 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Machine Learning to Predict the Risk of Alzheimer's Disease: An Accurate and Practical Solution for Early Diagnostics
Jun 02, 2020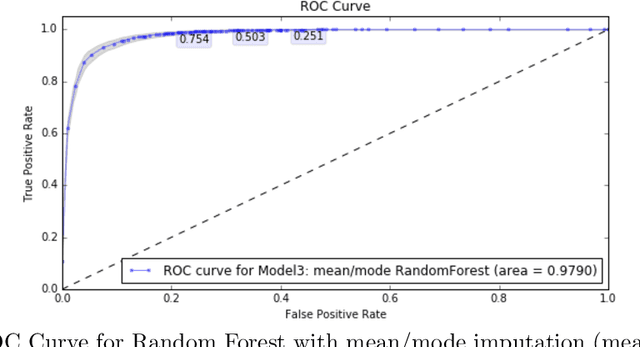

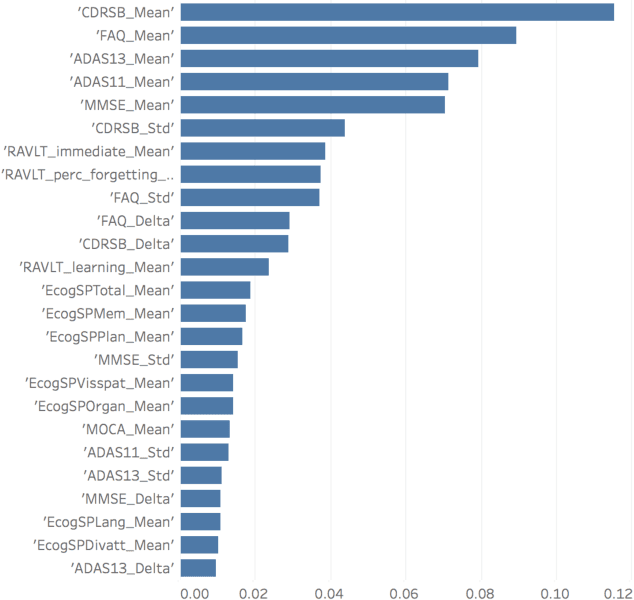
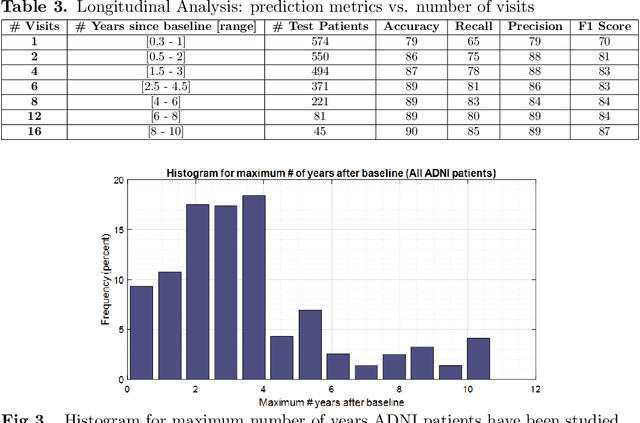
Alzheimer's Disease (AD) ravages the cognitive ability of more than 5 million Americans and creates an enormous strain on the health care system. This paper proposes a machine learning predictive model for AD development without medical imaging and with fewer clinical visits and tests, in hopes of earlier and cheaper diagnoses. That earlier diagnoses could be critical in the effectiveness of any drug or medical treatment to cure this disease. Our model is trained and validated using demographic, biomarker and cognitive test data from two prominent research studies: Alzheimer's Disease Neuroimaging Initiative (ADNI) and Australian Imaging, Biomarker Lifestyle Flagship Study of Aging (AIBL). We systematically explore different machine learning models, pre-processing methods and feature selection techniques. The most performant model demonstrates greater than 90% accuracy and recall in predicting AD, and the results generalize across sub-studies of ADNI and to the independent AIBL study. We also demonstrate that these results are robust to reducing the number of clinical visits or tests per visit. Using a metaclassification algorithm and longitudinal data analysis we are able to produce a "lean" diagnostic protocol with only 3 tests and 4 clinical visits that can predict Alzheimer's development with 87% accuracy and 79% recall. This novel work can be adapted into a practical early diagnostic tool for predicting the development of Alzheimer's that maximizes accuracy while minimizing the number of necessary diagnostic tests and clinical visits.
