 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship Between Feature Attribution Methods and Model Performance
May 22, 2024

Machine learning and deep learning models are pivotal in educational contexts, particularly in predicting student success. Despite their widespread application, a significant gap persists in comprehending the factors influencing these models' predictions, especially in explainability within education. This work addresses this gap by employing nine distinct explanation methods and conducting a comprehensive analysis to explore the correlation between the agreement among these methods in generating explanations and the predictive model's performance. Applying Spearman's correlation, our findings reveal a very strong correlation between the model's performance and the agreement level observed among the explanation methods.
T-Explainer: A Model-Agnostic Explainability Framework Based on Gradients
Apr 25, 2024The development of machine learning applications has increased significantly in recent years, motivated by the remarkable ability of learning-powered systems to discover and generalize intricate patterns hidden in massive datasets. Modern learning models, while powerful, often exhibit a level of complexity that renders them opaque black boxes, resulting in a notable lack of transparency that hinders our ability to decipher their decision-making processes. Opacity challenges the interpretability and practical application of machine learning, especially in critical domains where understanding the underlying reasons is essential for informed decision-making. Explainable Artificial Intelligence (XAI) rises to meet that challenge, unraveling the complexity of black boxes by providing elucidating explanations. Among the various XAI approaches, feature attribution/importance XAI stands out for its capacity to delineate the significance of input features in the prediction process. However, most existing attribution methods have limitations, such as instability, when divergent explanations may result from similar or even the same instance. In this work, we introduce T-Explainer, a novel local additive attribution explainer based on Taylor expansion endowed with desirable properties, such as local accuracy and consistency, while stable over multiple runs. We demonstrate T-Explainer's effectiveness through benchmark experiments with well-known attribution methods. In addition, T-Explainer is developed as a comprehensive XAI framework comprising quantitative metrics to assess and visualize attribution explanations.
Towards Global-Scale Crowd+AI Techniques to Map and Assess Sidewalks for People with Disabilities
Jun 28, 2022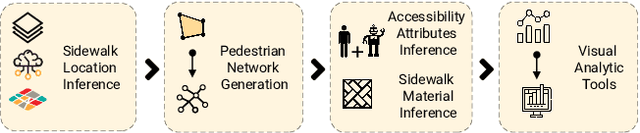


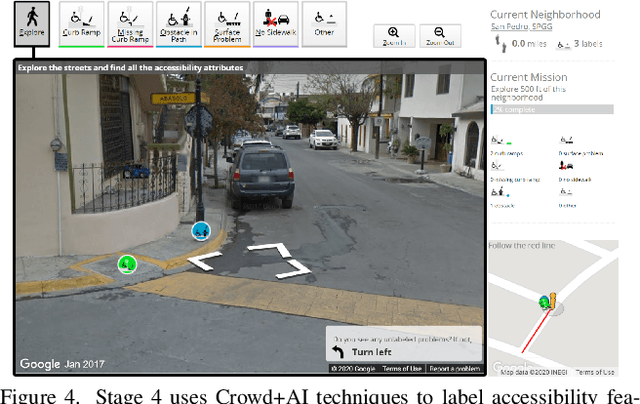
There is a lack of data on the location, condition, and accessibility of sidewalks across the world, which not only impacts where and how people travel but also fundamentally limits interactive mapping tools and urban analytics. In this paper, we describe initial work in semi-automatically building a sidewalk network topology from satellite imagery using hierarchical multi-scale attention models, inferring surface materials from street-level images using active learning-based semantic segmentation, and assessing sidewalk condition and accessibility features using Crowd+AI. We close with a call to create a database of labeled satellite and streetscape scenes for sidewalks and sidewalk accessibility issues along with standardized benchmarks.
