 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaNames: A Massively Multilingual Entity Name Corpus
Mar 31, 2022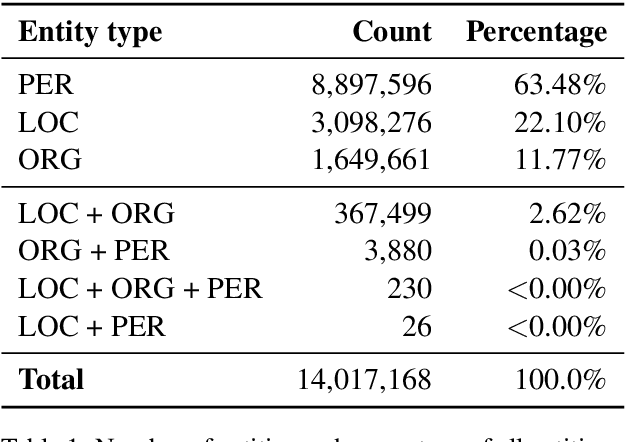
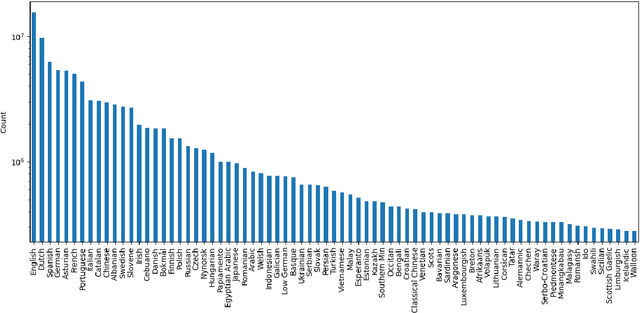
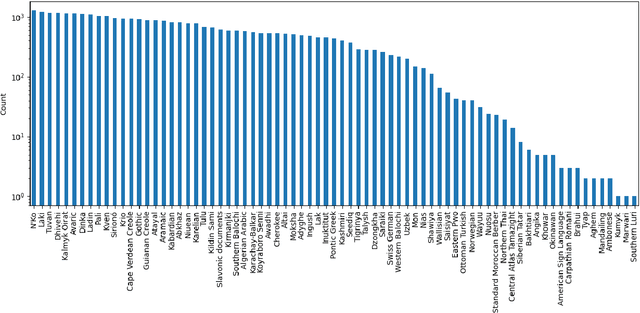
This preprint describes work in progress on ParaNames, a multilingual parallel name resource consisting of names for approximately 14 million entities. The included names span over 400 languages, and almost all entities are mapped to standardized entity types (PER/LOC/ORG). Using Wikidata as a source, we create the largest resource of this type to-date. We describe our approach to filtering and standardizing the data to provide the best quality possible. ParaNames is useful for multilingual language processing, both in defining tasks for name translation/transliteration and as supplementary data for tasks such as named entity recognition and linking. We demonstrate an application of ParaNames by training a multilingual model for canonical name translation to and from English. Our resource is released at \url{https://github.com/bltlab/paranames} under a Creative Commons license (CC BY 4.0).
