 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial collision attacks on image hashing functions
Nov 18, 2020
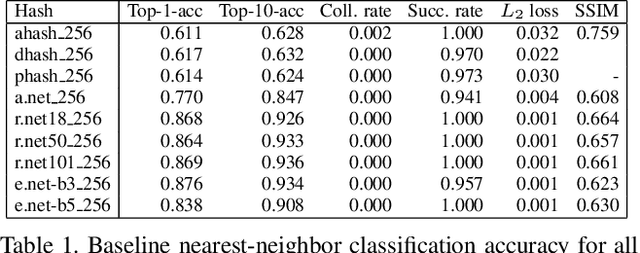
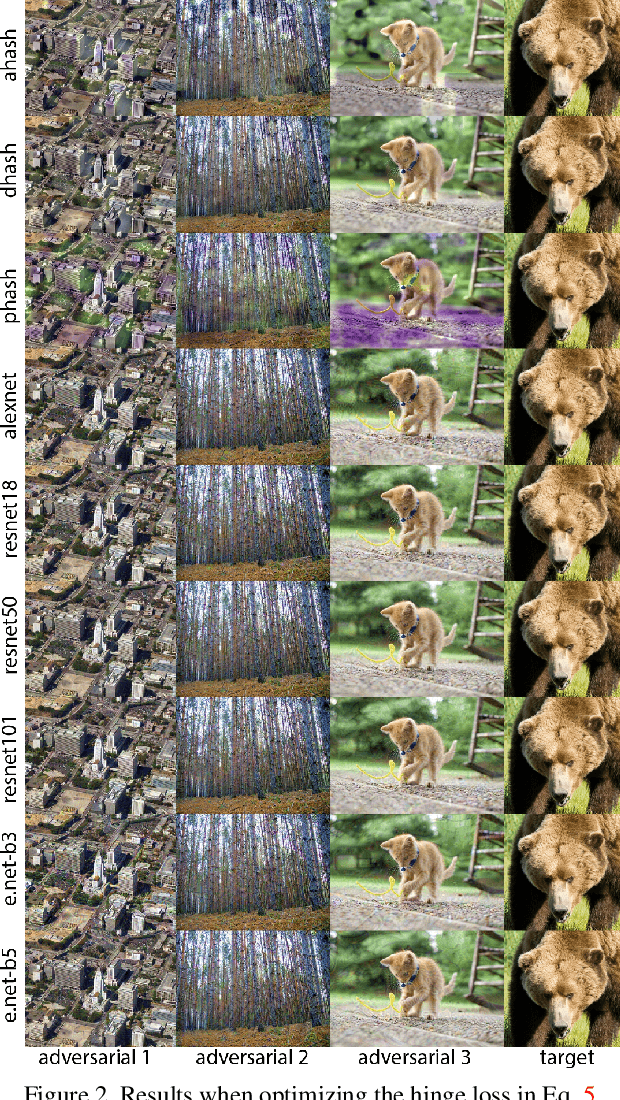
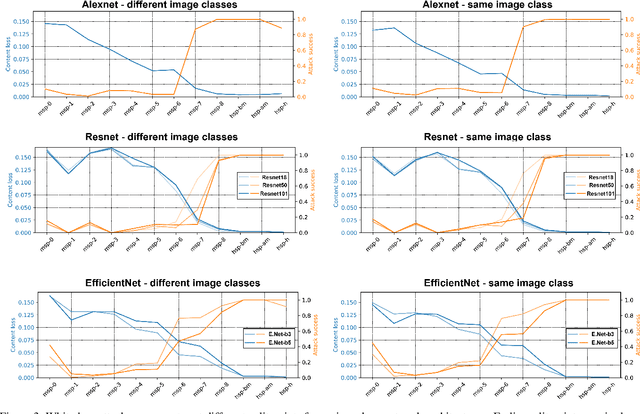
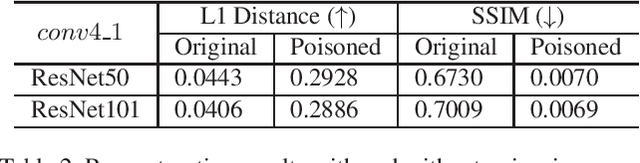
Hashing images with a perceptual algorithm is a common approach to solving duplicate image detection problems. However, perceptual image hashing algorithms are differentiable, and are thus vulnerable to gradient-based adversarial attacks. We demonstrate that not only is it possible to modify an image to produce an unrelated hash, but an exact image hash collision between a source and target image can be produced via minuscule adversarial perturbations. In a white box setting, these collisions can be replicated across nearly every image pair and hash type (including both deep and non-learned hashes). Furthermore, by attacking points other than the output of a hashing function, an attacker can avoid having to know the details of a particular algorithm, resulting in collisions that transfer across different hash sizes or model architectures. Using these techniques, an adversary can poison the image lookup table of a duplicate image detection service, resulting in undefined or unwanted behavior. Finally, we offer several potential mitigations to gradient-based image hash attacks.