Urban Rhapsody: Large-scale exploration of urban soundscapes
May 25, 2022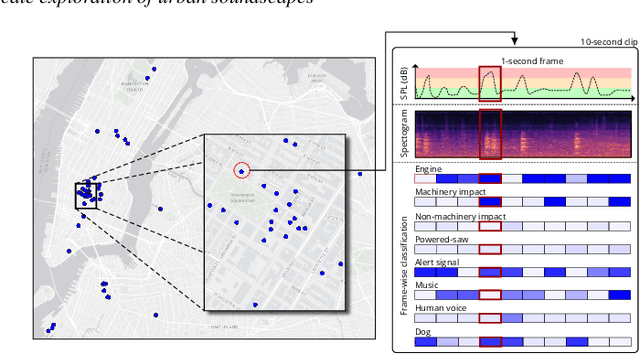
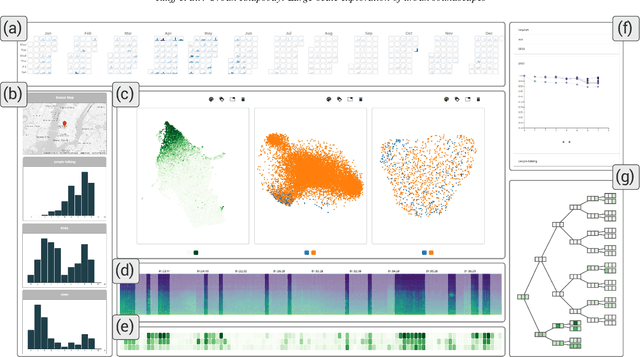
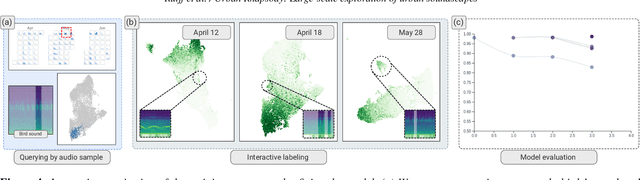
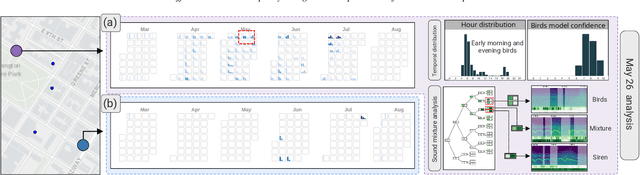
Noise is one of the primary quality-of-life issues in urban environments. In addition to annoyance, noise negatively impacts public health and educational performance. While low-cost sensors can be deployed to monitor ambient noise levels at high temporal resolutions, the amount of data they produce and the complexity of these data pose significant analytical challenges. One way to address these challenges is through machine listening techniques, which are used to extract features in attempts to classify the source of noise and understand temporal patterns of a city's noise situation. However, the overwhelming number of noise sources in the urban environment and the scarcity of labeled data makes it nearly impossible to create classification models with large enough vocabularies that capture the true dynamism of urban soundscapes In this paper, we first identify a set of requirements in the yet unexplored domain of urban soundscape exploration. To satisfy the requirements and tackle the identified challenges, we propose Urban Rhapsody, a framework that combines state-of-the-art audio representation, machine learning, and visual analytics to allow users to interactively create classification models, understand noise patterns of a city, and quickly retrieve and label audio excerpts in order to create a large high-precision annotated database of urban sound recordings. We demonstrate the tool's utility through case studies performed by domain experts using data generated over the five-year deployment of a one-of-a-kind sensor network in New York City.
Sidewalk Measurements from Satellite Images: Preliminary Findings
Dec 12, 2021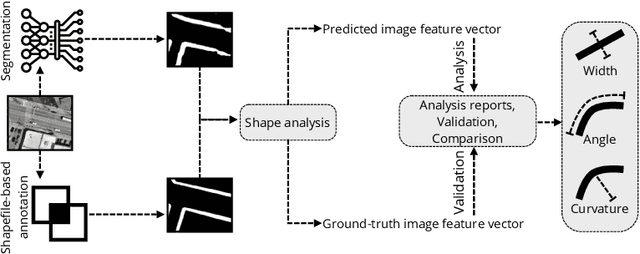
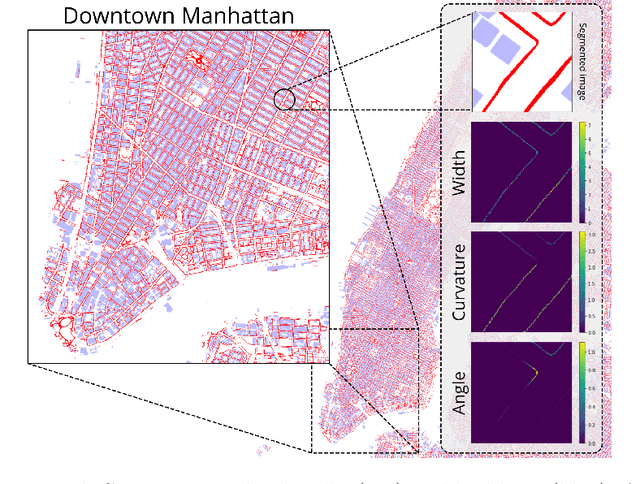
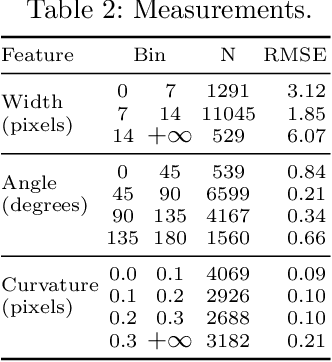
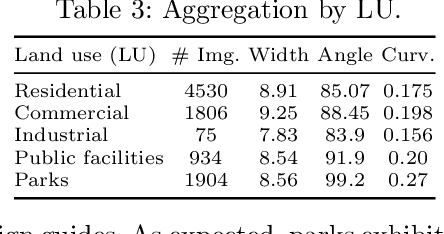
Large-scale analysis of pedestrian infrastructures, particularly sidewalks, is critical to human-centric urban planning and design. Benefiting from the rich data set of planimetric features and high-resolution orthoimages provided through the New York City Open Data portal, we train a computer vision model to detect sidewalks, roads, and buildings from remote-sensing imagery and achieve 83% mIoU over held-out test set. We apply shape analysis techniques to study different attributes of the extracted sidewalks. More specifically, we do a