MMLSpark: Unifying Machine Learning Ecosystems at Massive Scales
Oct 20, 2018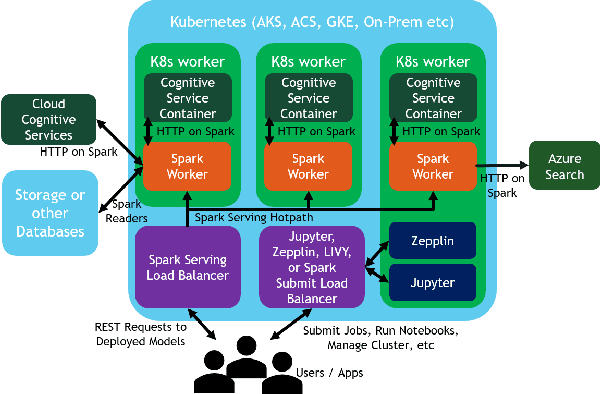

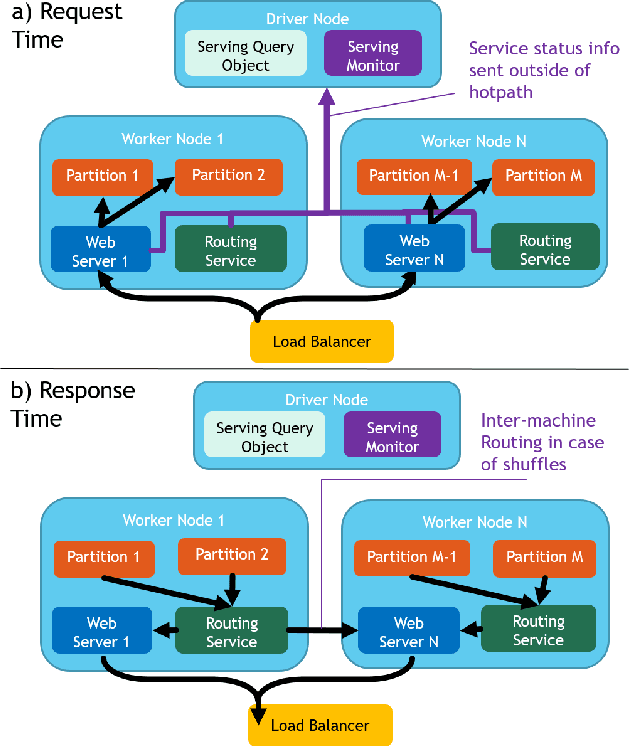
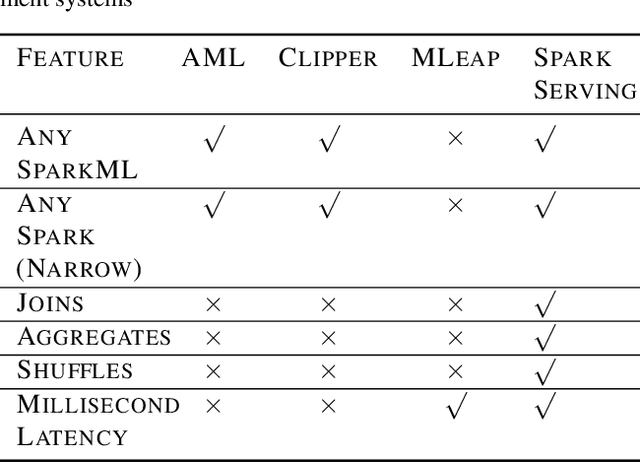
We introduce Microsoft Machine Learning for Apache Spark (MMLSpark), an ecosystem of enhancements that expand the Apache Spark distributed computing library to tackle problems in Deep Learning, Micro-Service Orchestration, Gradient Boosting, Model Interpretability, and other areas of modern computation. Furthermore, we present a novel system called Spark Serving that allows users to run any Apache Spark program as a distributed, sub-millisecond latency web service backed by their existing Spark Cluster. All MMLSpark contributions have the same API to enable simple composition across frameworks and usage across batch, streaming, and RESTful web serving scenarios on static, elastic, or serverless clusters. We showcase MMLSpark by creating a method for deep object detection capable of learning without human labeled data and demonstrate its effectiveness for Snow Leopard conservation.