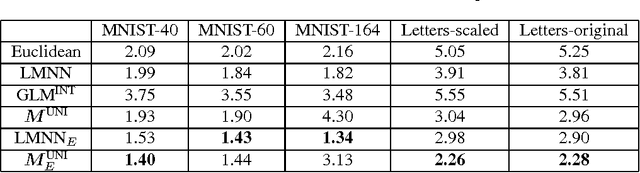

Metrics specifying distances between data points can be learned in a discriminative manner or from generative models. In this paper, we show how to unify generative and discriminative learning of metrics via a kernel learning framework. Specifically, we learn local metrics optimized from parametric generative models. These are then used as base kernels to construct a global kernel that minimizes a discriminative training criterion. We consider both linear and nonlinear combinations of local metric kernels. Our empirical results show that these combinations significantly improve performance on classification tasks. The proposed learning algorithm is also very efficient, achieving order of magnitude speedup in training time compared to previous discriminative baseline methods.