Detecting Unassimilated Borrowings in Spanish: An Annotated Corpus and Approaches to Modeling
Mar 30, 2022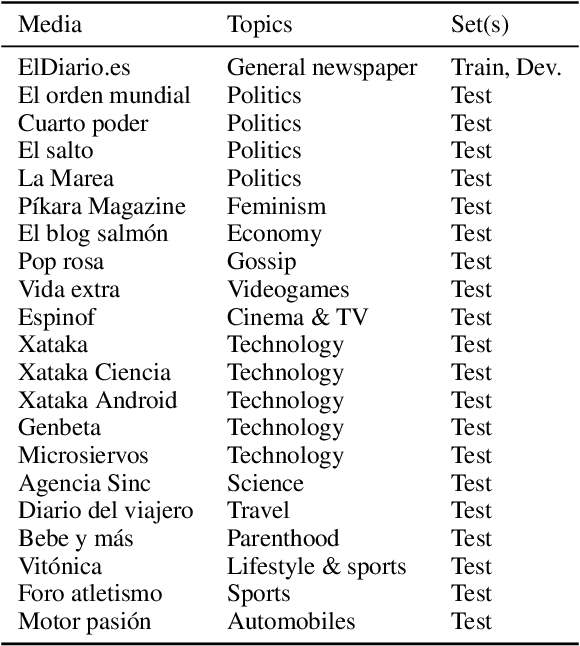
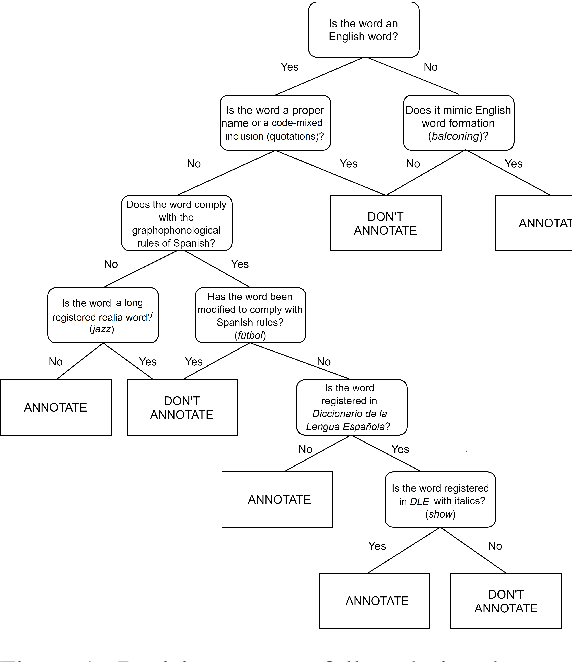
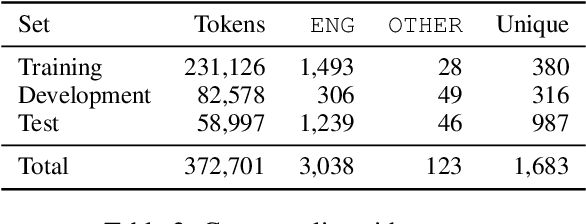
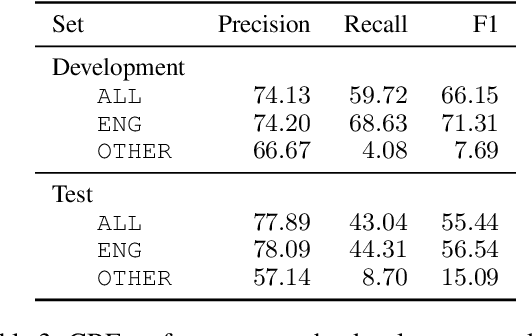
This work presents a new resource for borrowing identification and analyzes the performance and errors of several models on this task. We introduce a new annotated corpus of Spanish newswire rich in unassimilated lexical borrowings -- words from one language that are introduced into another without orthographic adaptation -- and use it to evaluate how several sequence labeling models (CRF, BiLSTM-CRF, and Transformer-based models) perform. The corpus contains 370,000 tokens and is larger, more borrowing-dense, OOV-rich, and topic-varied than previous corpora available for this task. Our results show that a BiLSTM-CRF model fed with subword embeddings along with either Transformer-based embeddings pretrained on codeswitched data or a combination of contextualized word embeddings outperforms results obtained by a multilingual BERT-based model.
