 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Deep Learning Localization Method for Measuring Abdominal Muscle Dimensions in Ultrasound Images
Sep 30, 2021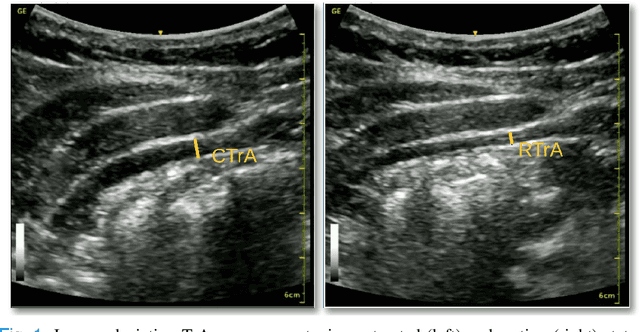
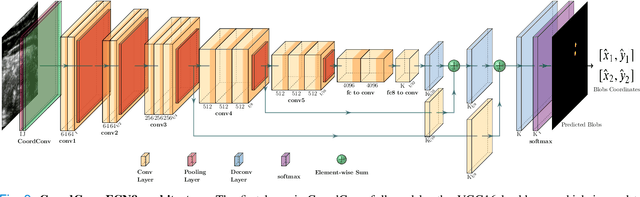
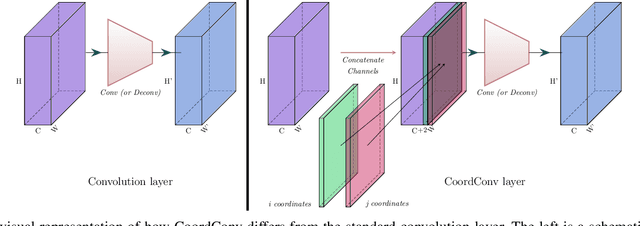

Health professionals extensively use Two- Dimensional (2D) Ultrasound (US) videos and images to visualize and measure internal organs for various purposes including evaluation of muscle architectural changes. US images can be used to measure abdominal muscles dimensions for the diagnosis and creation of customized treatment plans for patients with Low Back Pain (LBP), however, they are difficult to interpret. Due to high variability, skilled professionals with specialized training are required to take measurements to avoid low intra-observer reliability. This variability stems from the challenging nature of accurately finding the correct spatial location of measurement endpoints in abdominal US images. In this paper, we use a Deep Learning (DL) approach to automate the measurement of the abdominal muscle thickness in 2D US images. By treating the problem as a localization task, we develop a modified Fully Convolutional Network (FCN) architecture to generate blobs of coordinate locations of measurement endpoints, similar to what a human operator does. We demonstrate that using the TrA400 US image dataset, our network achieves a Mean Absolute Error (MAE) of 0.3125 on the test set, which almost matches the performance of skilled ultrasound technicians. Our approach can facilitate next steps for automating the process of measurements in 2D US images, while reducing inter-observer as well as intra-observer variability for more effective clinical outcomes.
