 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMLSpark: Unifying Machine Learning Ecosystems at Massive Scales
Oct 20, 2018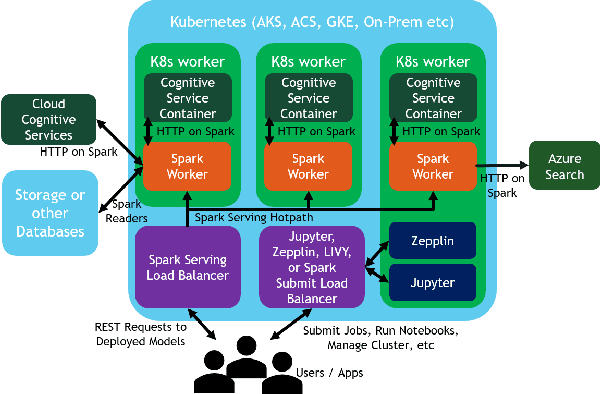

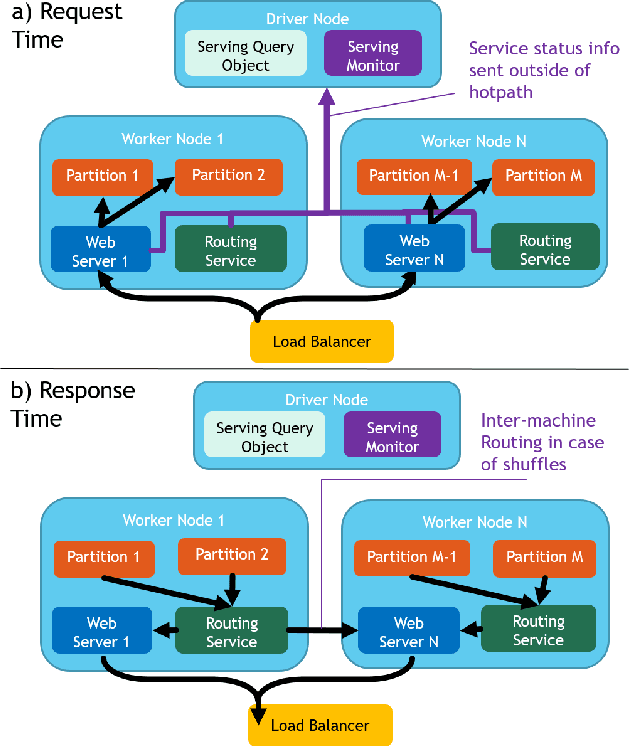
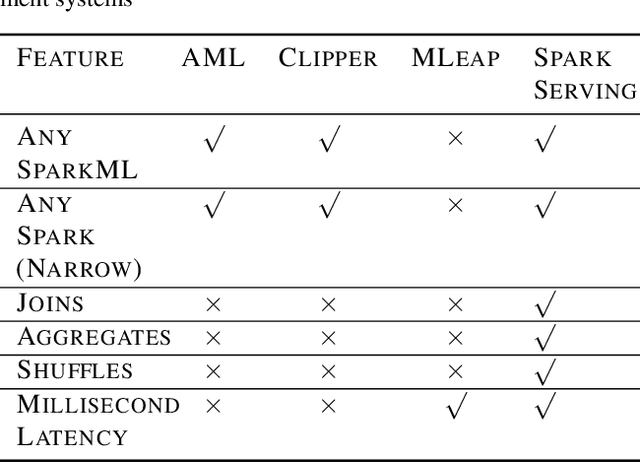
We introduce Microsoft Machine Learning for Apache Spark (MMLSpark), an ecosystem of enhancements that expand the Apache Spark distributed computing library to tackle problems in Deep Learning, Micro-Service Orchestration, Gradient Boosting, Model Interpretability, and other areas of modern computation. Furthermore, we present a novel system called Spark Serving that allows users to run any Apache Spark program as a distributed, sub-millisecond latency web service backed by their existing Spark Cluster. All MMLSpark contributions have the same API to enable simple composition across frameworks and usage across batch, streaming, and RESTful web serving scenarios on static, elastic, or serverless clusters. We showcase MMLSpark by creating a method for deep object detection capable of learning without human labeled data and demonstrate its effectiveness for Snow Leopard conservation.
Flexible and Scalable Deep Learning with MMLSpark
Apr 11, 2018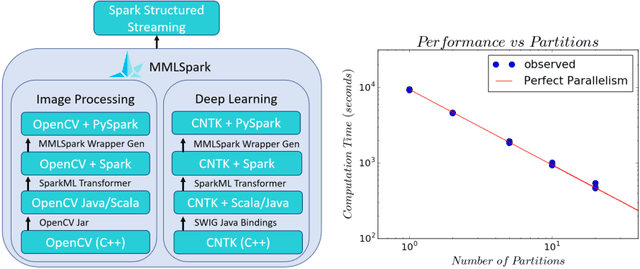

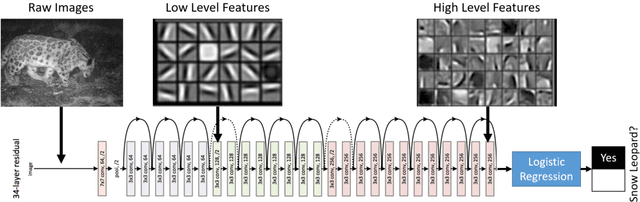
In this work we detail a novel open source library, called MMLSpark, that combines the flexible deep learning library Cognitive Toolkit, with the distributed computing framework Apache Spark. To achieve this, we have contributed Java Language bindings to the Cognitive Toolkit, and added several new components to the Spark ecosystem. In addition, we also integrate the popular image processing library OpenCV with Spark, and present a tool for the automated generation of PySpark wrappers from any SparkML estimator and use this tool to expose all work to the PySpark ecosystem. Finally, we provide a large library of tools for working and developing within the Spark ecosystem. We apply this work to the automated classification of Snow Leopards from camera trap images, and provide an end to end solution for the non-profit conservation organization, the Snow Leopard Trust.