 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting or Guessing? Improving Faithfulness of Event Temporal Relation Extraction
Oct 12, 2022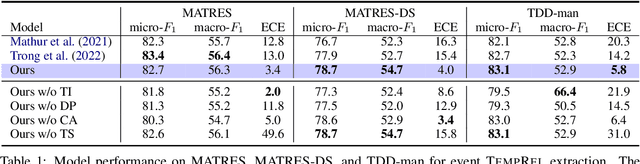
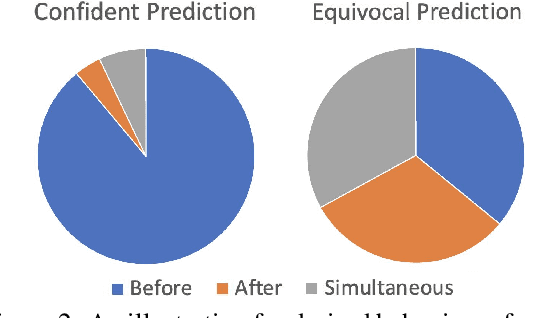
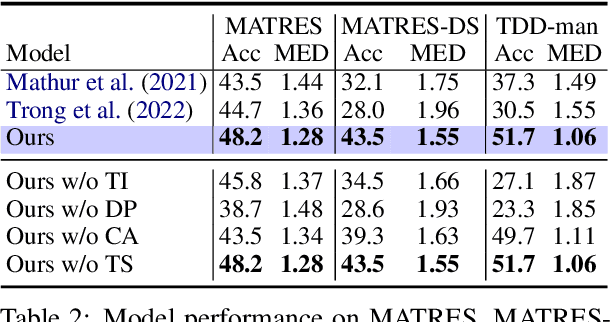
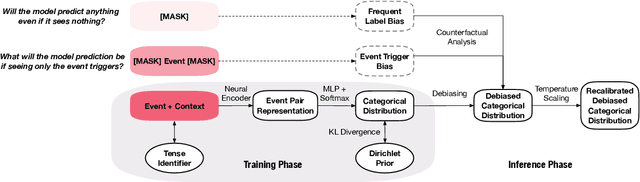
In this paper, we seek to improve the faithfulness of TempRel extraction models from two perspectives. The first perspective is to extract genuinely based on contextual description. To achieve this, we propose to conduct counterfactual analysis to attenuate the effects of two significant types of training biases: the event trigger bias and the frequent label bias. We also add tense information into event representations to explicitly place an emphasis on the contextual description. The second perspective is to provide proper uncertainty estimation and abstain from extraction when no relation is described in the text. By parameterization of Dirichlet Prior over the model-predicted categorical distribution, we improve the model estimates of the correctness likelihood and make TempRel predictions more selective. We also employ temperature scaling to recalibrate the model confidence measure after bias mitigation. Through experimental analysis on MATRES, MATRES-DS, and TDDiscourse, we demonstrate that our model extracts TempRel and timelines more faithfully compared to SOTA methods, especially under distribution shifts.
