 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing and Aggregating Clients with Class Distribution for Personalized Federated Learning
Jun 12, 2024Personalized federated learning (PFL) enables customized models for clients with varying data distributions. However, existing PFL methods often incur high computational and communication costs, limiting their practical application. This paper proposes a novel PFL method, Class-wise Federated Averaging (cwFedAVG), that performs Federated Averaging (FedAVG) class-wise, creating multiple global models per class on the server. Each local model integrates these global models weighted by its estimated local class distribution, derived from the L2-norms of deep network weights, avoiding privacy violations. Afterward, each global model does the same with local models using the same method. We also newly designed Weight Distribution Regularizer (WDR) to further enhance the accuracy of estimating a local class distribution by minimizing the Euclidean distance between the class distribution and the weight norms' distribution. Experimental results demonstrate that cwFedAVG matches or outperforms several existing PFL methods. Notably, cwFedAVG is conceptually simple yet computationally efficient as it mitigates the need for extensive calculation to collaborate between clients by leveraging shared global models. Visualizations provide insights into how cwFedAVG enables local model specialization on respective class distributions while global models capture class-relevant information across clients.
DEEP-BO for Hyperparameter Optimization of Deep Networks
May 23, 2019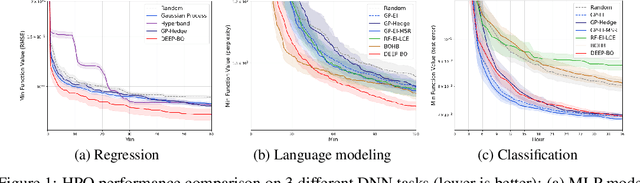

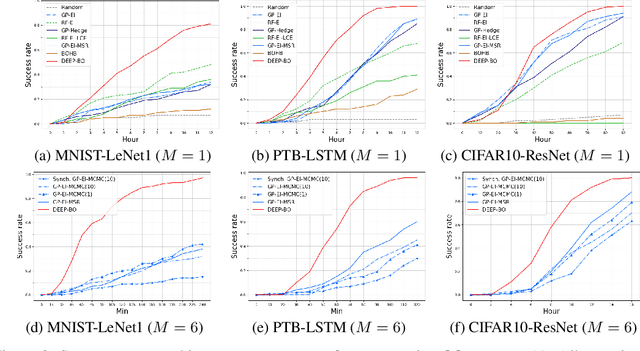
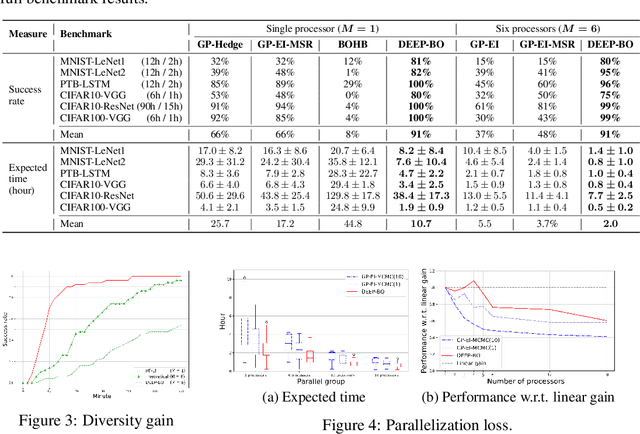
The performance of deep neural networks (DNN) is very sensitive to the particular choice of hyper-parameters. To make it worse, the shape of the learning curve can be significantly affected when a technique like batchnorm is used. As a result, hyperparameter optimization of deep networks can be much more challenging than traditional machine learning models. In this work, we start from well known Bayesian Optimization solutions and provide enhancement strategies specifically designed for hyperparameter optimization of deep networks. The resulting algorithm is named as DEEP-BO (Diversified, Early-termination-Enabled, and Parallel Bayesian Optimization). When evaluated over six DNN benchmarks, DEEP-BO easily outperforms or shows comparable performance with some of the well-known solutions including GP-Hedge, Hyperband, BOHB, Median Stopping Rule, and Learning Curve Extrapolation. The code used is made publicly available at https://github.com/snu-adsl/DEEP-BO.
