 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecommending Burgers based on Pizza Preferences: Addressing Data Sparsity with a Product of Experts
Apr 26, 2021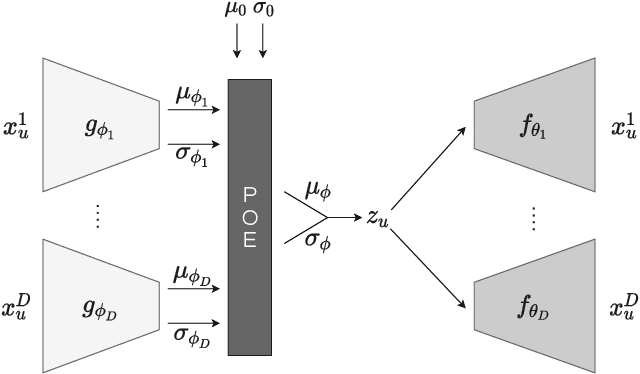
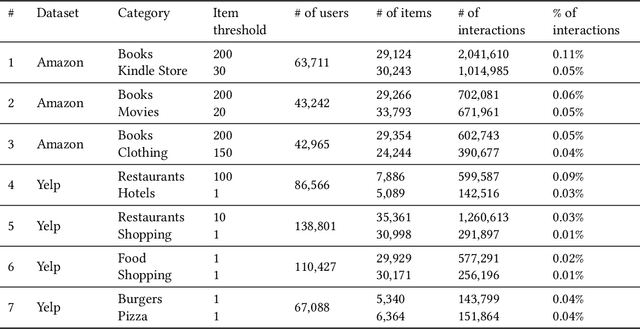
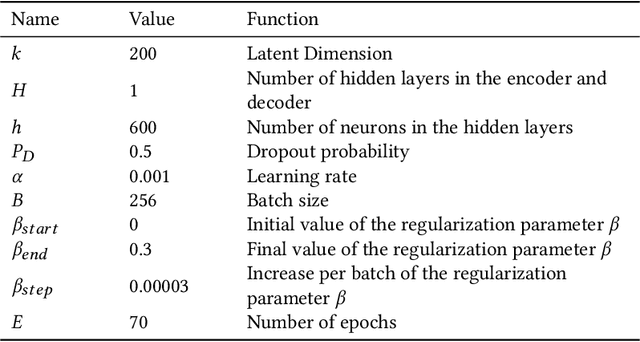
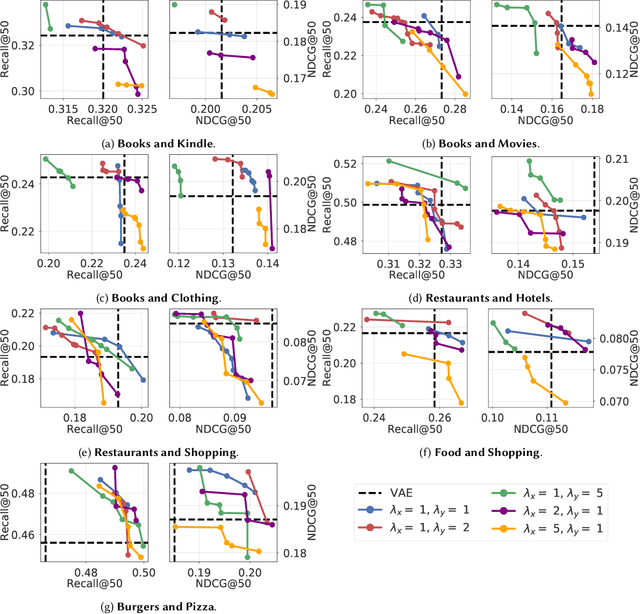
In this paper we describe a method to tackle data sparsity and create recommendations in domains with limited knowledge about the user preferences. We expand the variational autoencoder collaborative filtering from a single-domain to a multi domain setting. The intuition is that user-item interactions in a source domain can augment the recommendation quality in a target domain. The intuition can be taken to its extreme, where, in a cross-domain setup, the user history in a source domain is enough to generate high quality recommendations in a target one. We thus create a Product-of-Experts (POE) architecture for recommendations that jointly models user-item interactions across multiple domains. The method is resilient to missing data for one or more of the domains, which is a situation often found in real life. We present results on two widely-used datasets - Amazon and Yelp, which support the claim that holistic user preference knowledge leads to better recommendations. Surprisingly, we find that in select cases, a POE recommender that does not access the target domain user representation can surpass a strong VAE recommender baseline trained on the target domain. We complete the analysis with a study of the reasons behind this outperformance and an in-depth look at the resulting embedding spaces.