tile-wise analysis of the width, angle, and curvature of sidewalks, which aside from their general impacts on walkability and accessibility of urban areas, are known to have significant roles in the mobility of wheelchair users. The preliminary results are promising, glimpsing the potential of the proposed approach to be adopted in different cities, enabling researchers and practitioners to have a more vivid picture of the pedestrian realm.
IntentVizor: Towards Generic Query Guided Interactive Video Summarization Using Slow-Fast Graph Convolutional Networks
Sep 30, 2021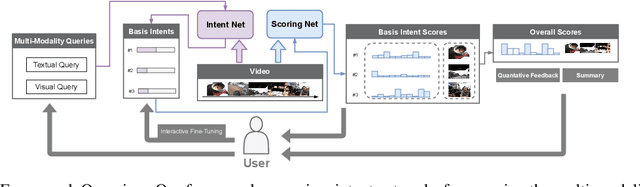
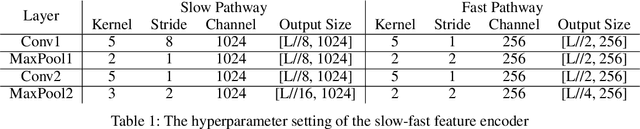
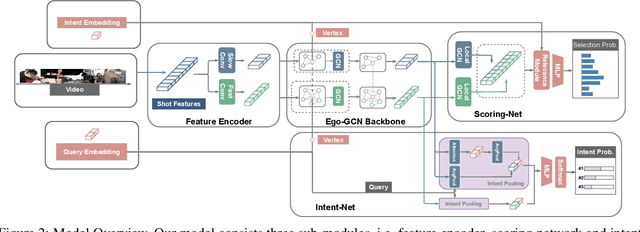
The target of automatic Video summarization is to create a short skim of the original long video while preserving the major content/events. There is a growing interest in the integration of user's queries into video summarization, or query-driven video summarization. This video summarization method predicts a concise synopsis of the original video based on the user query, which is commonly represented by the input text. However, two inherent problems exist in this query-driven way. First, the query text might not be enough to describe the exact and diverse needs of the user. Second, the user cannot edit once the summaries are produced, limiting this summarization technique's practical value. We assume the needs of the user should be subtle and need to be adjusted interactively. To solve these two problems, we propose a novel IntentVizor framework, which is an interactive video summarization framework guided by genric multi-modality queries. The input query that describes the user's needs is not limited to text but also the video snippets. We further conclude these multi-modality finer-grained queries as user `intent', which is a newly proposed concept in this paper. This intent is interpretable, interactable, and better quantifies/describes the user's needs. To be more specific, We use a set of intents to represent the inputs of users to design our new interactive visual analytic interface. Users can interactively control and adjust these mixed-initiative intents to obtain a more satisfying summary of this newly proposed interface. Also, as algorithms help users achieve their summarization goal via video understanding, we propose two novel intent/scoring networks based on the slow-fast feature for our algorithm part. We conduct our experiments on two benchmark datasets. The comparison with the state-of-the-art methods verifies the effectiveness of the proposed framework.