Are All Steps Equally Important? Benchmarking Essentiality Detection of Events
Oct 12, 2022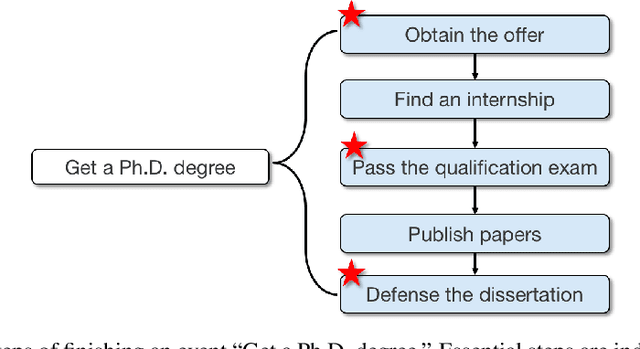

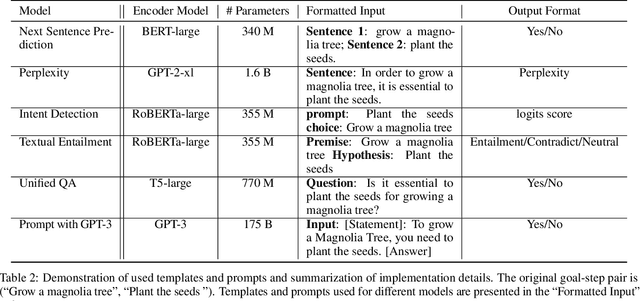
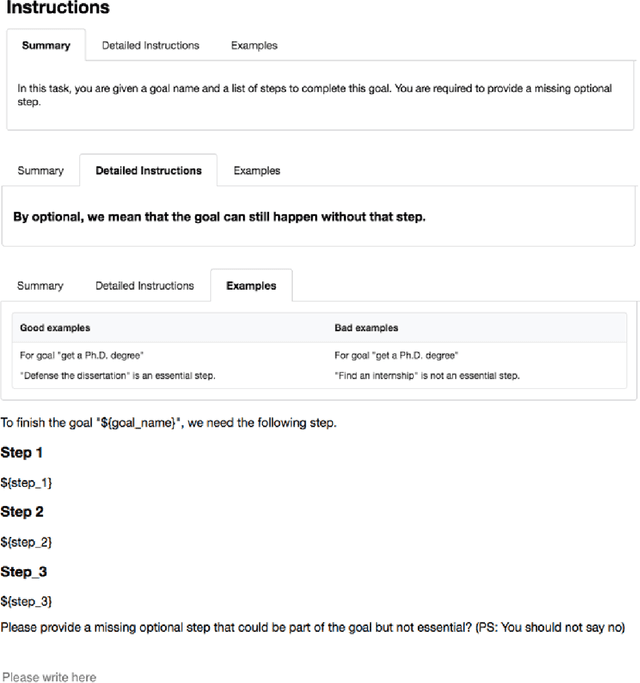
Natural language often describes events in different granularities, such that more coarse-grained (goal) events can often be decomposed into fine-grained sequences of (step) events. A critical but overlooked challenge in understanding an event process lies in the fact that the step events are not equally important to the central goal. In this paper, we seek to fill this gap by studying how well current models can understand the essentiality of different step events towards a goal event. As discussed by cognitive studies, such an ability enables the machine to mimic human's commonsense reasoning about preconditions and necessary efforts of daily-life tasks. Our work contributes with a high-quality corpus of (goal, step) pairs from a community guideline website WikiHow, where the steps are manually annotated with their essentiality w.r.t. the goal. The high IAA indicates that humans have a consistent understanding of the events. Despite evaluating various statistical and massive pre-trained NLU models, we observe that existing SOTA models all perform drastically behind humans, indicating the need for future investigation of this crucial yet challenging task.
Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis
Oct 12, 2022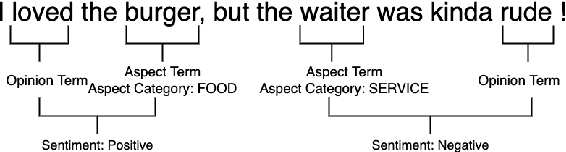
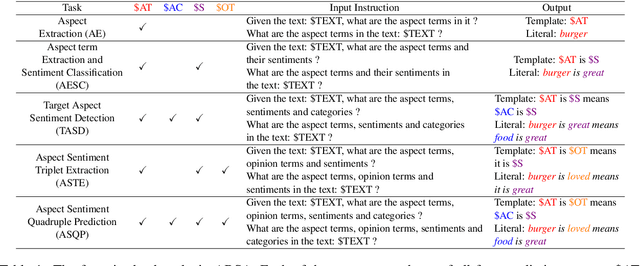
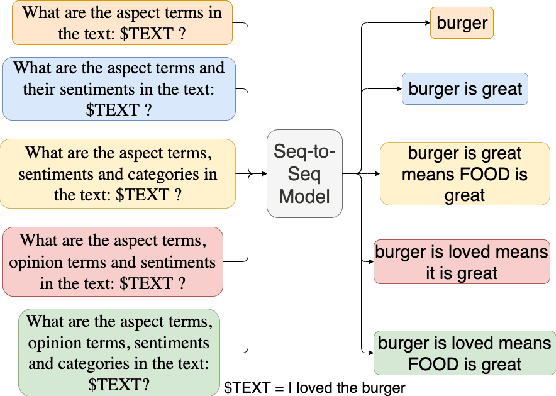
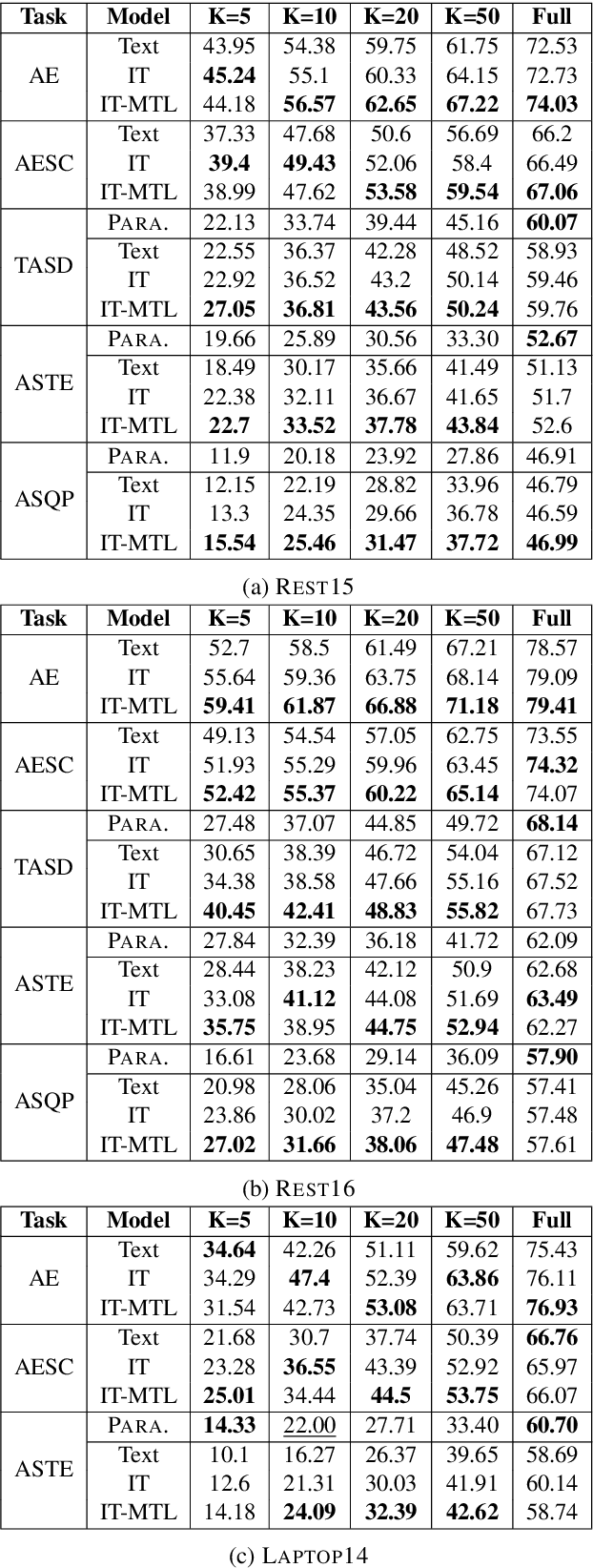
Aspect-based Sentiment Analysis (ABSA) is a fine-grained sentiment analysis task which involves four elements from user-generated texts: aspect term, aspect category, opinion term, and sentiment polarity. Most computational approaches focus on some of the ABSA sub-tasks such as tuple (aspect term, sentiment polarity) or triplet (aspect term, opinion term, sentiment polarity) extraction using either pipeline or joint modeling approaches. Recently, generative approaches have been proposed to extract all four elements as (one or more) quadruplets from text as a single task. In this work, we take a step further and propose a unified framework for solving ABSA, and the associated sub-tasks to improve the performance in few-shot scenarios. To this end, we fine-tune a T5 model with instructional prompts in a multi-task learning fashion covering all the sub-tasks, as well as the entire quadruple prediction task. In experiments with multiple benchmark data sets, we show that the proposed multi-task prompting approach brings performance boost (by absolute $6.75$ F1) in the few-shot learning setting.