OpenCSI: An Open-Source Dataset for Indoor Localization Using CSI-Based Fingerprinting
Apr 16, 2021
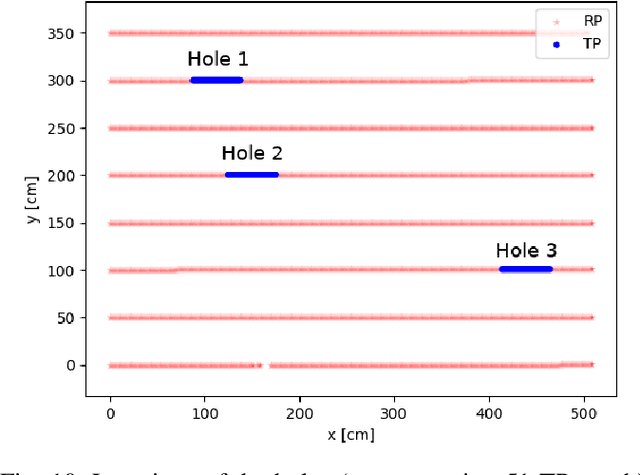
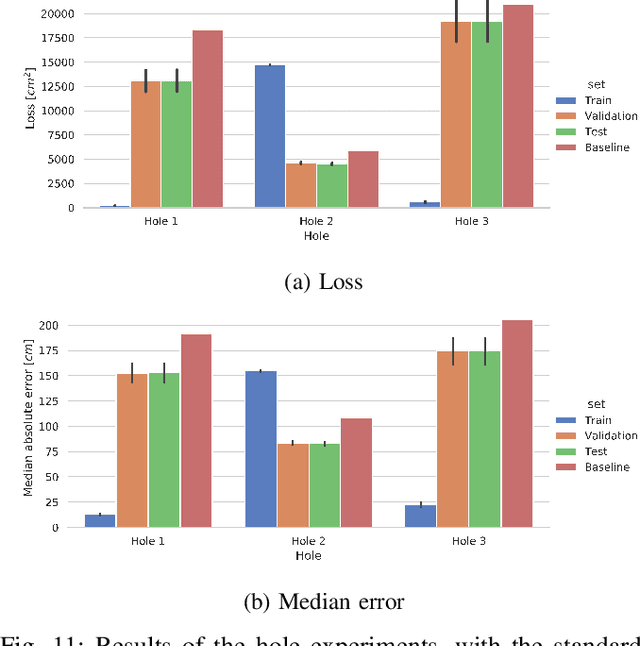
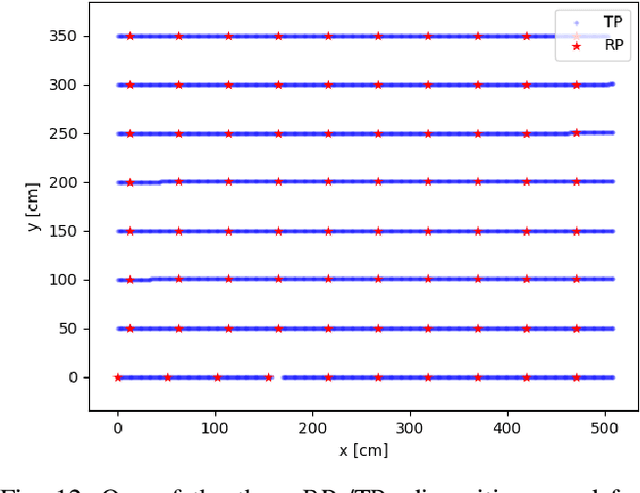
Many applications require accurate indoor localization. Fingerprint-based localization methods propose a solution to this problem, but rely on a radio map that is effort-intensive to acquire. We automate the radio map acquisition phase using a software-defined radio (SDR) and a wheeled robot. Furthermore, we open-source a radio map acquired with our automated tool for a 3GPP Long-Term Evolution (LTE) wireless link. To the best of our knowledge, this is the first publicly available radio map containing channel state information (CSI). Finally, we describe first localization experiments on this radio map using a convolutional neural network to regress for location coordinates.