Memristive Stochastic Computing for Deep Learning Parameter Optimization
Mar 11, 2021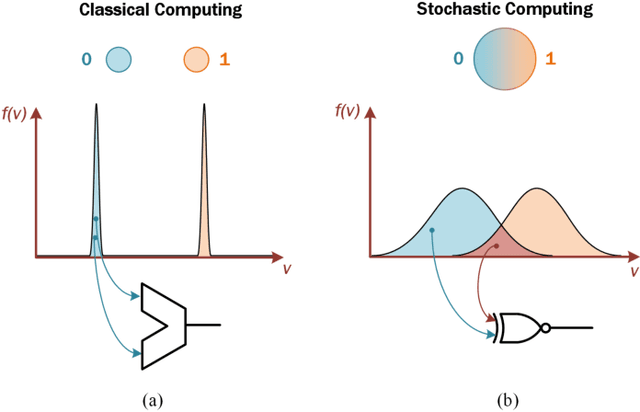
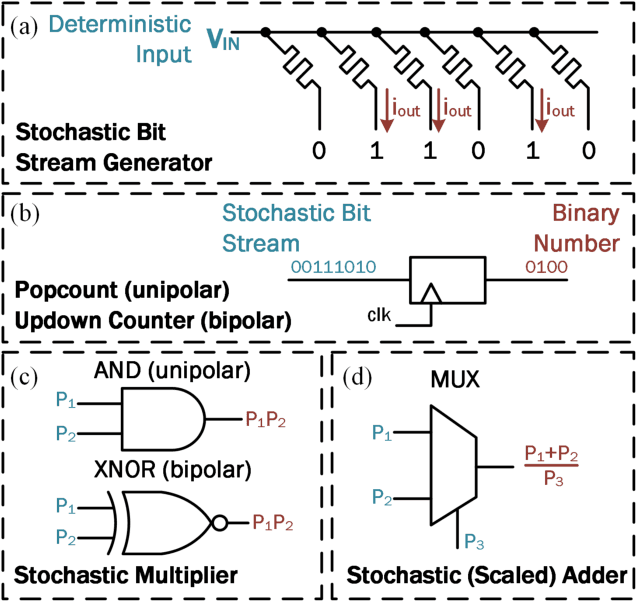
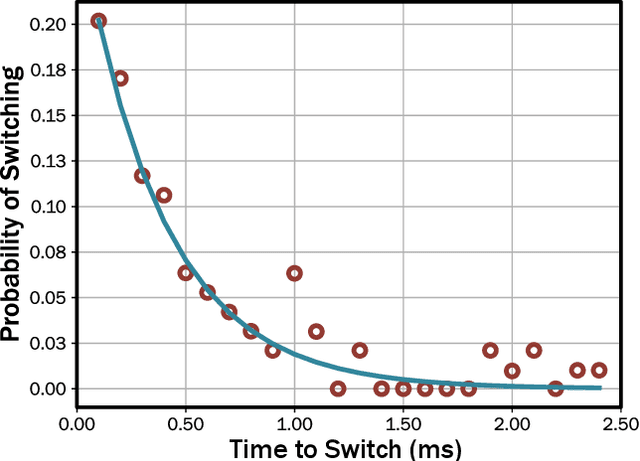
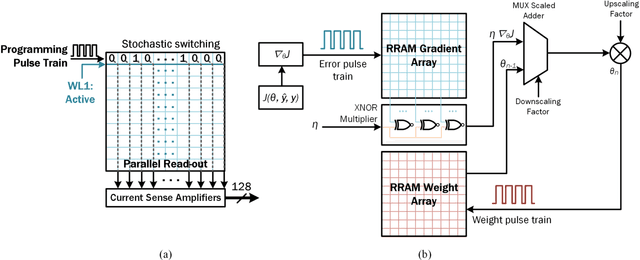
Stochastic Computing (SC) is a computing paradigm that allows for the low-cost and low-power computation of various arithmetic operations using stochastic bit streams and digital logic. In contrast to conventional representation schemes used within the binary domain, the sequence of bit streams in the stochastic domain is inconsequential, and computation is usually non-deterministic. In this brief, we exploit the stochasticity during switching of probabilistic Conductive Bridging RAM (CBRAM) devices to efficiently generate stochastic bit streams in order to perform Deep Learning (DL) parameter optimization, reducing the size of Multiply and Accumulate (MAC) units by 5 orders of magnitude. We demonstrate that in using a 40-nm Complementary Metal Oxide Semiconductor (CMOS) process our scalable architecture occupies 1.55mm$^2$ and consumes approximately 167$\mu$W when optimizing parameters of a Convolutional Neural Network (CNN) while it is being trained for a character recognition task, observing no notable reduction in accuracy post-training.