CIKQA: Learning Commonsense Inference with a Unified Knowledge-in-the-loop QA Paradigm
Oct 12, 2022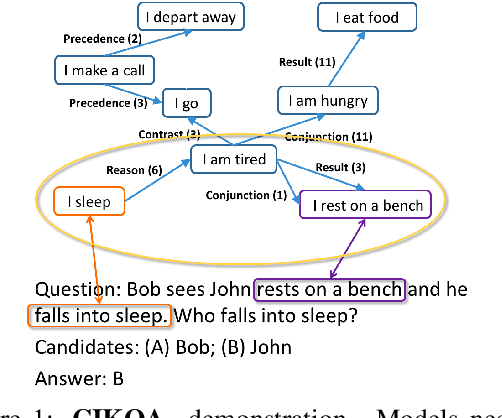
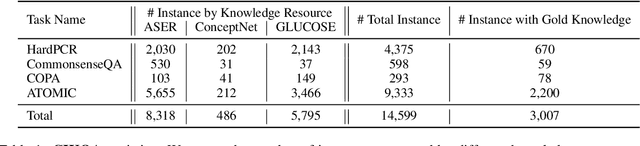

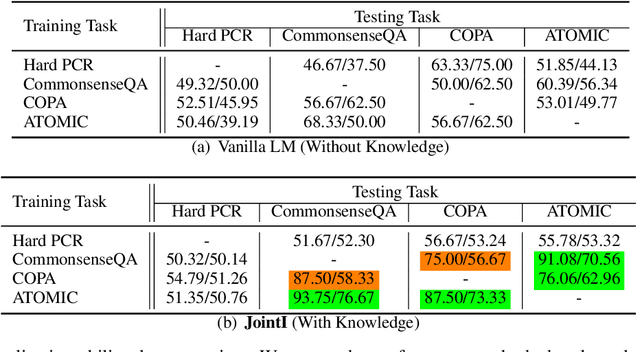
Recently, the community has achieved substantial progress on many commonsense reasoning benchmarks. However, it is still unclear what is learned from the training process: the knowledge, inference capability, or both? We argue that due to the large scale of commonsense knowledge, it is infeasible to annotate a large enough training set for each task to cover all commonsense for learning. Thus we should separate the commonsense knowledge acquisition and inference over commonsense knowledge as two separate tasks. In this work, we focus on investigating models' commonsense inference capabilities from two perspectives: (1) Whether models can know if the knowledge they have is enough to solve the task; (2) Whether models can develop commonsense inference capabilities that generalize across commonsense tasks. We first align commonsense tasks with relevant knowledge from commonsense knowledge bases and ask humans to annotate whether the knowledge is enough or not. Then, we convert different commonsense tasks into a unified question answering format to evaluate models' generalization capabilities. We name the benchmark as Commonsense Inference with Knowledge-in-the-loop Question Answering (CIKQA).
Cross-Lingual Speaker Identification Using Distant Supervision
Oct 11, 2022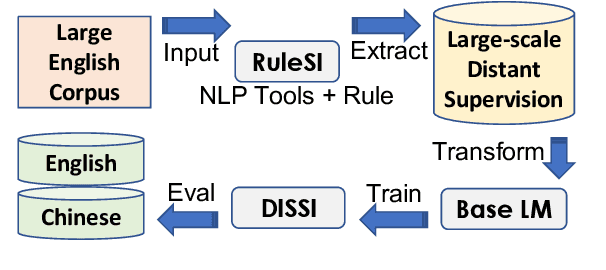

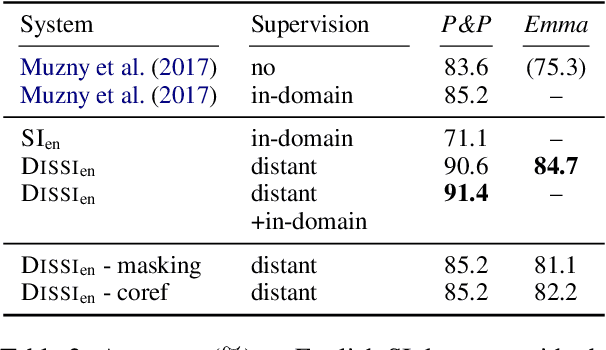

Speaker identification, determining which character said each utterance in literary text, benefits many downstream tasks. Most existing approaches use expert-defined rules or rule-based features to directly approach this task, but these approaches come with significant drawbacks, such as lack of contextual reasoning and poor cross-lingual generalization. In this work, we propose a speaker identification framework that addresses these issues. We first extract large-scale distant supervision signals in English via general-purpose tools and heuristics, and then apply these weakly-labeled instances with a focus on encouraging contextual reasoning to train a cross-lingual language model. We show that the resulting model outperforms previous state-of-the-art methods on two English speaker identification benchmarks by up to 9% in accuracy and 5% with only distant supervision, as well as two Chinese speaker identification datasets by up to 4.7%.