Toward More Meaningful Resources for Lower-resourced Languages
Feb 24, 2022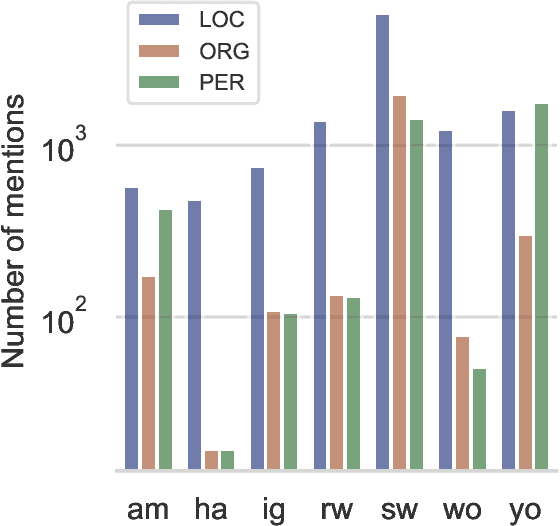
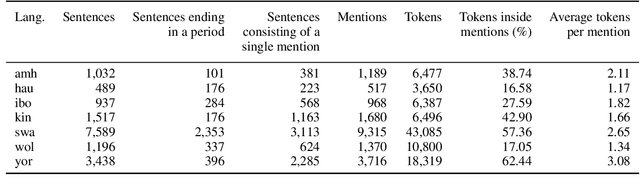
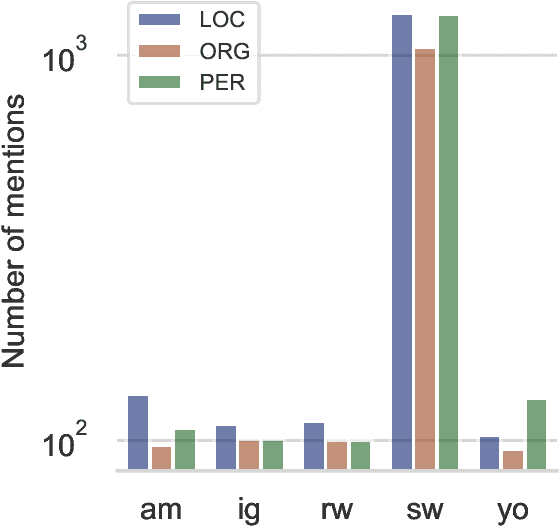
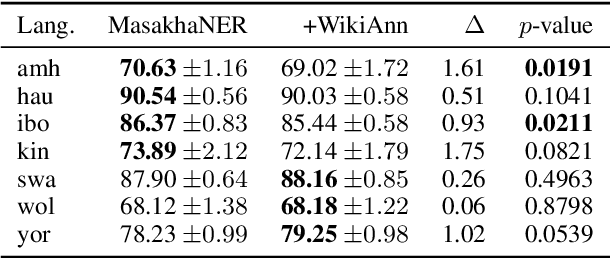
In this position paper, we describe our perspective on how meaningful resources for lower-resourced languages should be developed in connection with the speakers of those languages. We first examine two massively multilingual resources in detail. We explore the contents of the names stored in Wikidata for a few lower-resourced languages and find that many of them are not in fact in the languages they claim to be and require non-trivial effort to correct. We discuss quality issues present in WikiAnn and evaluate whether it is a useful supplement to hand annotated data. We then discuss the importance of creating annotation for lower-resourced languages in a thoughtful and ethical way that includes the languages' speakers as part of the development process. We conclude with recommended guidelines for resource development.