* Accepted by IEEE Transactions on Circuits and Systems Part II: Express Briefs
Hardware Implementation of Deep Network Accelerators Towards Healthcare and Biomedical Applications
Jul 11, 2020

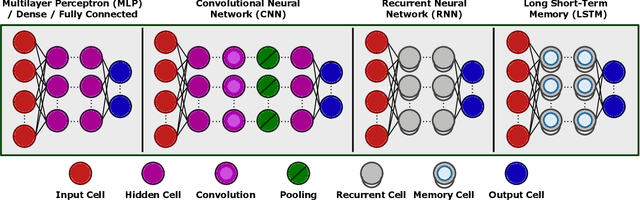
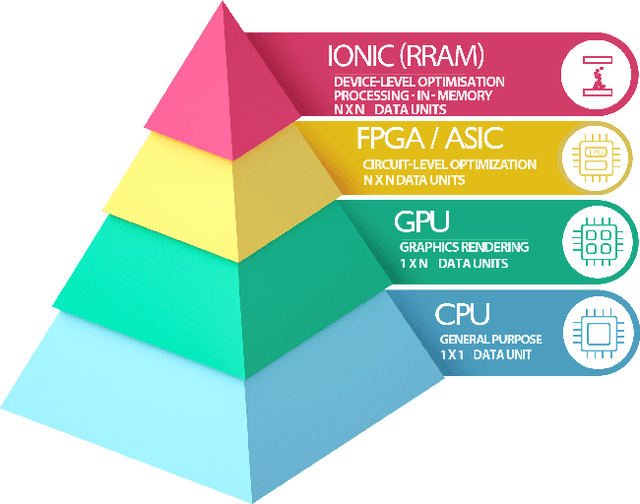
With the advent of dedicated Deep Learning (DL) accelerators and neuromorphic processors, new opportunities are emerging for applying deep and Spiking Neural Network (SNN) algorithms to healthcare and biomedical applications at the edge. This can facilitate the advancement of the medical Internet of Things (IoT) systems and Point of Care (PoC) devices. In this paper, we provide a tutorial describing how various technologies ranging from emerging memristive devices, to established Field Programmable Gate Arrays (FPGAs), and mature Complementary Metal Oxide Semiconductor (CMOS) technology can be used to develop efficient DL accelerators to solve a wide variety of diagnostic, pattern recognition, and signal processing problems in healthcare. Furthermore, we explore how spiking neuromorphic processors can complement their DL counterparts for processing biomedical signals. After providing the required background, we unify the sparsely distributed research on neural network and neuromorphic hardware implementations as applied to the healthcare domain. In addition, we benchmark various hardware platforms by performing a biomedical electromyography (EMG) signal processing task and drawing comparisons among them in terms of inference delay and energy. Finally, we provide our analysis of the field and share a perspective on the advantages, disadvantages, challenges, and opportunities that different accelerators and neuromorphic processors introduce to healthcare and biomedical domains. This paper can serve a large audience, ranging from nanoelectronics researchers, to biomedical and healthcare practitioners in grasping the fundamental interplay between hardware, algorithms, and clinical adoption of these tools, as we shed light on the future of deep networks and spiking neuromorphic processing systems as proponents for driving biomedical circuits and systems forward.
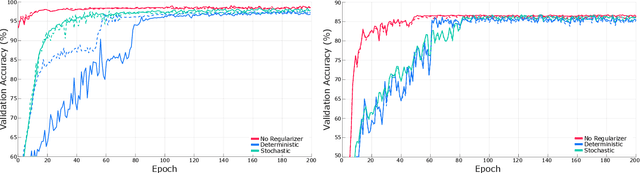
Training Progressively Binarizing Deep Networks Using FPGAs
Jan 08, 2020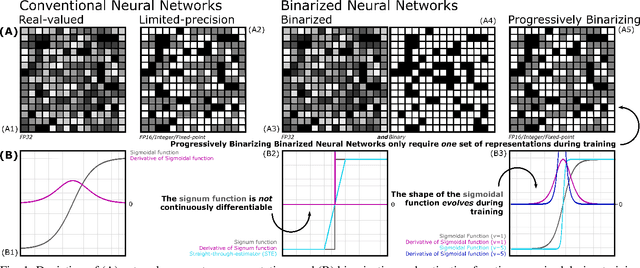
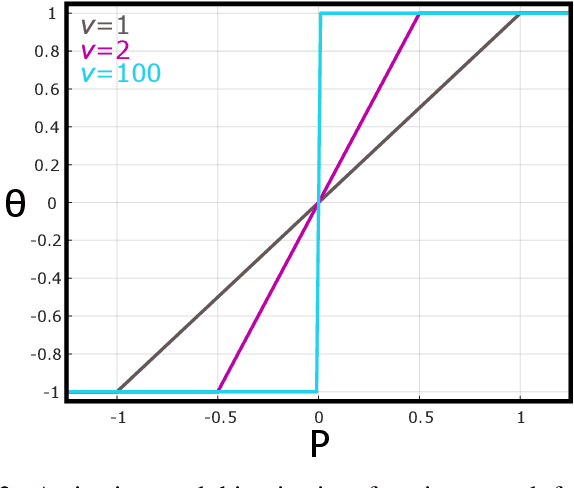

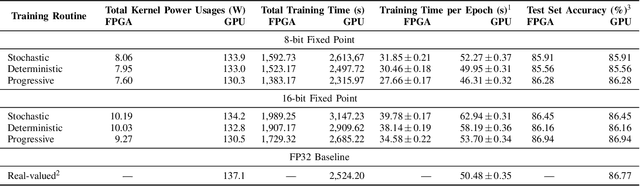
While hardware implementations of inference routines for Binarized Neural Networks (BNNs) are plentiful, current realizations of efficient BNN hardware training accelerators, suitable for Internet of Things (IoT) edge devices, leave much to be desired. Conventional BNN hardware training accelerators perform forward and backward propagations with parameters adopting binary representations, and optimization using parameters adopting floating or fixed-point real-valued representations--requiring two distinct sets of network parameters. In this paper, we propose a hardware-friendly training method that, contrary to conventional methods, progressively binarizes a singular set of fixed-point network parameters, yielding notable reductions in power and resource utilizations. We use the Intel FPGA SDK for OpenCL development environment to train our progressively binarizing DNNs on an OpenVINO FPGA. We benchmark our training approach on both GPUs and FPGAs using CIFAR-10 and compare it to conventional BNNs.