Preserving Integrity in Online Social Networks
Sep 25, 2020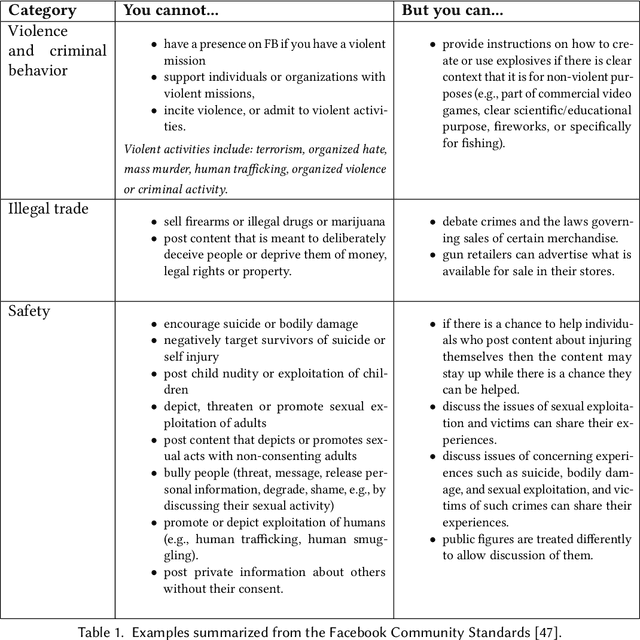
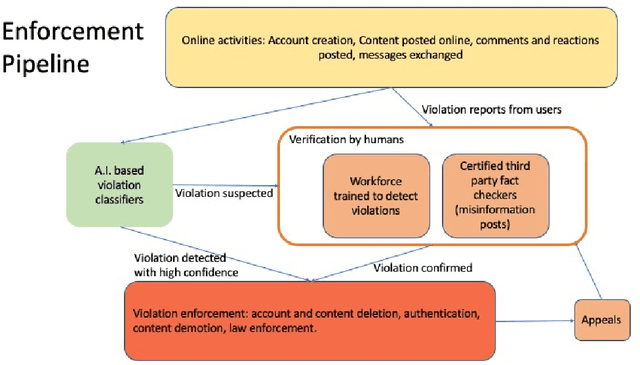
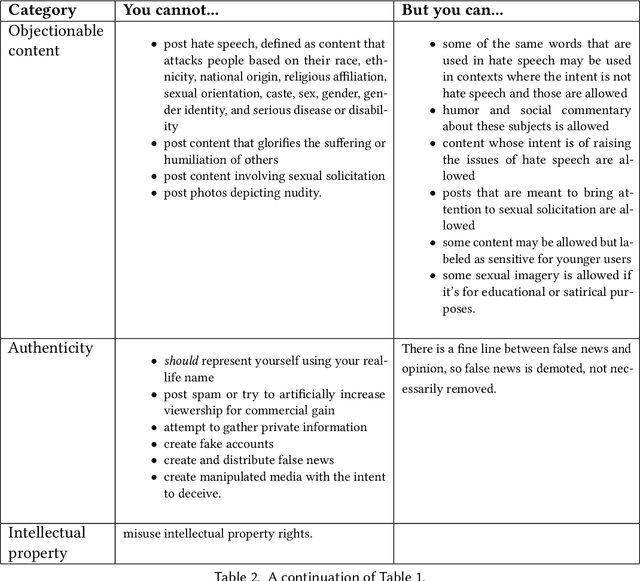
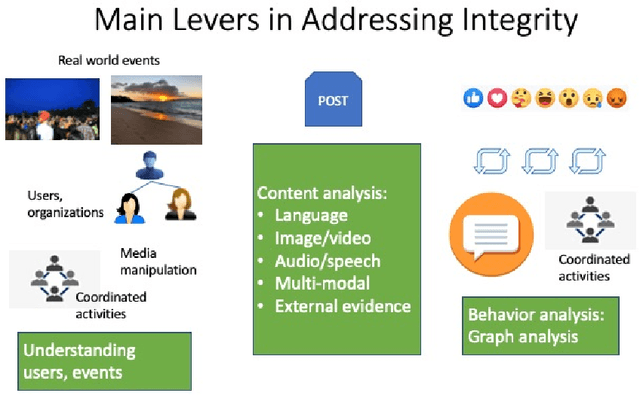
Online social networks provide a platform for sharing information and free expression. However, these networks are also used for malicious purposes, such as distributing misinformation and hate speech, selling illegal drugs, and coordinating sex trafficking or child exploitation. This paper surveys the state of the art in keeping online platforms and their users safe from such harm, also known as the problem of preserving integrity. This survey comes from the perspective of having to combat a broad spectrum of integrity violations at Facebook. We highlight the techniques that have been proven useful in practice and that deserve additional attention from the academic community. Instead of discussing the many individual violation types, we identify key aspects of the social-media eco-system, each of which is common to a wide variety violation types. Furthermore, each of these components represents an area for research and development, and the innovations that are found can be applied widely.
The DeepFake Detection Challenge Dataset
Jun 25, 2020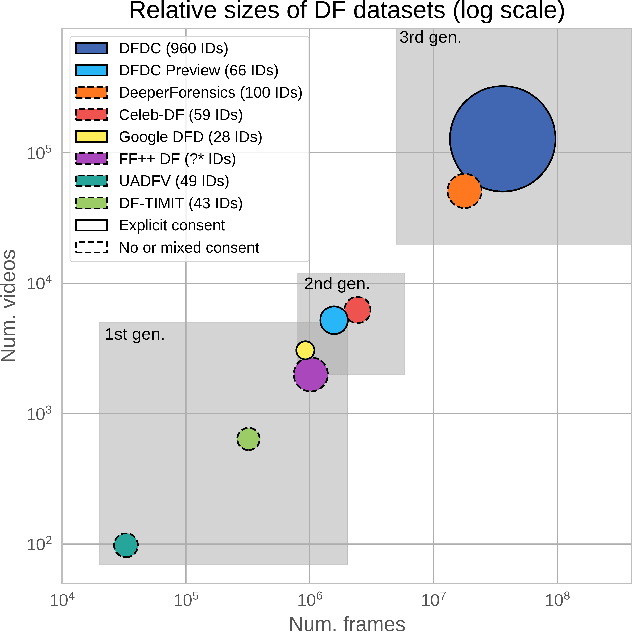