Multilingual Open Text 1.0: Public Domain News in 44 Languages
Jan 14, 2022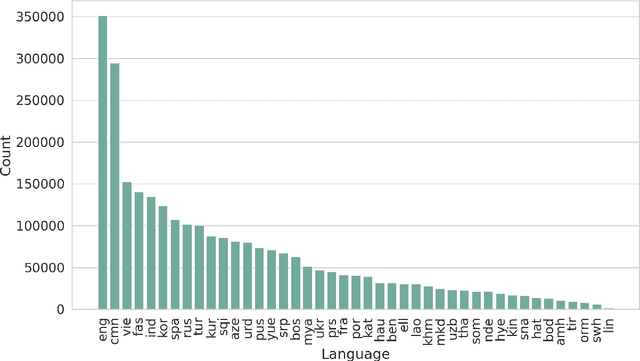
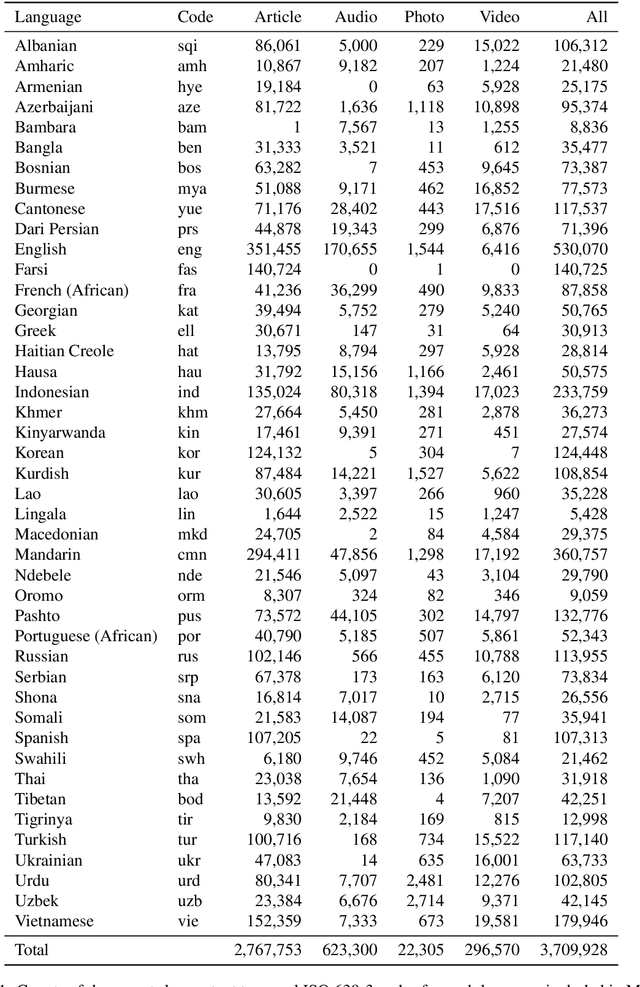
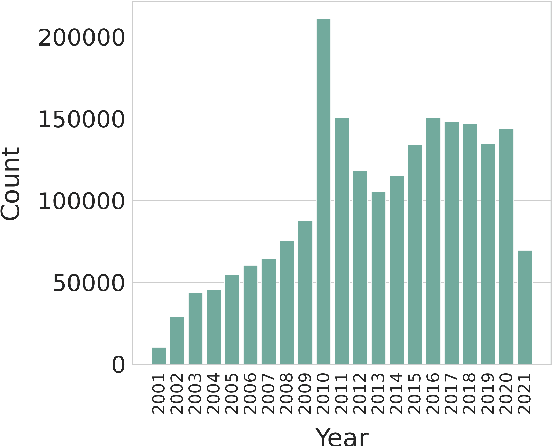

We present a new multilingual corpus containing text in 44 languages, many of which have relatively few existing resources for natural language processing. The first release of the corpus contains over 2.7 million news articles and 1 million shorter passages published between 2001--2021, collected from Voice of America news websites. We describe our process for collecting, filtering, and processing the data. The source material is in the public domain, our collection is licensed using a creative commons license (CC BY 4.0), and all software used to create the corpus is released under the MIT License. The corpus will be regularly updated as additional documents are published.
Overview of ADoBo 2021: Automatic Detection of Unassimilated Borrowings in the Spanish Press