Modeling Online Behavior in Recommender Systems: The Importance of Temporal Context
Sep 19, 2020
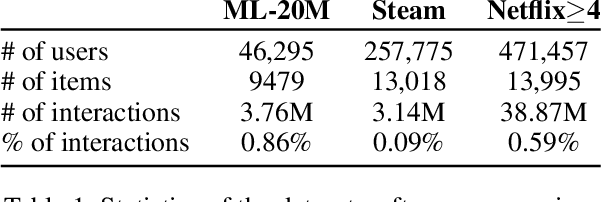
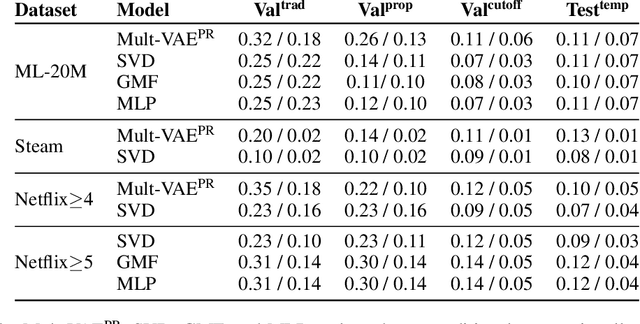
Simulating online recommender system performance is notoriously difficult and the discrepancy between the online and offline behaviors is typically not accounted for in offline evaluations. Recommender systems research tends to evaluate model performance on randomly sampled targets, yet the same systems are later used to predict user behavior sequentially from a fixed point in time. This disparity permits weaknesses to go unnoticed until the model is deployed in a production setting. We first demonstrate how omitting temporal context when evaluating recommender system performance leads to false confidence. To overcome this, we propose an offline evaluation protocol modeling the real-life use-case that simultaneously accounts for temporal context. Next, we propose a training procedure to further embed the temporal context in existing models: we introduce it in a multi-objective approach to traditionally time-unaware recommender systems. We confirm the advantage of adding a temporal objective via the proposed evaluation protocol. Finally, we validate that the Pareto Fronts obtained with the added objective dominate those produced by state-of-the-art models that are only optimized for accuracy on three real-world publicly available datasets. The results show that including our temporal objective can improve recall@20 by up to 20%.
Addressing Fairness in Classification with a Model-Agnostic Multi-Objective Algorithm
Sep 14, 2020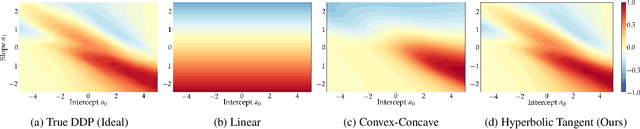
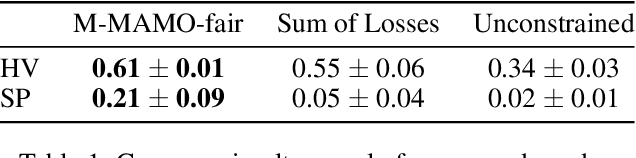
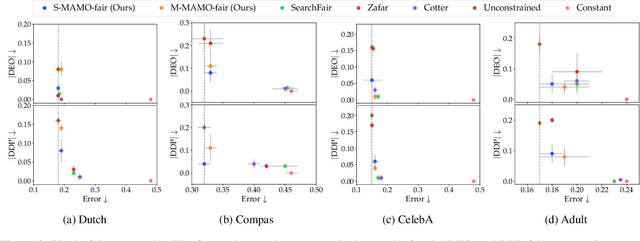
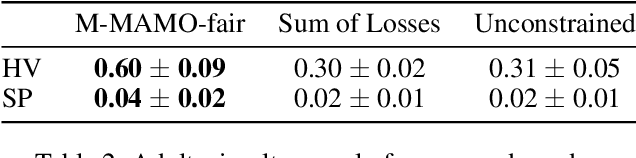
The goal of fairness in classification is to learn a classifier that does not discriminate against groups of individuals based on sensitive attributes, such as race and gender. One approach to designing fair algorithms is to use relaxations of fairness notions as regularization terms or in a constrained optimization problem. We observe that the hyperbolic tangent function can approximate the indicator function. We leverage this property to define a differentiable relaxation that approximates fairness notions provably better than existing relaxations. In addition, we propose a model-agnostic multi-objective architecture that can simultaneously optimize for multiple fairness notions and multiple sensitive attributes and supports all statistical parity-based notions of fairness. We use our relaxation with the multi-objective architecture to learn fair classifiers. Experiments on public datasets show that our method suffers a significantly lower loss of accuracy than current debiasing algorithms relative to the unconstrained model.
