 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgemSLAM: Massively multilingual joint pre-training for speech and text
Feb 03, 2022



We present mSLAM, a multilingual Speech and LAnguage Model that learns cross-lingual cross-modal representations of speech and text by pre-training jointly on large amounts of unlabeled speech and text in multiple languages. mSLAM combines w2v-BERT pre-training on speech with SpanBERT pre-training on character-level text, along with Connectionist Temporal Classification (CTC) losses on paired speech and transcript data, to learn a single model capable of learning from and representing both speech and text signals in a shared representation space. We evaluate mSLAM on several downstream speech understanding tasks and find that joint pre-training with text improves quality on speech translation, speech intent classification and speech language-ID while being competitive on multilingual ASR, when compared against speech-only pre-training. Our speech translation model demonstrates zero-shot text translation without seeing any text translation data, providing evidence for cross-modal alignment of representations. mSLAM also benefits from multi-modal fine-tuning, further improving the quality of speech translation by directly leveraging text translation data during the fine-tuning process. Our empirical analysis highlights several opportunities and challenges arising from large-scale multimodal pre-training, suggesting directions for future research.
Can Multilinguality benefit Non-autoregressive Machine Translation?
Dec 16, 2021
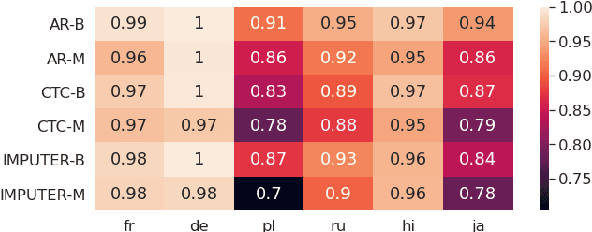
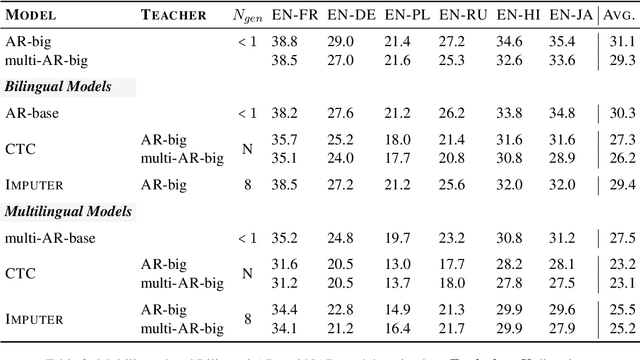
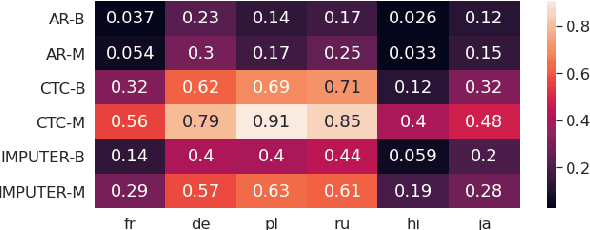
Non-autoregressive (NAR) machine translation has recently achieved significant improvements, and now outperforms autoregressive (AR) models on some benchmarks, providing an efficient alternative to AR inference. However, while AR translation is often implemented using multilingual models that benefit from transfer between languages and from improved serving efficiency, multilingual NAR models remain relatively unexplored. Taking Connectionist Temporal Classification (CTC) as an example NAR model and Imputer as a semi-NAR model, we present a comprehensive empirical study of multilingual NAR. We test its capabilities with respect to positive transfer between related languages and negative transfer under capacity constraints. As NAR models require distilled training sets, we carefully study the impact of bilingual versus multilingual teachers. Finally, we fit a scaling law for multilingual NAR, which quantifies its performance relative to the AR model as model scale increases.