Oct 29, 2021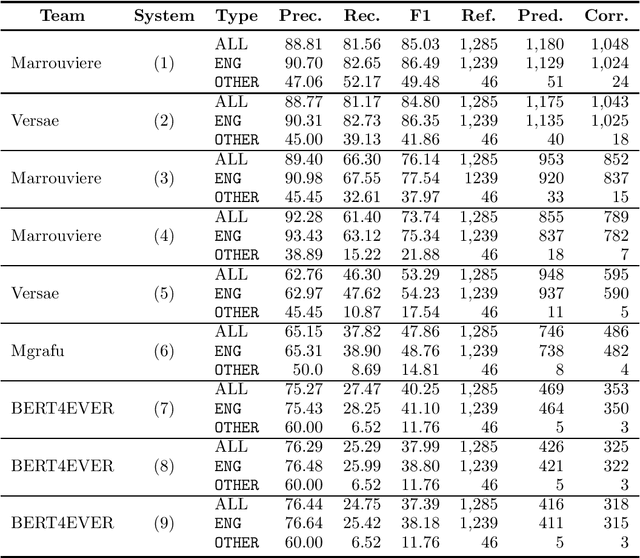
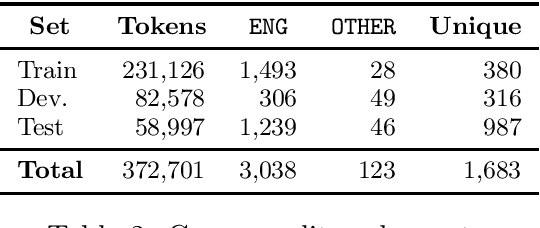
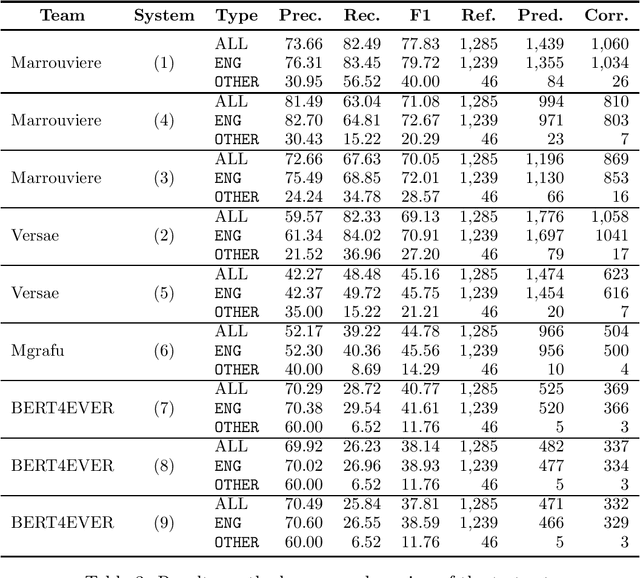
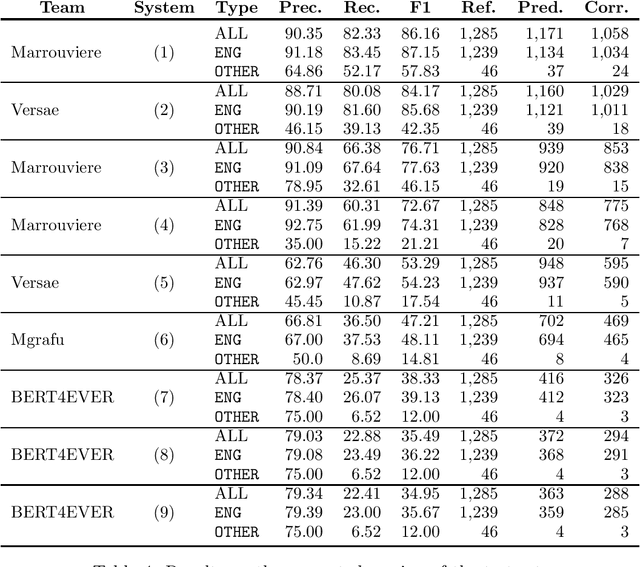
This paper summarizes the main findings of the ADoBo 2021 shared task, proposed in the context of IberLef 2021. In this task, we invited participants to detect lexical borrowings (coming mostly from English) in Spanish newswire texts. This task was framed as a sequence classification problem using BIO encoding. We provided participants with an annotated corpus of lexical borrowings which we split into training, development and test splits. We received submissions from 4 teams with 9 different system runs overall. The results, which range from F1 scores of 37 to 85, suggest that this is a challenging task, especially when out-of-domain or OOV words are considered, and that traditional methods informed with lexicographic information would benefit from taking advantage of current NLP trends.
