 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
PLaMo-100B: A Ground-Up Language Model Designed for Japanese Proficiency
Oct 10, 2024



We introduce PLaMo-100B, a large-scale language model designed for Japanese proficiency. The model was trained from scratch using 2 trillion tokens, with architecture such as QK Normalization and Z-Loss to ensure training stability during the training process. Post-training techniques, including Supervised Fine-Tuning and Direct Preference Optimization, were applied to refine the model's performance. Benchmark evaluations suggest that PLaMo-100B performs well, particularly in Japanese-specific tasks, achieving results that are competitive with frontier models like GPT-4.
A Scaling Law for Synthetic-to-Real Transfer: A Measure of Pre-Training
Aug 25, 2021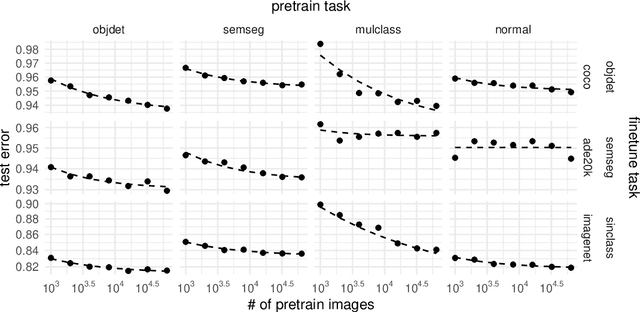

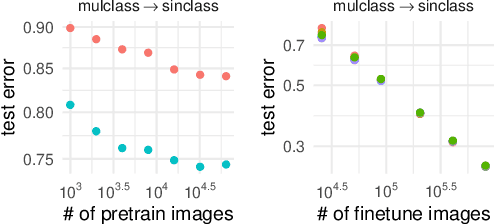
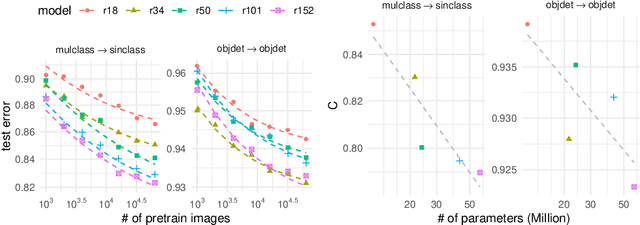
Synthetic-to-real transfer learning is a framework in which we pre-train models with synthetically generated images and ground-truth annotations for real tasks. Although synthetic images overcome the data scarcity issue, it remains unclear how the fine-tuning performance scales with pre-trained models, especially in terms of pre-training data size. In this study, we collect a number of empirical observations and uncover the secret. Through experiments, we observe a simple and general scaling law that consistently describes learning curves in various tasks, models, and complexities of synthesized pre-training data. Further, we develop a theory of transfer learning for a simplified scenario and confirm that the derived generalization bound is consistent with our empirical findings.