Scaling Laws for Neural Machine Translation
Sep 16, 2021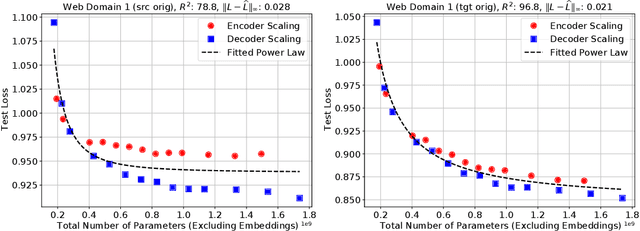
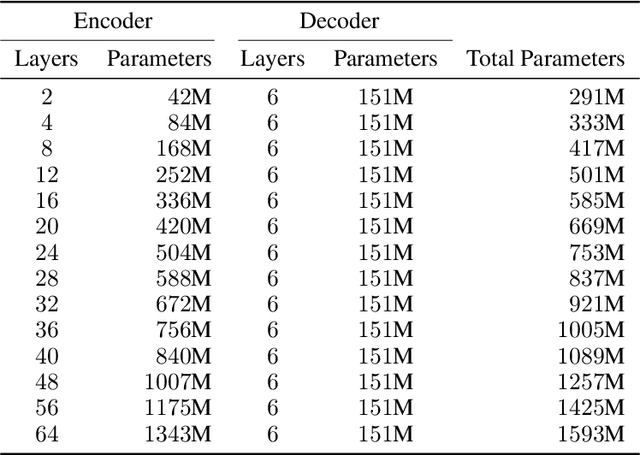
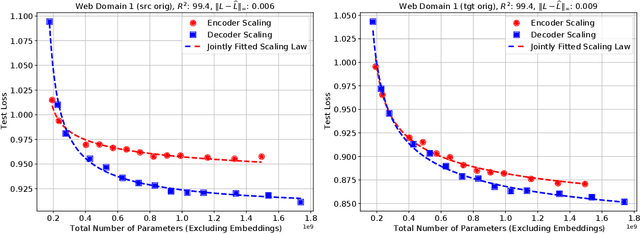
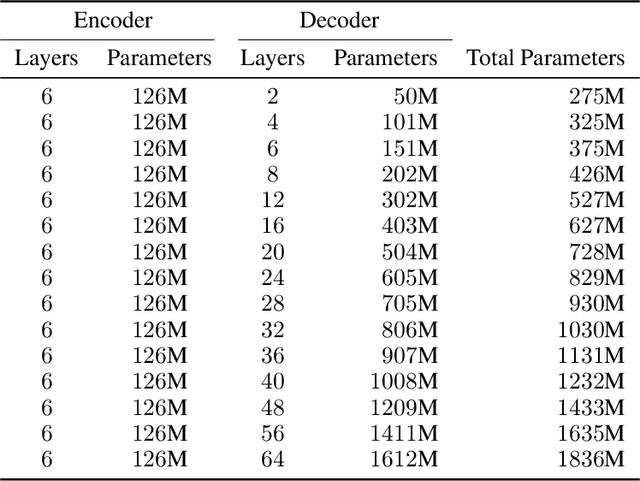
We present an empirical study of scaling properties of encoder-decoder Transformer models used in neural machine translation (NMT). We show that cross-entropy loss as a function of model size follows a certain scaling law. Specifically (i) We propose a formula which describes the scaling behavior of cross-entropy loss as a bivariate function of encoder and decoder size, and show that it gives accurate predictions under a variety of scaling approaches and languages; we show that the total number of parameters alone is not sufficient for such purposes. (ii) We observe different power law exponents when scaling the decoder vs scaling the encoder, and provide recommendations for optimal allocation of encoder/decoder capacity based on this observation. (iii) We also report that the scaling behavior of the model is acutely influenced by composition bias of the train/test sets, which we define as any deviation from naturally generated text (either via machine generated or human translated text). We observe that natural text on the target side enjoys scaling, which manifests as successful reduction of the cross-entropy loss. (iv) Finally, we investigate the relationship between the cross-entropy loss and the quality of the generated translations. We find two different behaviors, depending on the nature of the test data. For test sets which were originally translated from target language to source language, both loss and BLEU score improve as model size increases. In contrast, for test sets originally translated from source language to target language, the loss improves, but the BLEU score stops improving after a certain threshold. We release generated text from all models used in this study.