* Post-print. Original version at Procesamiento del Lenguaje Natural 67 (2021), p. 277-285
Addressing Barriers to Reproducible Named Entity Recognition Evaluation
Jul 29, 2021
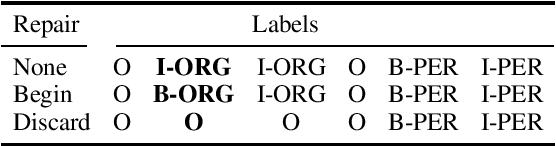

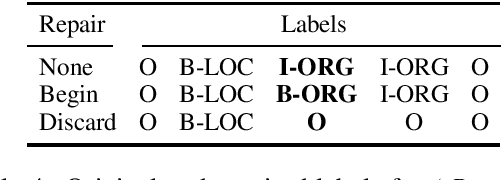
To address what we believe is a looming crisis of unreproducible evaluation for named entity recognition tasks, we present guidelines for reproducible evaluation. The guidelines we propose are extremely simple, focusing on transparency regarding how chunks are encoded and scored, but very few papers currently being published fully comply with them. We demonstrate that despite the apparent simplicity of NER evaluation, unreported differences in the scoring procedure can result in changes to scores that are both of noticeable magnitude and are statistically significant. We provide SeqScore, an open source toolkit that addresses many of the issues that cause replication failures and makes following our guidelines easy.
Macro-Average: Rare Types Are Important Too
Apr 12, 2021
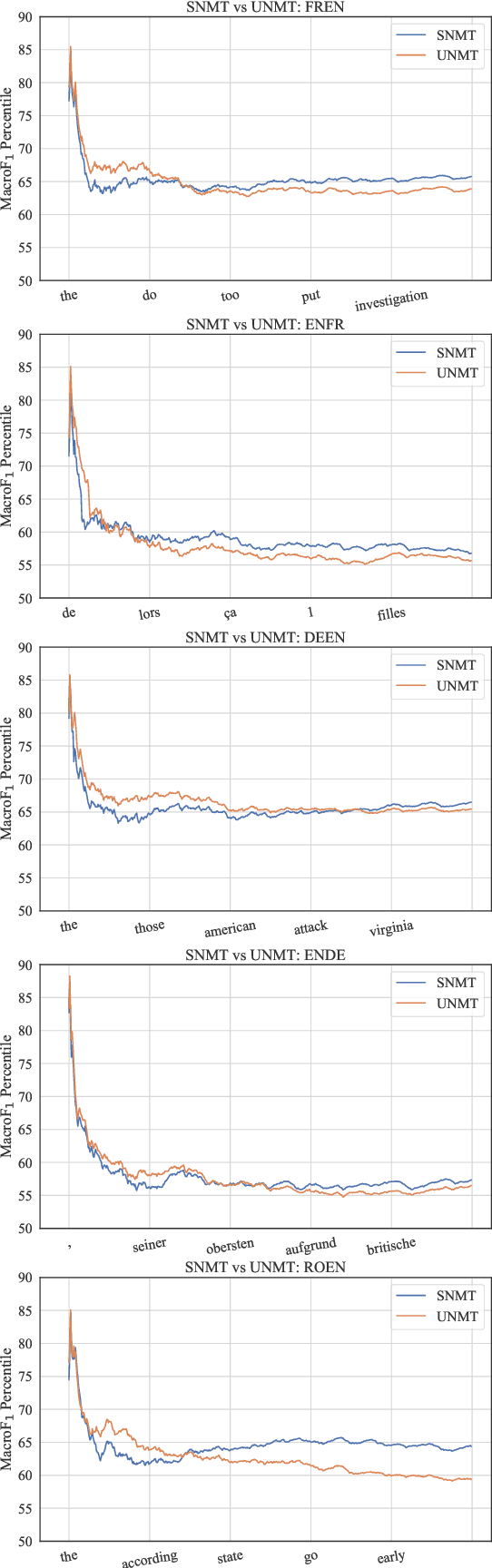
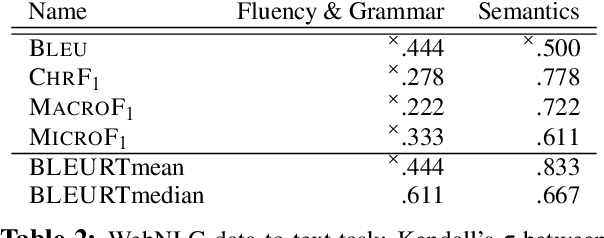
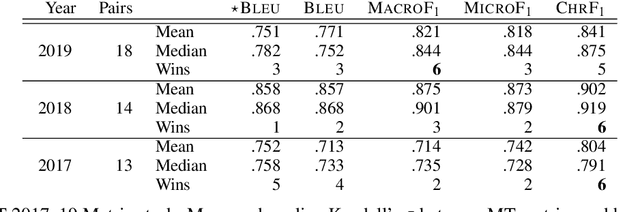
While traditional corpus-level evaluation metrics for machine translation (MT) correlate well with fluency, they struggle to reflect adequacy. Model-based MT metrics trained on segment-level human judgments have emerged as an attractive replacement due to strong correlation results. These models, however, require potentially expensive re-training for new domains and languages. Furthermore, their decisions are inherently non-transparent and appear to reflect unwelcome biases. We explore the simple type-based classifier metric, MacroF1, and study its applicability to MT evaluation. We find that MacroF1 is competitive on direct assessment, and outperforms others in indicating downstream cross-lingual information retrieval task performance. Further, we show that MacroF1 can be used to effectively compare supervised and unsupervised neural machine translation, and reveal significant qualitative differences in the methods' outputs.