Momentum-based Gradient Methods in Multi-objective Recommender Systems
Sep 10, 2020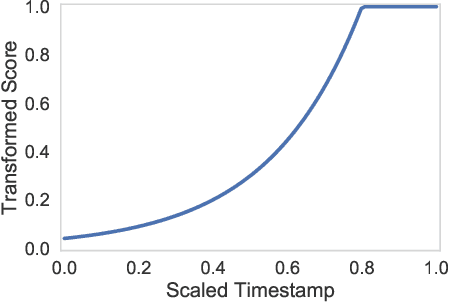

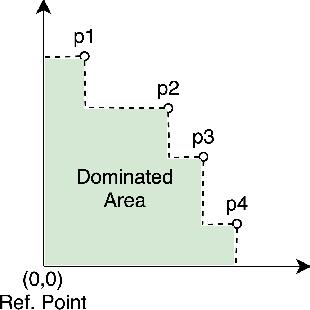
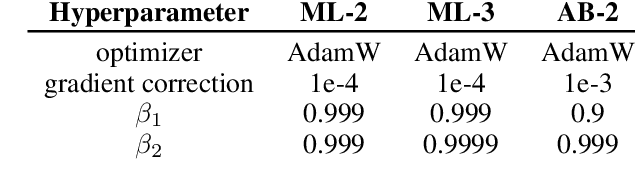
Multi-objective gradient methods are becoming the standard for solving multi-objective problems. Among others, they show promising results in developing multi-objective recommender systems with both correlated and uncorrelated objectives. Classic multi-gradient descent usually relies on the combination of the gradients, not including the computation of first and second moments of the gradients. This leads to a brittle behavior and misses important areas in the solution space. In this work, we create a multi-objective Adamize method that leverage the benefits of the Adam optimizer in single-objective problems. This corrects and stabilizes the gradients of every objective before calculating a common gradient descent vector that optimizes all the objectives simultaneously. We evaluate the benefits of Multi-objective Adamize on two multi-objective recommender systems and for three different objective combinations, both correlated or uncorrelated. We report significant improvements, measured with three different Pareto front metrics: hypervolume, coverage, and spacing. Finally, we show that the Adamized Pareto front strictly dominates the previous one on multiple objective pairs.