Assessing Reference-Free Peer Evaluation for Machine Translation
Apr 12, 2021
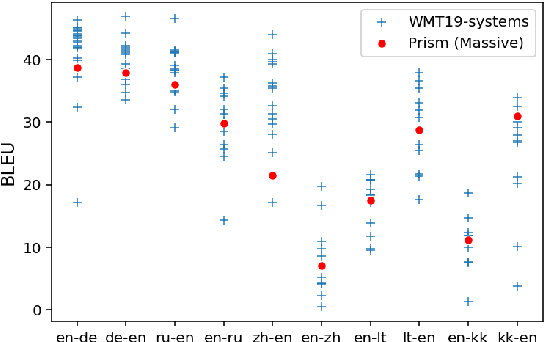
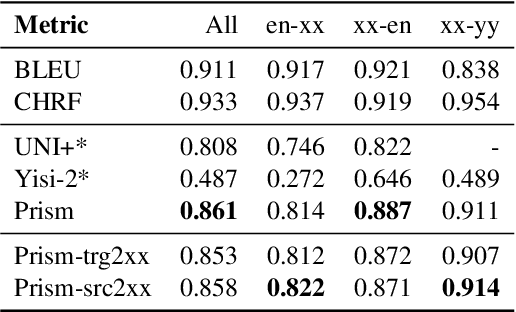
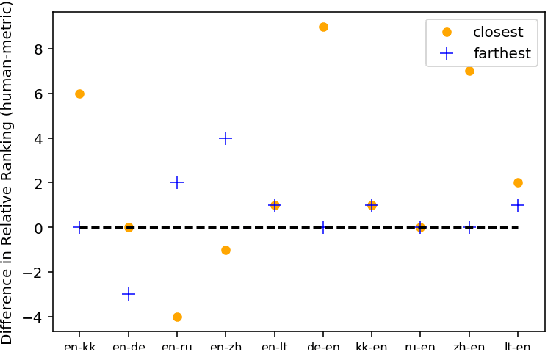
Reference-free evaluation has the potential to make machine translation evaluation substantially more scalable, allowing us to pivot easily to new languages or domains. It has been recently shown that the probabilities given by a large, multilingual model can achieve state of the art results when used as a reference-free metric. We experiment with various modifications to this model and demonstrate that by scaling it up we can match the performance of BLEU. We analyze various potential weaknesses of the approach and find that it is surprisingly robust and likely to offer reasonable performance across a broad spectrum of domains and different system qualities.
Sentence Boundary Augmentation For Neural Machine Translation Robustness
Oct 21, 2020
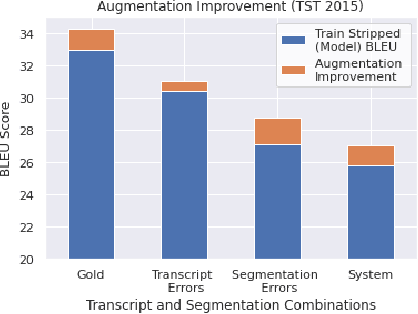

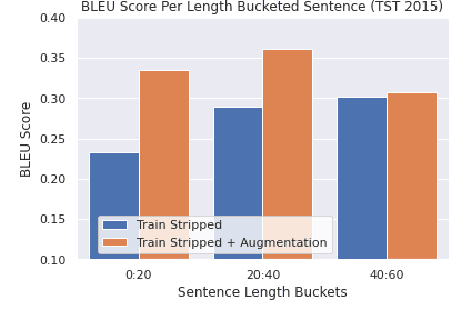
Neural Machine Translation (NMT) models have demonstrated strong state of the art performance on translation tasks where well-formed training and evaluation data are provided, but they remain sensitive to inputs that include errors of various types. Specifically, in the context of long-form speech translation systems, where the input transcripts come from Automatic Speech Recognition (ASR), the NMT models have to handle errors including phoneme substitutions, grammatical structure, and sentence boundaries, all of which pose challenges to NMT robustness. Through in-depth error analysis, we show that sentence boundary segmentation has the largest impact on quality, and we develop a simple data augmentation strategy to improve segmentation robustness.