ERA: Entity Relationship Aware Video Summarization with Wasserstein GAN
Sep 06, 2021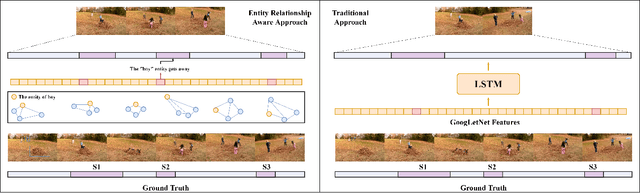
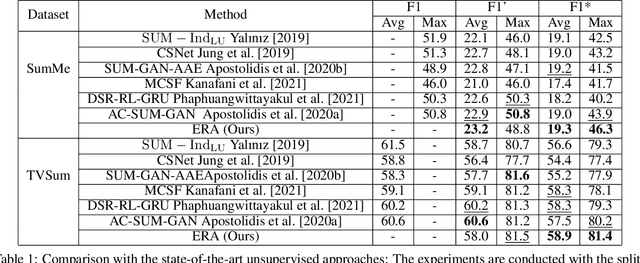
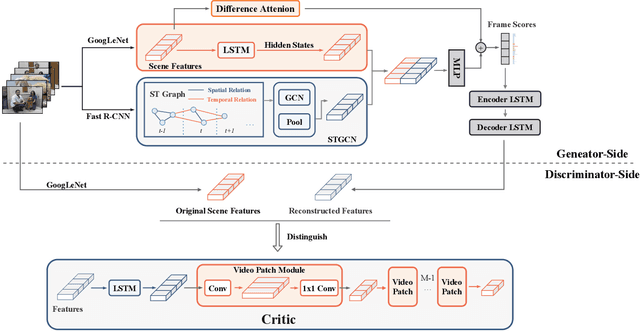

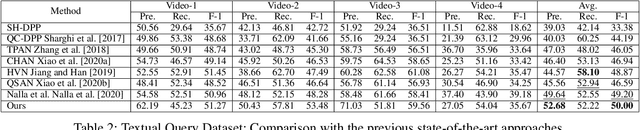
Video summarization aims to simplify large scale video browsing by generating concise, short summaries that diver from but well represent the original video. Due to the scarcity of video annotations, recent progress for video summarization concentrates on unsupervised methods, among which the GAN based methods are most prevalent. This type of methods includes a summarizer and a discriminator. The summarized video from the summarizer will be assumed as the final output, only if the video reconstructed from this summary cannot be discriminated from the original one by the discriminator. The primary problems of this GAN based methods are two folds. First, the summarized video in this way is a subset of original video with low redundancy and contains high priority events/entities. This summarization criterion is not enough. Second, the training of the GAN framework is not stable. This paper proposes a novel Entity relationship Aware video summarization method (ERA) to address the above problems. To be more specific, we introduce an Adversarial Spatio Temporal network to construct the relationship among entities, which we think should also be given high priority in the summarization. The GAN training problem is solved by introducing the Wasserstein GAN and two newly proposed video patch/score sum losses. In addition, the score sum loss can also relieve the model sensitivity to the varying video lengths, which is an inherent problem for most current video analysis tasks. Our method substantially lifts the performance on the target benchmark datasets and exceeds the current leaderboard Rank 1 state of the art CSNet (2.1% F1 score increase on TVSum and 3.1% F1 score increase on SumMe). We hope our straightforward yet effective approach will shed some light on the future research of unsupervised video summarization.