Benefitting from Bicubically Down-Sampled Images for Learning Real-World Image Super-Resolution
Jul 06, 2020
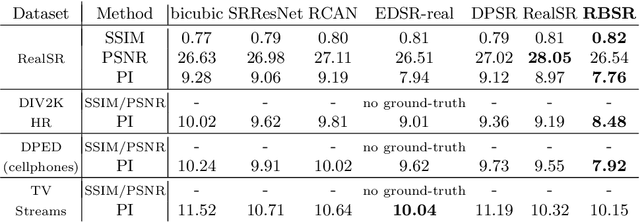
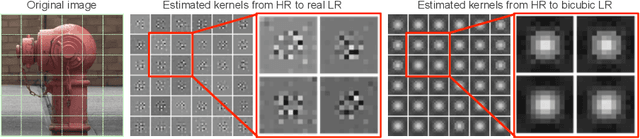
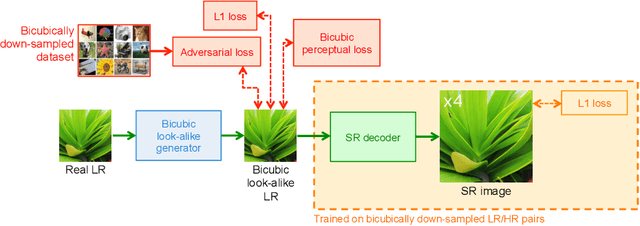
Super-resolution (SR) has traditionally been based on pairs of high-resolution images (HR) and their low-resolution (LR) counterparts obtained artificially with bicubic downsampling. However, in real-world SR, there is a large variety of realistic image degradations and analytically modeling these realistic degradations can prove quite difficult. In this work, we propose to handle real-world SR by splitting this ill-posed problem into two comparatively more well-posed steps. First, we train a network to transform real LR images to the space of bicubically downsampled images in a supervised manner, by using both real LR/HR pairs and synthetic pairs. Second, we take a generic SR network trained on bicubically downsampled images to super-resolve the transformed LR image. The first step of the pipeline addresses the problem by registering the large variety of degraded images to a common, well understood space of images. The second step then leverages the already impressive performance of SR on bicubically downsampled images, sidestepping the issues of end-to-end training on datasets with many different image degradations. We demonstrate the effectiveness of our proposed method by comparing it to recent methods in real-world SR and show that our proposed approach outperforms the state-of-the-art works in terms of both qualitative and quantitative results, as well as results of an extensive user study conducted on several real image datasets.
T-RECS: a Transformer-based Recommender Generating Textual Explanations and Integrating Unsupervised Language-based Critiquing
May 22, 2020



Supporting recommendations with personalized and relevant explanations increases trust and perceived quality, and helps users make better decisions. Prior work attempted to generate a synthetic review or review segment as an explanation, but they were not judged convincing in evaluations by human users. We propose T-RECS, a multi-task learning Transformer-based model that jointly performs recommendation with textual explanations using a novel multi-aspect masking technique. We show that human users significantly prefer the justifications generated by T-RECS than those generated by state-of-the-art techniques. At the same time, experiments on two datasets show that T-RECS slightly improves on the recommendation performance of strong state-of-the-art baselines. Another feature of T-RECS is that it allows users to react to a recommendation by critiquing the textual explanation. The system updates its user model and the resulting recommendations according to the critique. This is based on a novel unsupervised critiquing method for single- and multi-step critiquing with textual explanations. Experiments on two real-world datasets show that T-RECS is the first to obtain good performance in adapting to the preferences expressed in multi-step critiquing.