Inference Strategies for Machine Translation with Conditional Masking
Oct 20, 2020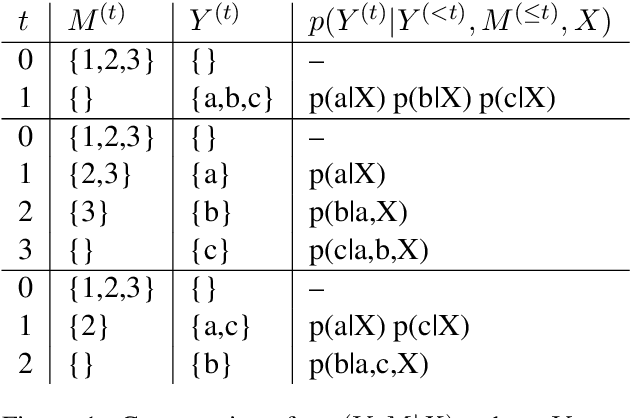
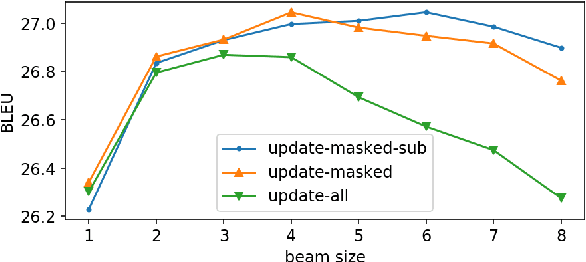
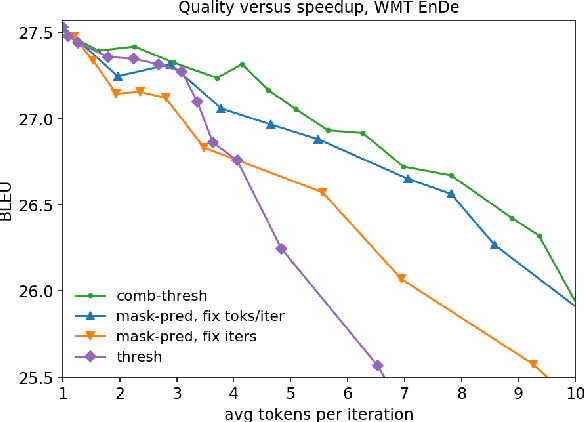
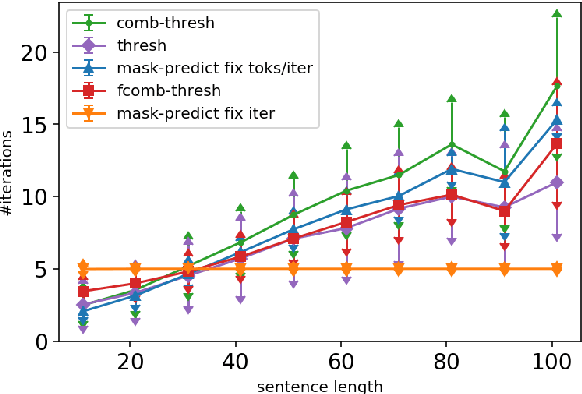
Conditional masked language model (CMLM) training has proven successful for non-autoregressive and semi-autoregressive sequence generation tasks, such as machine translation. Given a trained CMLM, however, it is not clear what the best inference strategy is. We formulate masked inference as a factorization of conditional probabilities of partial sequences, show that this does not harm performance, and investigate a number of simple heuristics motivated by this perspective. We identify a thresholding strategy that has advantages over the standard "mask-predict" algorithm, and provide analyses of its behavior on machine translation tasks.