Learning Geo-Contextual Embeddings for Commuting Flow Prediction
May 04, 2020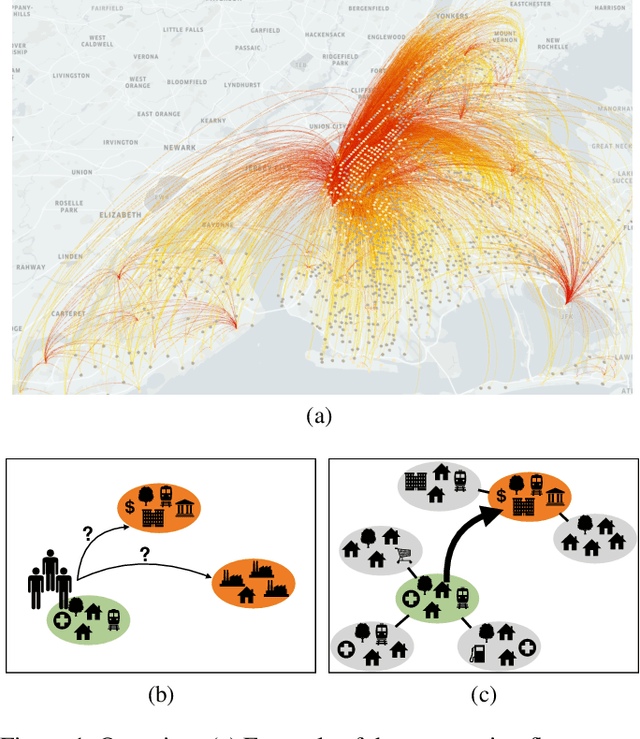
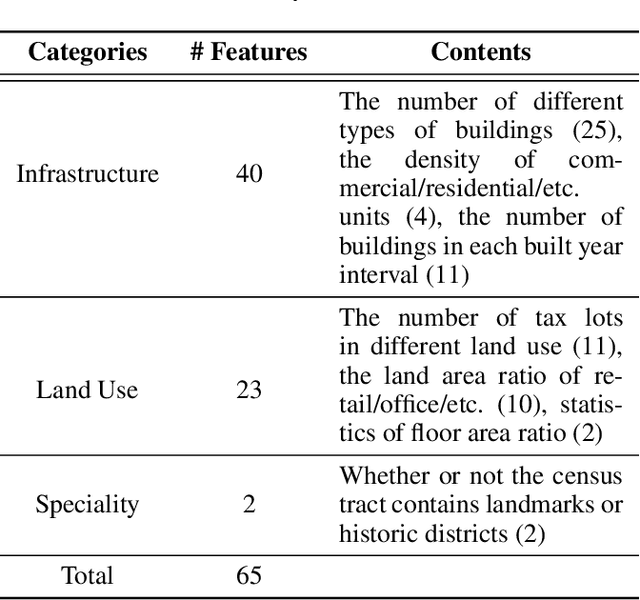
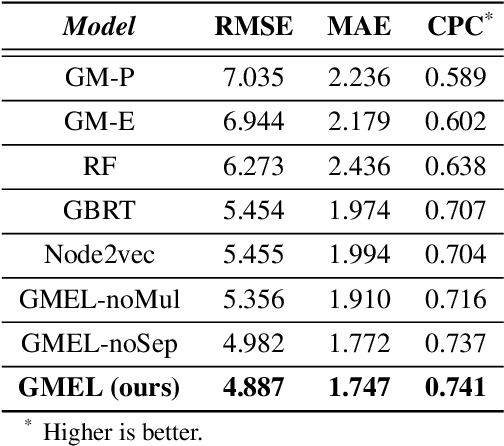
Predicting commuting flows based on infrastructure and land-use information is critical for urban planning and public policy development. However, it is a challenging task given the complex patterns of commuting flows. Conventional models, such as gravity model, are mainly derived from physics principles and limited by their predictive power in real-world scenarios where many factors need to be considered. Meanwhile, most existing machine learning-based methods ignore the spatial correlations and fail to model the influence of nearby regions. To address these issues, we propose Geo-contextual Multitask Embedding Learner (GMEL), a model that captures the spatial correlations from geographic contextual information for commuting flow prediction. Specifically, we first construct a geo-adjacency network containing the geographic contextual information. Then, an attention mechanism is proposed based on the framework of graph attention network (GAT) to capture the spatial correlations and encode geographic contextual information to embedding space. Two separate GATs are used to model supply and demand characteristics. A multitask learning framework is used to introduce stronger restrictions and enhance the effectiveness of the embedding representation. Finally, a gradient boosting machine is trained based on the learned embeddings to predict commuting flows. We evaluate our model using real-world datasets from New York City and the experimental results demonstrate the effectiveness of our proposal against the state of the art.