Mining Wikidata for Name Resources for African Languages
Apr 01, 2021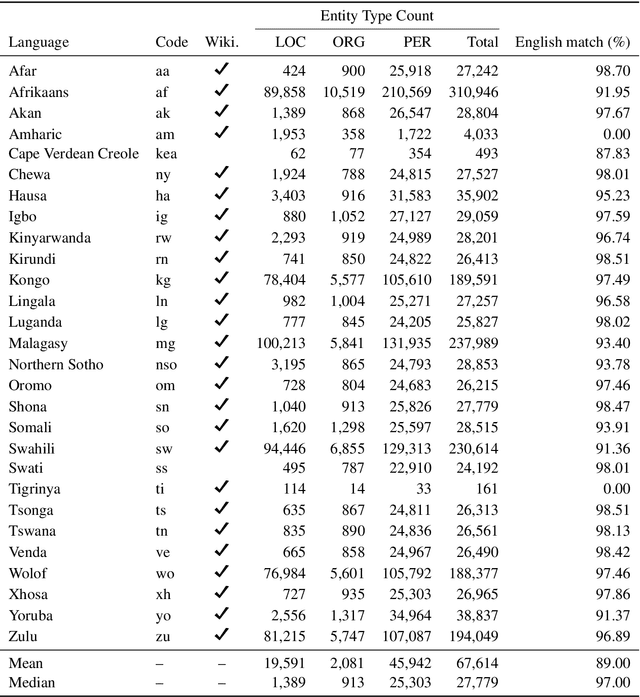
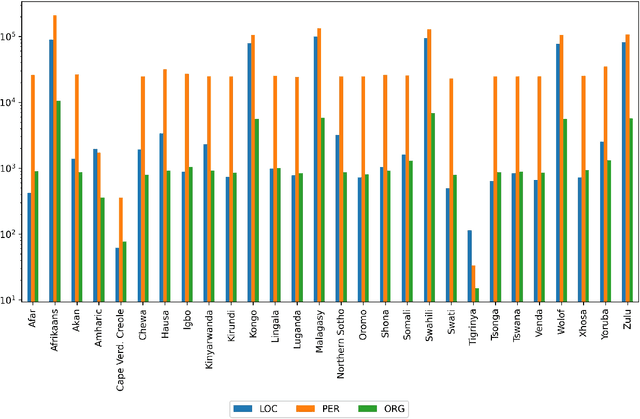
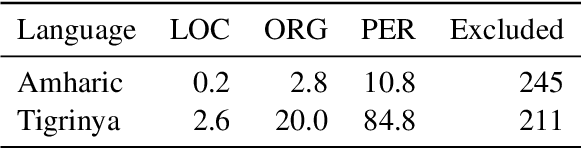

This work supports further development of language technology for the languages of Africa by providing a Wikidata-derived resource of name lists corresponding to common entity types (person, location, and organization). While we are not the first to mine Wikidata for name lists, our approach emphasizes scalability and replicability and addresses data quality issues for languages that do not use Latin scripts. We produce lists containing approximately 1.9 million names across 28 African languages. We describe the data, the process used to produce it, and its limitations, and provide the software and data for public use. Finally, we discuss the ethical considerations of producing this resource and others of its kind.