Human-Paraphrased References Improve Neural Machine Translation
Oct 20, 2020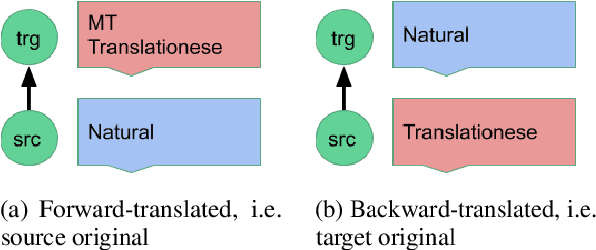
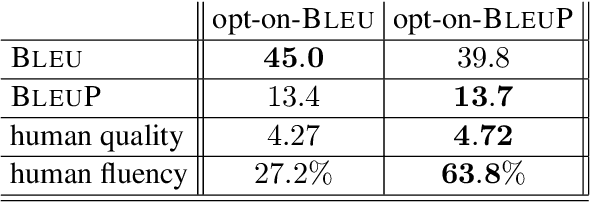
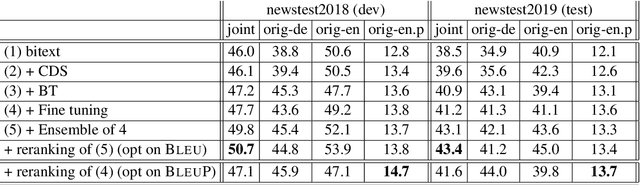
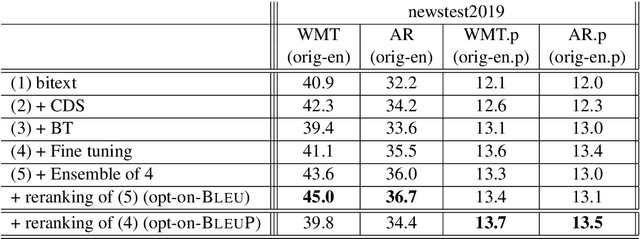
Automatic evaluation comparing candidate translations to human-generated paraphrases of reference translations has recently been proposed by Freitag et al. When used in place of original references, the paraphrased versions produce metric scores that correlate better with human judgment. This effect holds for a variety of different automatic metrics, and tends to favor natural formulations over more literal (translationese) ones. In this paper we compare the results of performing end-to-end system development using standard and paraphrased references. With state-of-the-art English-German NMT components, we show that tuning to paraphrased references produces a system that is significantly better according to human judgment, but 5 BLEU points worse when tested on standard references. Our work confirms the finding that paraphrased references yield metric scores that correlate better with human judgment, and demonstrates for the first time that using these scores for system development can lead to significant improvements.
Re-translation versus Streaming for Simultaneous Translation
Apr 14, 2020
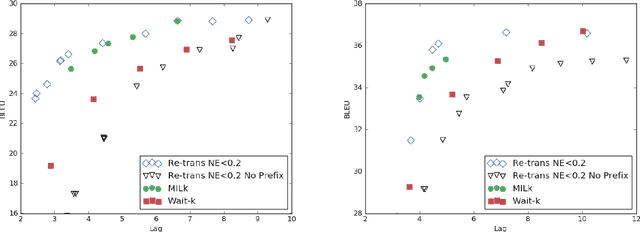

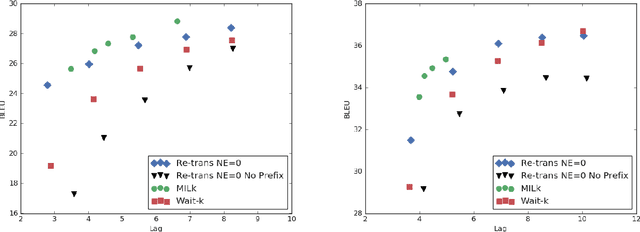
There has been great progress in improving streaming machine translation, a simultaneous paradigm where the system appends to a growing hypothesis as more source content becomes available. We study a related problem in which revisions to the hypothesis beyond strictly appending words are permitted. This is suitable for applications such as live captioning an audio feed. In this setting, we compare custom streaming approaches to re-translation, a straightforward strategy where each new source token triggers a distinct translation from scratch. We find re-translation to be as good or better than state-of-the-art streaming systems, even when operating under constraints that allow very few revisions. We attribute much of this success to a previously proposed data-augmentation technique that adds prefix-pairs to the training data, which alongside wait-k inference forms a strong baseline for streaming translation. We also highlight re-translation's ability to wrap arbitrarily powerful MT systems with an experiment showing large improvements from an upgrade to its base model.