* Accepted at 2020 IEEE International Symposium on Circuits and Systems (ISCAS)
Variation-aware Binarized Memristive Networks
Oct 14, 2019



The quantization of weights to binary states in Deep Neural Networks (DNNs) can replace resource-hungry multiply accumulate operations with simple accumulations. Such Binarized Neural Networks (BNNs) exhibit greatly reduced resource and power requirements. In addition, memristors have been shown as promising synaptic weight elements in DNNs. In this paper, we propose and simulate novel Binarized Memristive Convolutional Neural Network (BMCNN) architectures employing hybrid weight and parameter representations. We train the proposed architectures offline and then map the trained parameters to our binarized memristive devices for inference. To take into account the variations in memristive devices, and to study their effect on the performance, we introduce variations in $R_{ON}$ and $R_{OFF}$. Moreover, we introduce means to mitigate the adverse effect of memristive variations in our proposed networks. Finally, we benchmark our BMCNNs and variation-aware BMCNNs using the MNIST dataset.
* 4 pages, 3 figures, 3 tables
Accelerating Deterministic and Stochastic Binarized Neural Networks on FPGAs Using OpenCL
May 15, 2019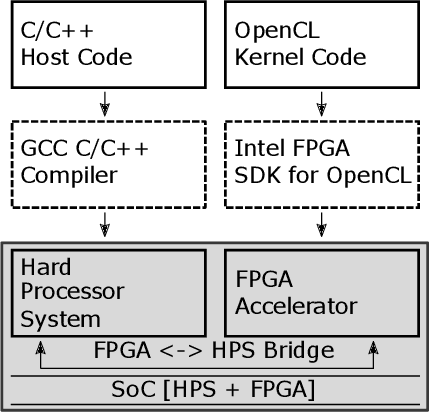
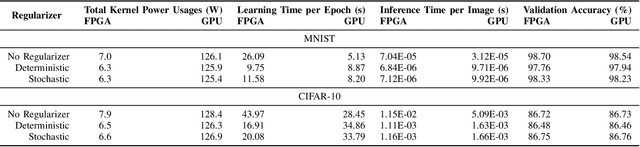
Recent technological advances have proliferated the available computing power, memory, and speed of modern Central Processing Units (CPUs), Graphics Processing Units (GPUs), and Field Programmable Gate Arrays (FPGAs). Consequently, the performance and complexity of Artificial Neural Networks (ANNs) is burgeoning. While GPU accelerated Deep Neural Networks (DNNs) currently offer state-of-the-art performance, they consume large amounts of power. Training such networks on CPUs is inefficient, as data throughput and parallel computation is limited. FPGAs are considered a suitable candidate for performance critical, low power systems, e.g. the Internet of Things (IOT) edge devices. Using the Xilinx SDAccel or Intel FPGA SDK for OpenCL development environment, networks described using the high-level OpenCL framework can be accelerated on heterogeneous platforms. Moreover, the resource utilization and power consumption of DNNs can be further enhanced by utilizing regularization techniques that binarize network weights. In this paper, we introduce, to the best of our knowledge, the first FPGA-accelerated stochastically binarized DNN implementations, and compare them to implementations accelerated using both GPUs and FPGAs. Our developed networks are trained and benchmarked using the popular MNIST and CIFAR-10 datasets, and achieve near state-of-the-art performance, while offering a >16-fold improvement in power consumption, compared to conventional GPU-accelerated networks. Both our FPGA-accelerated determinsitic and stochastic BNNs reduce inference times on MNIST and CIFAR-10 by >9.89x and >9.91x, respectively.
* 4 pages, 3 figures, 1 table