* Github: https://github.com/jackmiemie/GMEL
A Tracking System For Baseball Game Reconstruction
Mar 08, 2020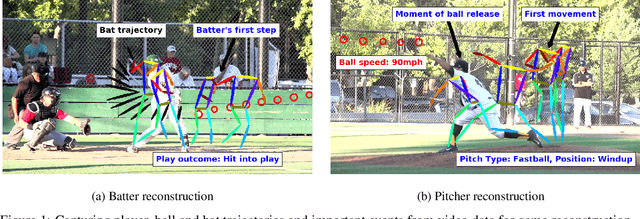

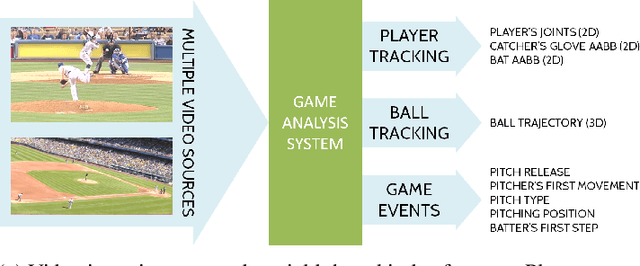

The baseball game is often seen as many contests that are performed between individuals. The duel between the pitcher and the batter, for example, is considered the engine that drives the sport. The pitchers use a variety of strategies to gain competitive advantage against the batter, who does his best to figure out the ball trajectory and react in time for a hit. In this work, we propose a system that captures the movements of the pitcher, the batter, and the ball in a high level of detail, and discuss several ways how this information may be processed to compute interesting statistics. We demonstrate on a large database of videos that our methods achieve comparable results as previous systems, while operating solely on video material. In addition, state-of-the-art AI techniques are incorporated to augment the amount of information that is made available for players, coaches, teams, and fans.
FlowSense: A Natural Language Interface for Visual Data Exploration within a Dataflow System
Aug 02, 2019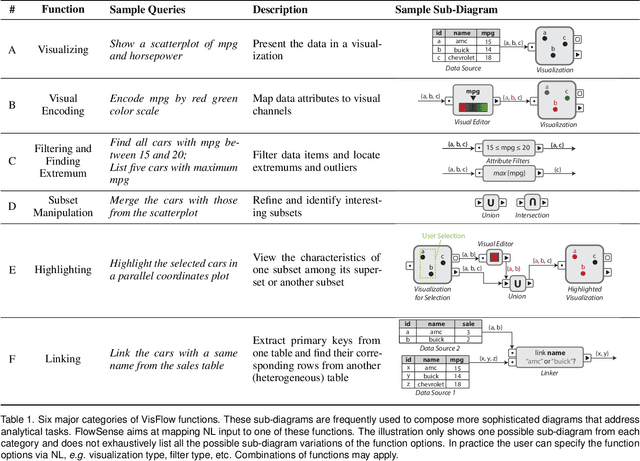

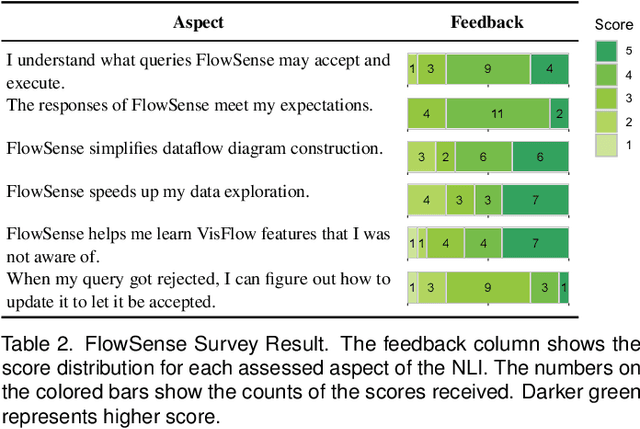

Dataflow visualization systems enable flexible visual data exploration by allowing the user to construct a dataflow diagram that composes query and visualization modules to specify system functionality. However learning dataflow diagram usage presents overhead that often discourages the user. In this work we design FlowSense, a natural language interface for dataflow visualization systems that utilizes state-of-the-art natural language processing techniques to assist dataflow diagram construction. FlowSense employs a semantic parser with special utterance tagging and special utterance placeholders to generalize to different datasets and dataflow diagrams. It explicitly presents recognized dataset and diagram special utterances to the user for dataflow context awareness. With FlowSense the user can expand and adjust dataflow diagrams more conveniently via plain English. We apply FlowSense to the VisFlow subset-flow visualization system to enhance its usability. We evaluate FlowSense by one case study with domain experts on a real-world data analysis problem and a formal user study.