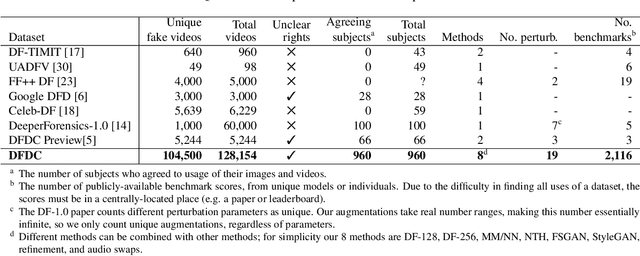

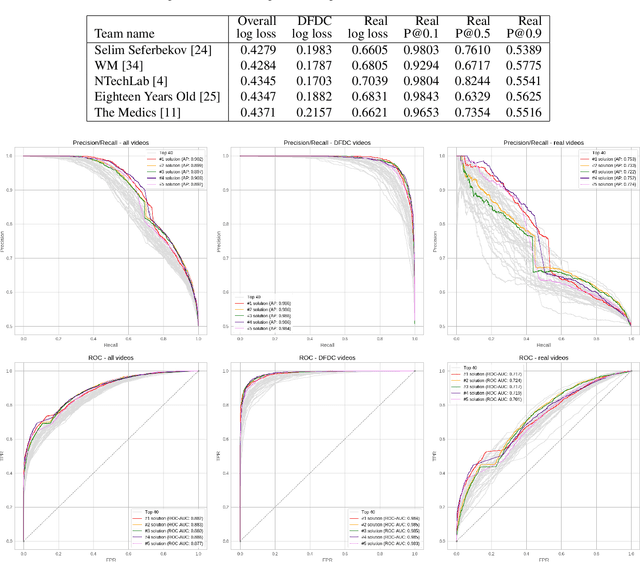
Deepfakes are a recent off-the-shelf manipulation technique that allows anyone to swap two identities in a single video. In addition to Deepfakes, a variety of GAN-based face swapping methods have also been published with accompanying code. To counter this emerging threat, we have constructed an extremely large face swap video dataset to enable the training of detection models, and organized the accompanying DeepFake Detection Challenge (DFDC) Kaggle competition. Importantly, all recorded subjects agreed to participate in and have their likenesses modified during the construction of the face-swapped dataset. The DFDC dataset is by far the largest currently and publicly available face swap video dataset, with over 100,000 total clips sourced from 3,426 paid actors, produced with several Deepfake, GAN-based, and non-learned methods. In addition to describing the methods used to construct the dataset, we provide a detailed analysis of the top submissions from the Kaggle contest. We show although Deepfake detection is extremely difficult and still an unsolved problem, a Deepfake detection model trained only on the DFDC can generalize to real "in-the-wild" Deepfake videos, and such a model can be a valuable analysis tool when analyzing potentially Deepfaked videos. Training, validation and testing corpuses can be downloaded from https://ai.facebook.com/datasets/dfdc.