Unsupervised Neural Stylistic Text Generation using Transfer learning and Adapters
Oct 07, 2022

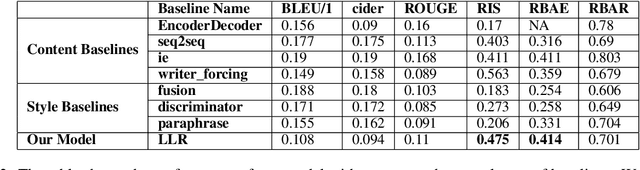

Research has shown that personality is a key driver to improve engagement and user experience in conversational systems. Conversational agents should also maintain a consistent persona to have an engaging conversation with a user. However, text generation datasets are often crowd sourced and thereby have an averaging effect where the style of the generation model is an average style of all the crowd workers that have contributed to the dataset. While one can collect persona-specific datasets for each task, it would be an expensive and time consuming annotation effort. In this work, we propose a novel transfer learning framework which updates only $0.3\%$ of model parameters to learn style specific attributes for response generation. For the purpose of this study, we tackle the problem of stylistic story ending generation using the ROC stories Corpus. We learn style specific attributes from the PERSONALITY-CAPTIONS dataset. Through extensive experiments and evaluation metrics we show that our novel training procedure can improve the style generation by 200 over Encoder-Decoder baselines while maintaining on-par content relevance metrics with
Human-guided Collaborative Problem Solving: A Natural Language based Framework
Jul 19, 2022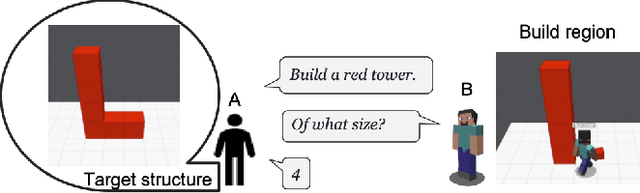
We consider the problem of human-machine collaborative problem solving as a planning task coupled with natural language communication. Our framework consists of three components -- a natural language engine that parses the language utterances to a formal representation and vice-versa, a concept learner that induces generalized concepts for plans based on limited interactions with the user, and an HTN planner that solves the task based on human interaction. We illustrate the ability of this framework to address the key challenges of collaborative problem solving by demonstrating it on a collaborative building task in a Minecraft-based blocksworld domain. The accompanied demo video is available at https://youtu.be/q1pWe4aahF0.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022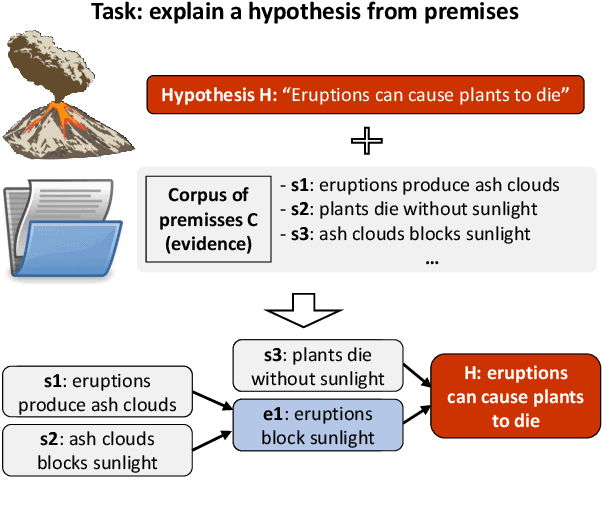
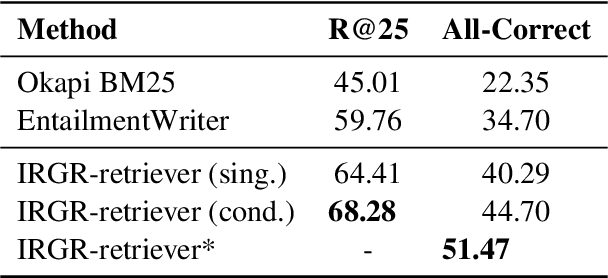
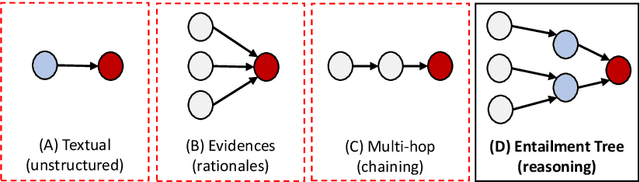
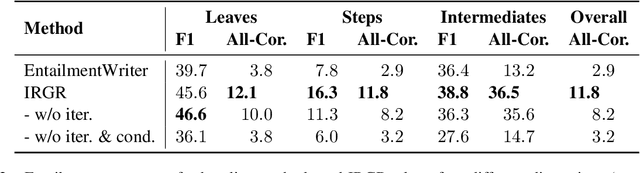
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Repro: An Open-Source Library for Improving the Reproducibility and Usability of Publicly Available Research Code
Apr 29, 2022
We introduce Repro, an open-source library which aims at improving the reproducibility and usability of research code. The library provides a lightweight Python API for running software released by researchers within Docker containers which contain the exact required runtime configuration and dependencies for the code. Because the environment setup for each package is handled by Docker, users do not have to do any configuration themselves. Once Repro is installed, users can run the code for the 30+ papers currently supported by the library. We hope researchers see the value provided to others by including their research code in Repro and consider adding support for their own research code.