TMR: Evaluating NER Recall on Tough Mentions
Mar 23, 2021
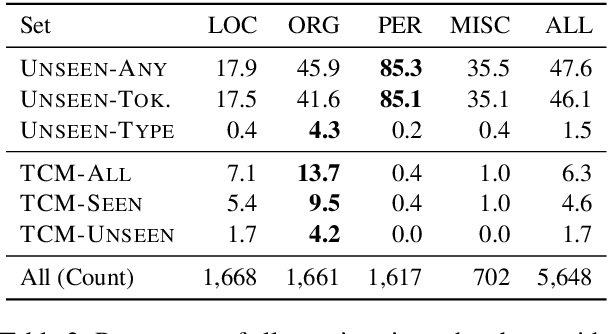
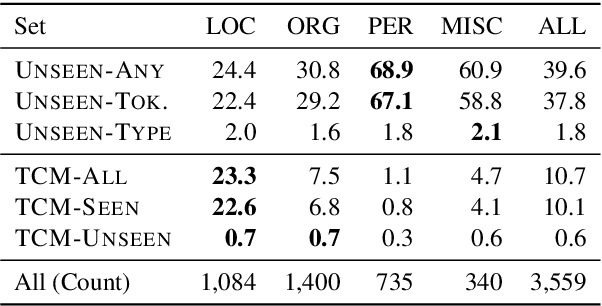
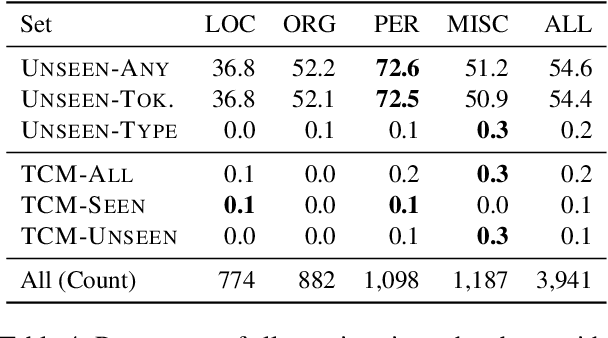
We propose the Tough Mentions Recall (TMR) metrics to supplement traditional named entity recognition (NER) evaluation by examining recall on specific subsets of "tough" mentions: unseen mentions, those whose tokens or token/type combination were not observed in training, and type-confusable mentions, token sequences with multiple entity types in the test data. We demonstrate the usefulness of these metrics by evaluating corpora of English, Spanish, and Dutch using five recent neural architectures. We identify subtle differences between the performance of BERT and Flair on two English NER corpora and identify a weak spot in the performance of current models in Spanish. We conclude that the TMR metrics enable differentiation between otherwise similar-scoring systems and identification of patterns in performance that would go unnoticed from overall precision, recall, and F1.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021

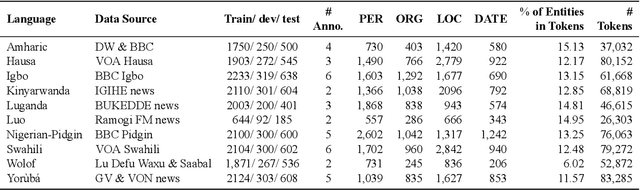
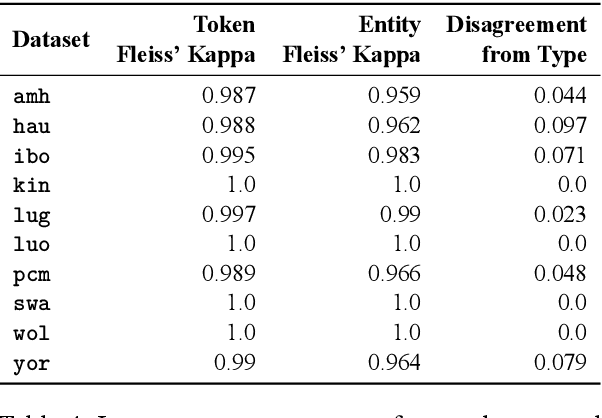
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.