Re-Translation Strategies For Long Form, Simultaneous, Spoken Language Translation
Dec 06, 2019
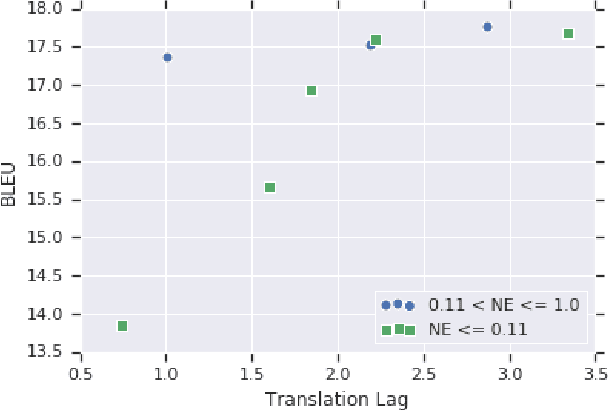
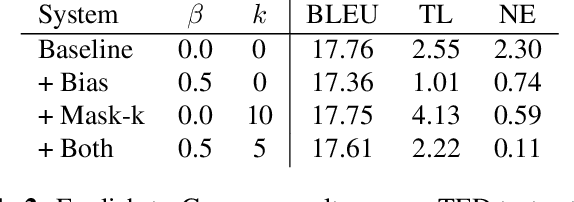
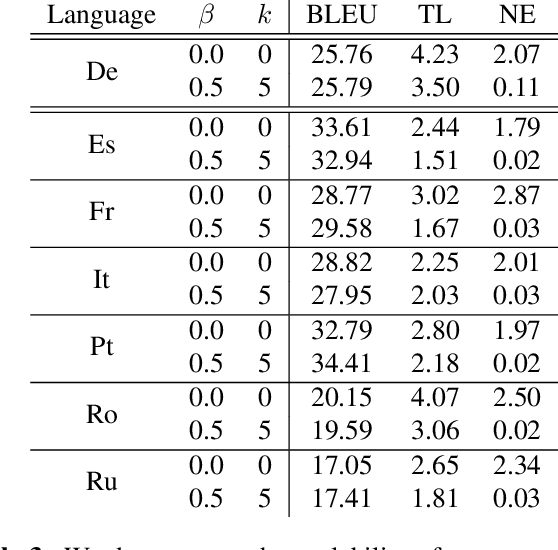
We investigate the problem of simultaneous machine translation of long-form speech content. We target a continuous speech-to-text scenario, generating translated captions for a live audio feed, such as a lecture or play-by-play commentary. As this scenario allows for revisions to our incremental translations, we adopt a re-translation approach to simultaneous translation, where the source is repeatedly translated from scratch as it grows. This approach naturally exhibits very low latency and high final quality, but at the cost of incremental instability as the output is continuously refined. We experiment with a pipeline of industry-grade speech recognition and translation tools, augmented with simple inference heuristics to improve stability. We use TED Talks as a source of multilingual test data, developing our techniques on English-to-German spoken language translation. Our minimalist approach to simultaneous translation allows us to easily scale our final evaluation to six more target languages, dramatically improving incremental stability for all of them.