Control, Generate, Augment: A Scalable Framework for Multi-Attribute Text Generation
Apr 30, 2020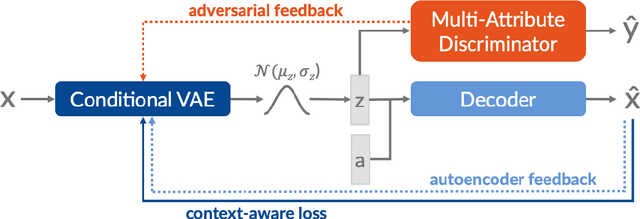


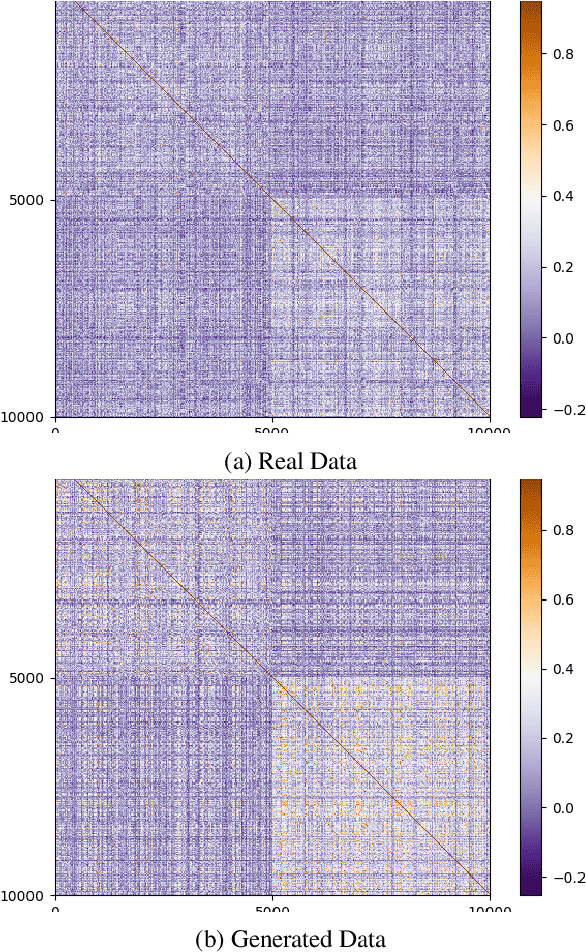
In this work, we present a text generation approach with multi-attribute control for data augmentation. We introduce CGA, a Variational Autoencoder architecture, to control, generate, and augment text. CGA is able to generate natural sentences with multiple controlled attributes by combining adversarial learning with a context-aware loss. The scalability of our approach is established through a single discriminator, independently of the number of attributes. As the main application of our work, we test the potential of this new model in a data augmentation use case. In a downstream NLP task, the sentences generated by our CGA model not only show significant improvements over a strong baseline, but also a classification performance very similar to real data. Furthermore, we are able to show high quality, diversity and attribute control in the generated sentences through a series of automatic and human assessments.
A Swiss German Dictionary: Variation in Speech and Writing
Mar 31, 2020
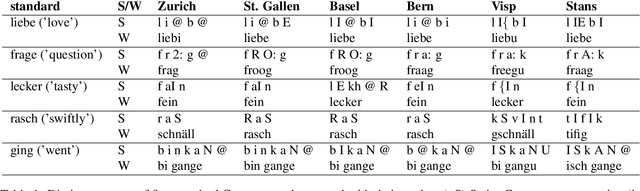

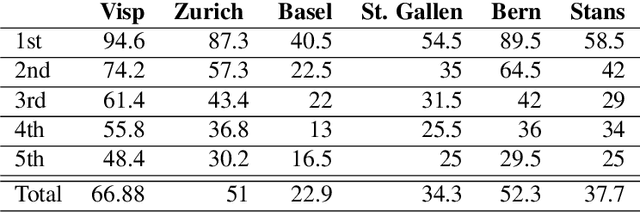
We introduce a dictionary containing forms of common words in various Swiss German dialects normalized into High German. As Swiss German is, for now, a predominantly spoken language, there is a significant variation in the written forms, even between speakers of the same dialect. To alleviate the uncertainty associated with this diversity, we complement the pairs of Swiss German - High German words with the Swiss German phonetic transcriptions (SAMPA). This dictionary becomes thus the first resource to combine large-scale spontaneous translation with phonetic transcriptions. Moreover, we control for the regional distribution and insure the equal representation of the major Swiss dialects. The coupling of the phonetic and written Swiss German forms is powerful. We show that they are sufficient to train a Transformer-based phoneme to grapheme model that generates credible novel Swiss German writings. In addition, we show that the inverse mapping - from graphemes to phonemes - can be modeled with a transformer trained with the novel dictionary. This generation of pronunciations for previously unknown words is key in training extensible automated speech recognition (ASR) systems, which are key beneficiaries of this dictionary.