On the Statistical and Information-theoretic Characteristics of Deep Network Representations
Nov 08, 2018
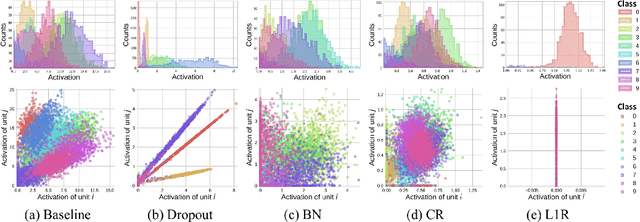
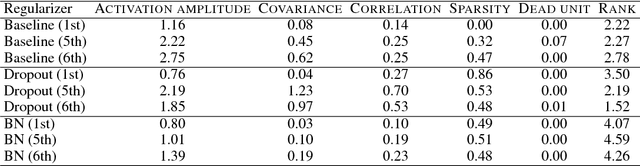
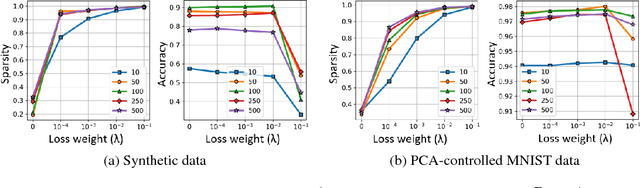
It has been common to argue or imply that a regularizer can be used to alter a statistical property of a hidden layer's representation and thus improve generalization or performance of deep networks. For instance, dropout has been known to improve performance by reducing co-adaptation, and representational sparsity has been argued as a good characteristic because many data-generation processes have a small number of factors that are independent. In this work, we analytically and empirically investigate the popular characteristics of learned representations, including correlation, sparsity, dead unit, rank, and mutual information, and disprove many of the \textit{conventional wisdom}. We first show that infinitely many Identical Output Networks (IONs) can be constructed for any deep network with a linear layer, where any invertible affine transformation can be applied to alter the layer's representation characteristics. The existence of ION proves that the correlation characteristics of representation is irrelevant to the performance. Extensions to ReLU layers are provided, too. Then, we consider sparsity, dead unit, and rank to show that only loose relationships exist among the three characteristics. It is shown that a higher sparsity or additional dead units do not imply a better or worse performance when the rank of representation is fixed. We also develop a rank regularizer and show that neither representation sparsity nor lower rank is helpful for improving performance even when the data-generation process has a small number of independent factors. Mutual information $I(\mathbf{z}_l;\mathbf{x})$ and $I(\mathbf{z}_l;\mathbf{y})$ are investigated, and we show that regularizers can affect $I(\mathbf{z}_l;\mathbf{x})$ and thus indirectly influence the performance. Finally, we explain how a rich set of regularizers can be used as a powerful tool for performance tuning.
Utilizing Class Information for DNN Representation Shaping
Sep 25, 2018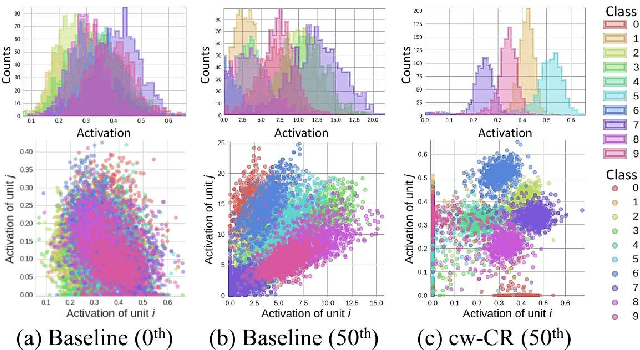

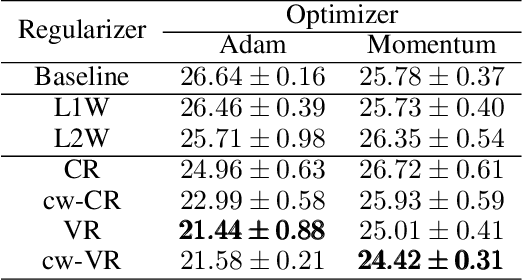
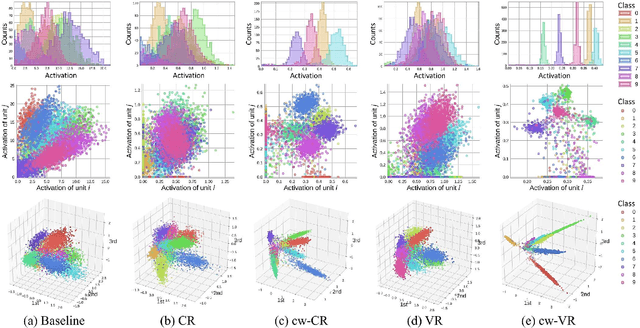
Statistical characteristics of DNN (Deep Neural Network) representations, such as sparsity and correlation, are known to be relevant to the performance and interpretability of deep learning. When a statistical characteristic is desired, often an adequate regularizer can be designed and applied during the training phase. Typically, such a regularizer aims to manipulate a statistical characteristic over all classes together. For classification tasks, however, it might be advantageous to enforce the desired characteristic per class such that different classes can be better distinguished. Motivated by the idea, we design two class-wise regularizers that explicitly utilize class information: class-wise Covariance Regularizer (cw-CR) and class-wise Variance Regularizer (cw-VR). cw-CR targets to reduce the covariance of representations calculated from the same class samples. cw-VR is similar, but variance instead of covariance is targeted. For the sake of completeness, their counterparts without using class information, Covariance Regularizer (CR) and Variance Regularizer (VR), are considered together. The four regularizers are conceptually simple and computationally very efficient, and the visualization shows that the regularizers indeed perform distinct representation shaping. In terms of classification performance, significant improvements over the baseline and L1/L2 weight decay methods were found for 20 out of 21 tasks over popular benchmark datasets. In particular, cw-VR achieved the best performance for 12 tasks.