Massively Multilingual Neural Machine Translation in the Wild: Findings and Challenges
Jul 11, 2019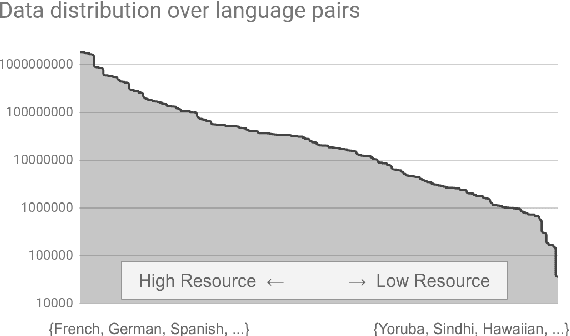
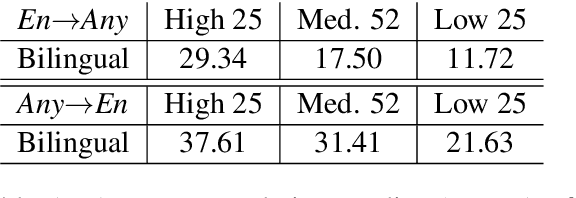
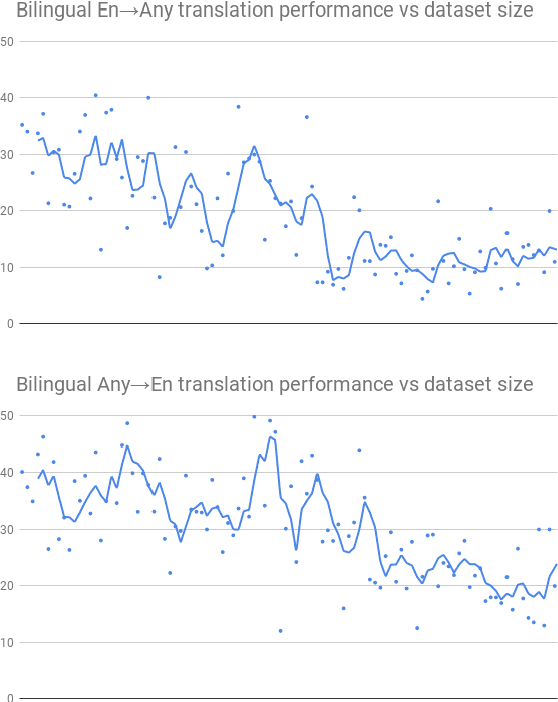
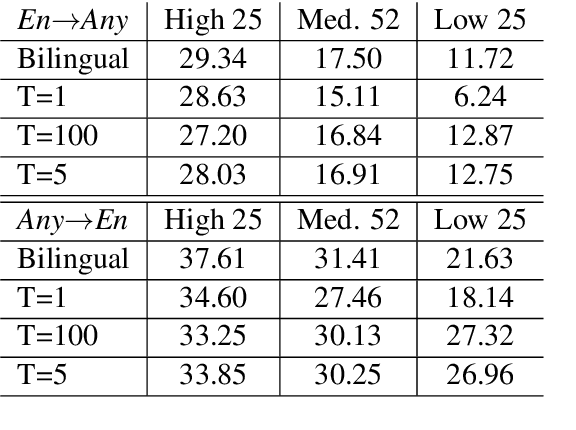
We introduce our efforts towards building a universal neural machine translation (NMT) system capable of translating between any language pair. We set a milestone towards this goal by building a single massively multilingual NMT model handling 103 languages trained on over 25 billion examples. Our system demonstrates effective transfer learning ability, significantly improving translation quality of low-resource languages, while keeping high-resource language translation quality on-par with competitive bilingual baselines. We provide in-depth analysis of various aspects of model building that are crucial to achieving quality and practicality in universal NMT. While we prototype a high-quality universal translation system, our extensive empirical analysis exposes issues that need to be further addressed, and we suggest directions for future research.