Deep Poisoning Functions: Towards Robust Privacy-safe Image Data Sharing
Dec 14, 2019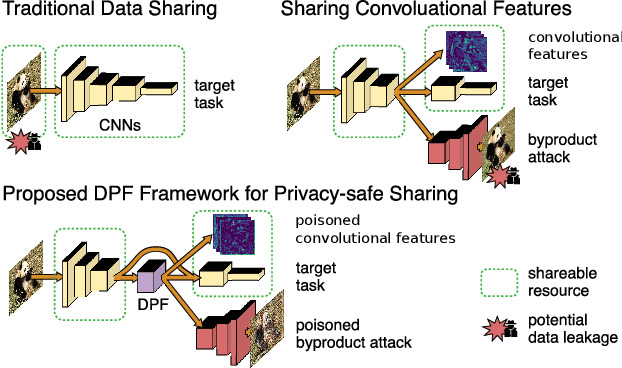
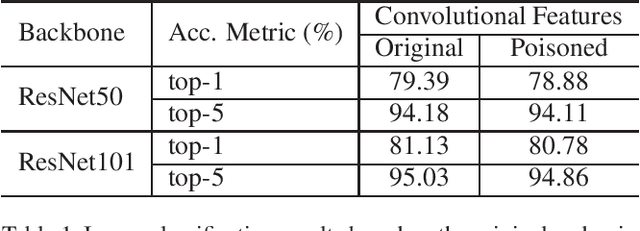
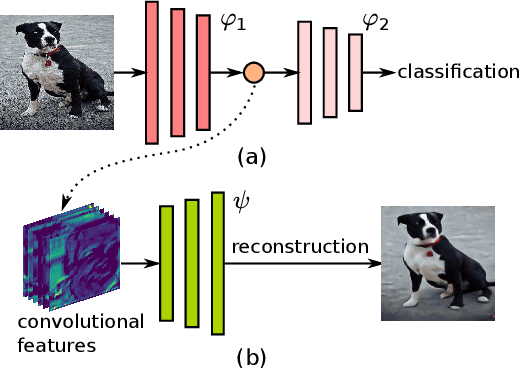
As deep networks are applied to an ever-expanding set of computer vision tasks, protecting general privacy in image data has become a critically important goal. This paper presents a new framework for privacy-preserving data sharing that is robust to adversarial attacks and overcomes the known issues existing in previous approaches. We introduce the concept of a Deep Poisoning Function (DPF), which is a module inserted into a pre-trained deep network designed to perform a specific vision task. The DPF is optimized to deliberately poison image data to prevent known adversarial attacks, while ensuring that the altered image data is functionally equivalent to the non-poisoned data for the original task. Given this equivalence, both poisoned and non-poisoned data can be used for further retraining or fine-tuning. Experimental results on image classification and face recognition tasks prove the efficacy of the proposed method.