Fast Cross-domain Data Augmentation through Neural Sentence Editing
Mar 23, 2020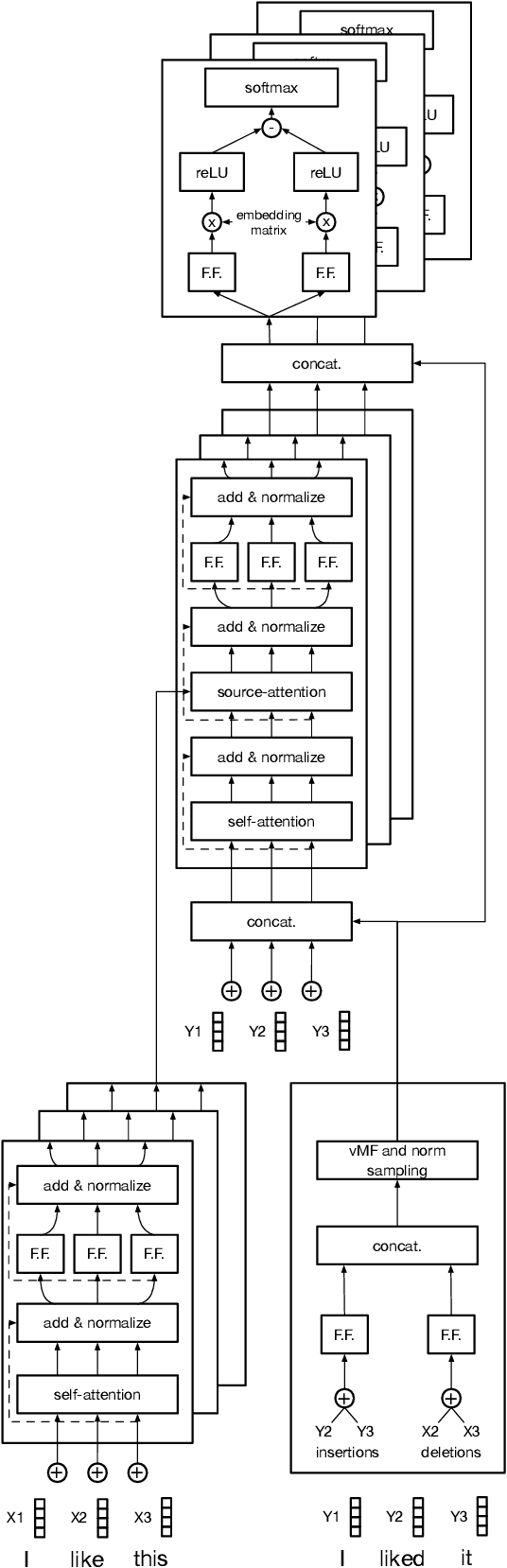

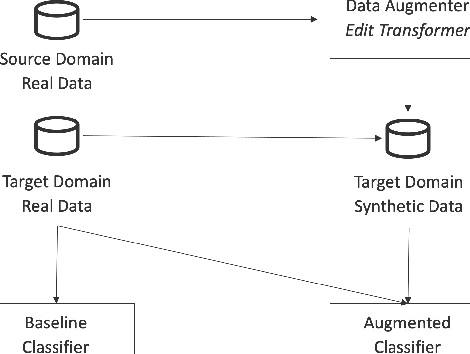
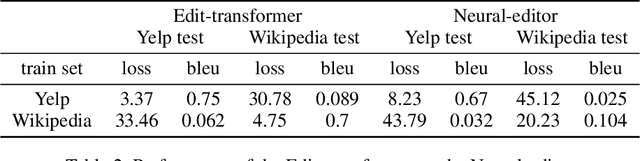
Data augmentation promises to alleviate data scarcity. This is most important in cases where the initial data is in short supply. This is, for existing methods, also where augmenting is the most difficult, as learning the full data distribution is impossible. For natural language, sentence editing offers a solution - relying on small but meaningful changes to the original ones. Learning which changes are meaningful also requires large amounts of training data. We thus aim to learn this in a source domain where data is abundant and apply it in a different, target domain, where data is scarce - cross-domain augmentation. We create the Edit-transformer, a Transformer-based sentence editor that is significantly faster than the state of the art and also works cross-domain. We argue that, due to its structure, the Edit-transformer is better suited for cross-domain environments than its edit-based predecessors. We show this performance gap on the Yelp-Wikipedia domain pairs. Finally, we show that due to this cross-domain performance advantage, the Edit-transformer leads to meaningful performance gains in several downstream tasks.