The Deepfake Detection Challenge (DFDC) Preview Dataset
Oct 23, 2019


In this paper, we introduce a preview of the Deepfakes Detection Challenge (DFDC) dataset consisting of 5K videos featuring two facial modification algorithms. A data collection campaign has been carried out where participating actors have entered into an agreement to the use and manipulation of their likenesses in our creation of the dataset. Diversity in several axes (gender, skin-tone, age, etc.) has been considered and actors recorded videos with arbitrary backgrounds thus bringing visual variability. Finally, a set of specific metrics to evaluate the performance have been defined and two existing models for detecting deepfakes have been tested to provide a reference performance baseline. The DFDC dataset preview can be downloaded at: deepfakedetectionchallenge.ai
Hate Speech in Pixels: Detection of Offensive Memes towards Automatic Moderation
Oct 05, 2019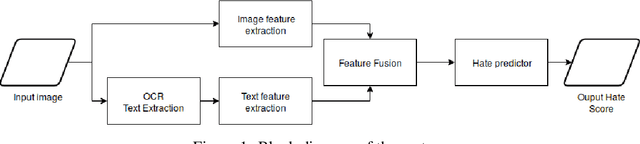
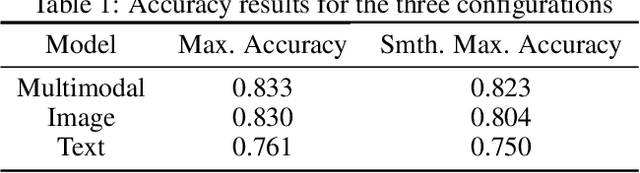
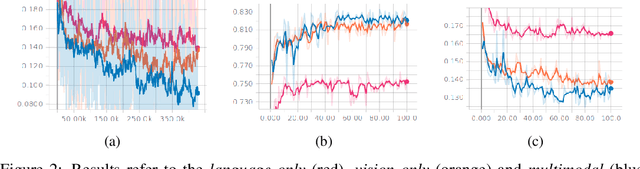

This work addresses the challenge of hate speech detection in Internet memes, and attempts using visual information to automatically detect hate speech, unlike any previous work of our knowledge. Memes are pixel-based multimedia documents that contain photos or illustrations together with phrases which, when combined, usually adopt a funny meaning. However, hate memes are also used to spread hate through social networks, so their automatic detection would help reduce their harmful societal impact. Our results indicate that the model can learn to detect some of the memes, but that the task is far from being solved with this simple architecture. While previous work focuses on linguistic hate speech, our experiments indicate how the visual modality can be much more informative for hate speech detection than the linguistic one in memes. In our experiments, we built a dataset of 5,020 memes to train and evaluate a multi-layer perceptron over the visual and language representations, whether independently or fused. The source code and mode and models are available https://github.com/imatge-upc/hate-speech-detection .
SalGAN: Visual Saliency Prediction with Generative Adversarial Networks
Jul 01, 2018
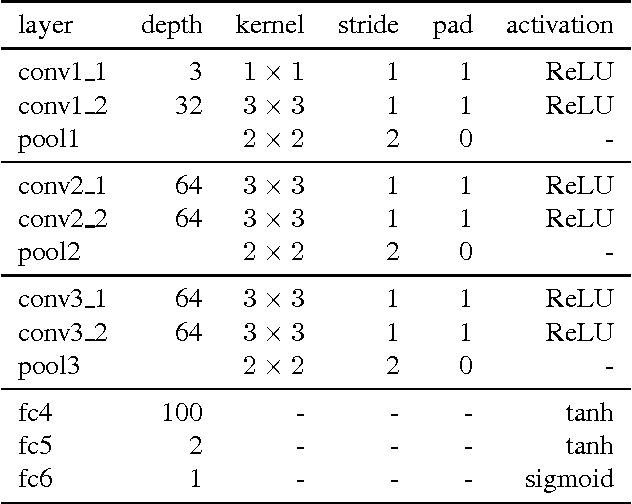
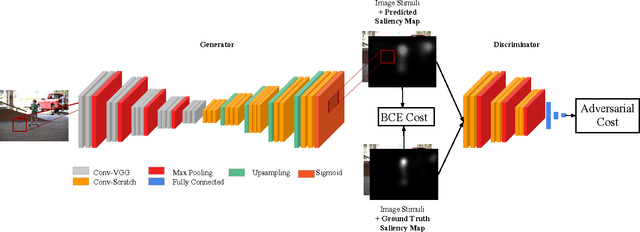
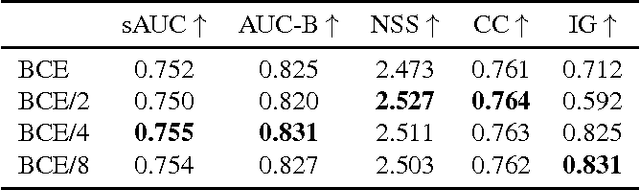
We introduce SalGAN, a deep convolutional neural network for visual saliency prediction trained with adversarial examples. The first stage of the network consists of a generator model whose weights are learned by back-propagation computed from a binary cross entropy (BCE) loss over downsampled versions of the saliency maps. The resulting prediction is processed by a discriminator network trained to solve a binary classification task between the saliency maps generated by the generative stage and the ground truth ones. Our experiments show how adversarial training allows reaching state-of-the-art performance across different metrics when combined with a widely-used loss function like BCE. Our results can be reproduced with the source code and trained models available at https://imatge-upc.github.io/saliency-salgan-2017/.
Towards social pattern characterization in egocentric photo-streams
Jan 09, 2018

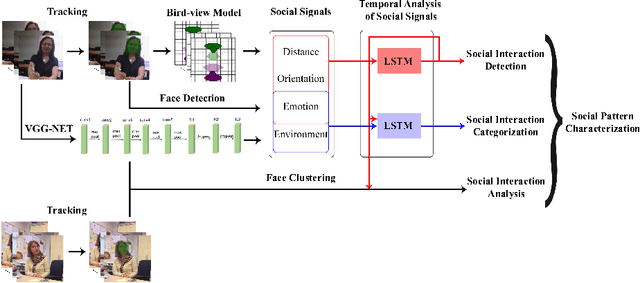
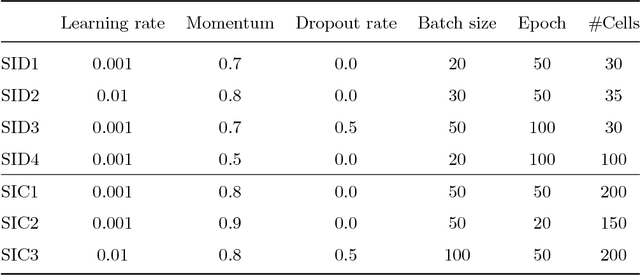
Following the increasingly popular trend of social interaction analysis in egocentric vision, this manuscript presents a comprehensive study for automatic social pattern characterization of a wearable photo-camera user, by relying on the visual analysis of egocentric photo-streams. The proposed framework consists of three major steps. The first step is to detect social interactions of the user where the impact of several social signals on the task is explored. The detected social events are inspected in the second step for categorization into different social meetings. These two steps act at event-level where each potential social event is modeled as a multi-dimensional time-series, whose dimensions correspond to a set of relevant features for each task, and LSTM is employed to classify the time-series. The last step of the framework is to characterize social patterns, which is essentially to infer the diversity and frequency of the social relations of the user through discovery of recurrences of the same people across the whole set of social events of the user. Experimental evaluation over a dataset acquired by 9 users demonstrates promising results on the task of social pattern characterization from egocentric photo-streams.
Eye In-Painting with Exemplar Generative Adversarial Networks
Dec 11, 2017
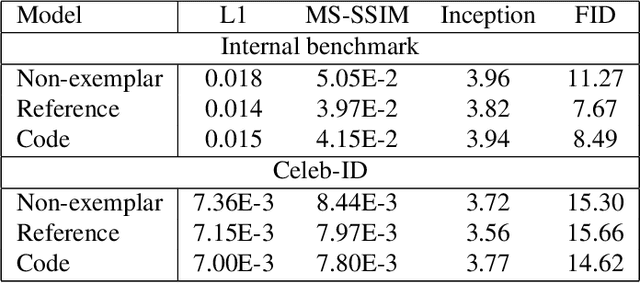
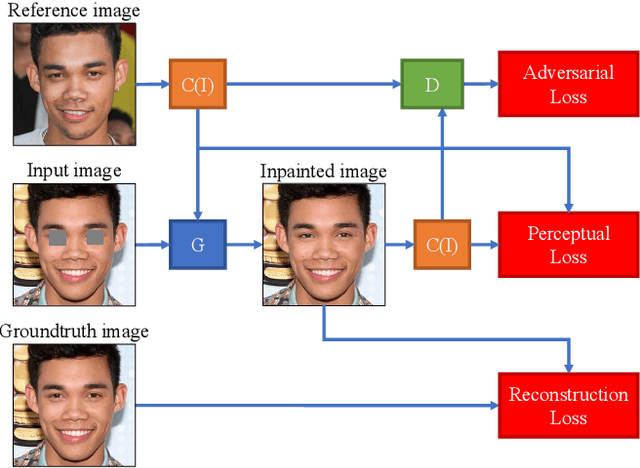
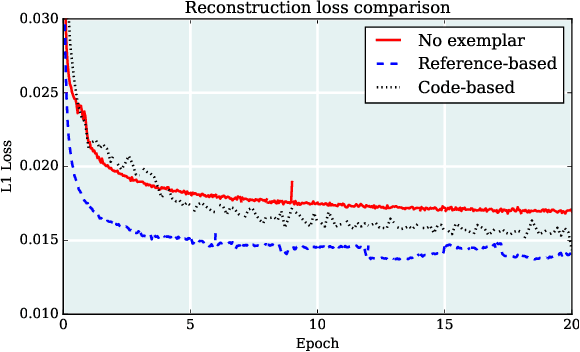
This paper introduces a novel approach to in-painting where the identity of the object to remove or change is preserved and accounted for at inference time: Exemplar GANs (ExGANs). ExGANs are a type of conditional GAN that utilize exemplar information to produce high-quality, personalized in painting results. We propose using exemplar information in the form of a reference image of the region to in-paint, or a perceptual code describing that object. Unlike previous conditional GAN formulations, this extra information can be inserted at multiple points within the adversarial network, thus increasing its descriptive power. We show that ExGANs can produce photo-realistic personalized in-painting results that are both perceptually and semantically plausible by applying them to the task of closed to-open eye in-painting in natural pictures. A new benchmark dataset is also introduced for the task of eye in-painting for future comparisons.
Social Style Characterization from Egocentric Photo-streams
Sep 18, 2017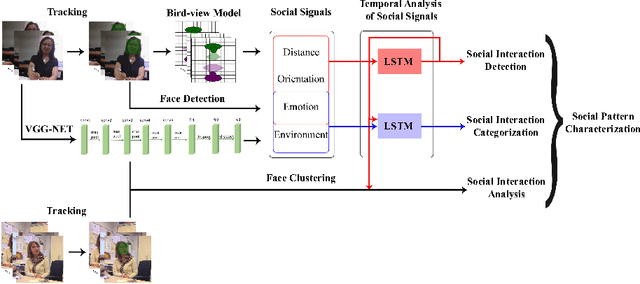
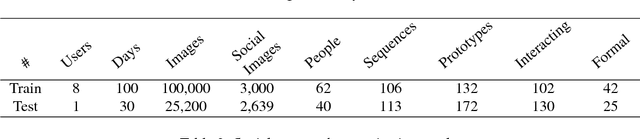

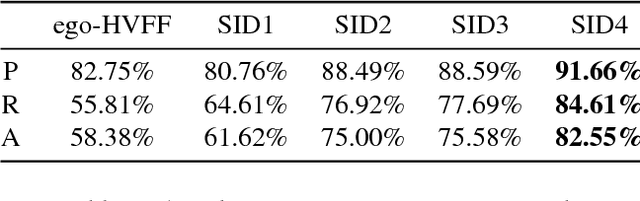
This paper proposes a system for automatic social pattern characterization using a wearable photo-camera. The proposed pipeline consists of three major steps. First, detection of people with whom the camera wearer interacts and, second, categorization of the detected social interactions into formal and informal. These two steps act at event-level where each potential social event is modeled as a multi-dimensional time-series, whose dimensions correspond to a set of relevant features for each task, and a LSTM network is employed for time-series classification. In the last step, recurrences of the same person across the whole set of social interactions are clustered to achieve a comprehensive understanding of the diversity and frequency of the social relations of the user. Experiments over a dataset acquired by a user wearing a photo-camera during a month show promising results on the task of social pattern characterization from egocentric photo-streams.