 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning spatiotemporal signals using a recurrent spiking network that discretizes time
Jul 20, 2019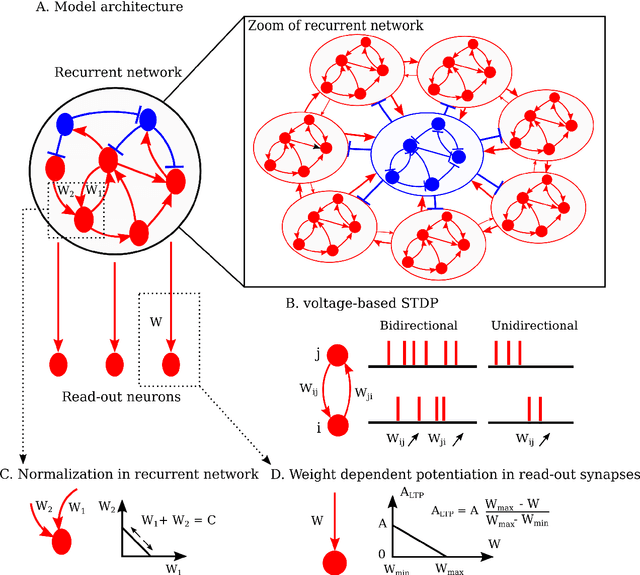

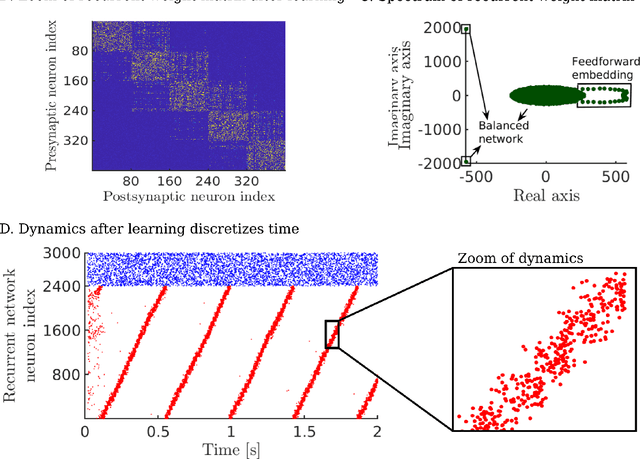

Learning to produce spatiotemporal sequences is a common task the brain has to solve. While many sequential behaviours differ superficially, the underlying organization of the computation might be similar. The way the brain learns these tasks remains unknown as current computational models do not typically use realistic biologically-plausible learning. Here, we propose a model where a spiking recurrent network drives a read-out layer. Plastic synapses follow common Hebbian learning rules. The dynamics of the recurrent network is constrained to encode time while the read-out neurons encode space. Space is then linked with time through Hebbian learning. Here we demonstrate that the model is able to learn spatiotemporal dynamics on a timescale that is behaviorally relevant. Learned sequences are robustly replayed during a regime of spontaneous activity.
Policy Consolidation for Continual Reinforcement Learning
Feb 01, 2019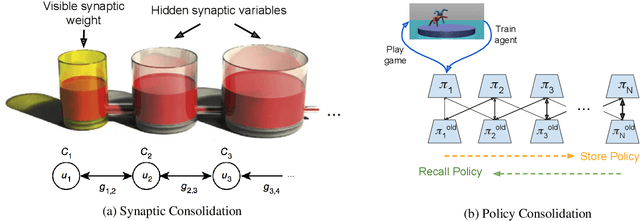
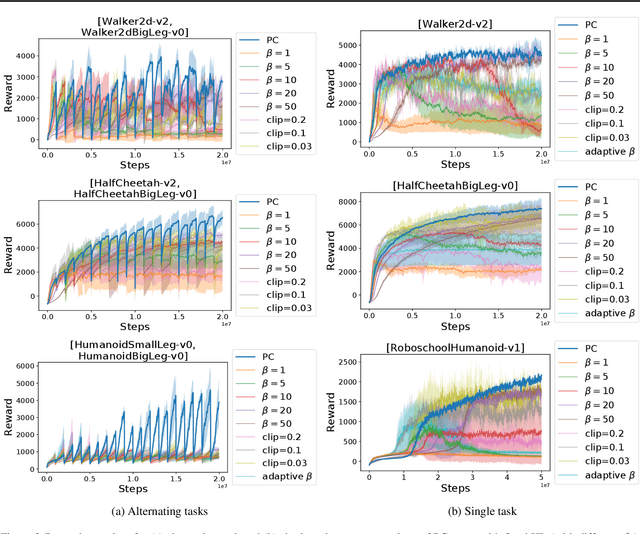
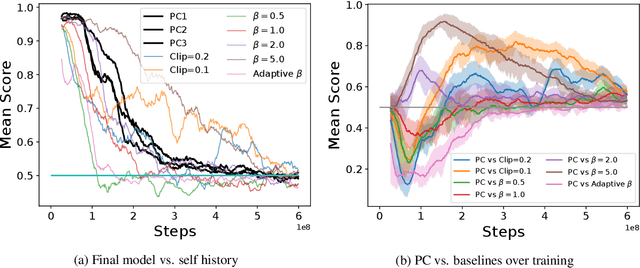
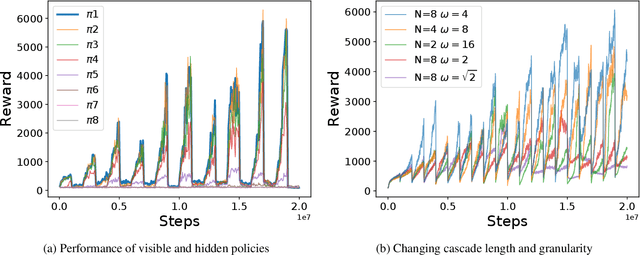
We propose a method for tackling catastrophic forgetting in deep reinforcement learning that is \textit{agnostic} to the timescale of changes in the distribution of experiences, does not require knowledge of task boundaries, and can adapt in \textit{continuously} changing environments. In our \textit{policy consolidation} model, the policy network interacts with a cascade of hidden networks that simultaneously remember the agent's policy at a range of timescales and regularise the current policy by its own history, thereby improving its ability to learn without forgetting. We find that the model improves continual learning relative to baselines on a number of continuous control tasks in single-task, alternating two-task, and multi-agent competitive self-play settings.
A High GOPs/Slice Time Series Classifier for Portable and Embedded Biomedical Applications
Nov 01, 2018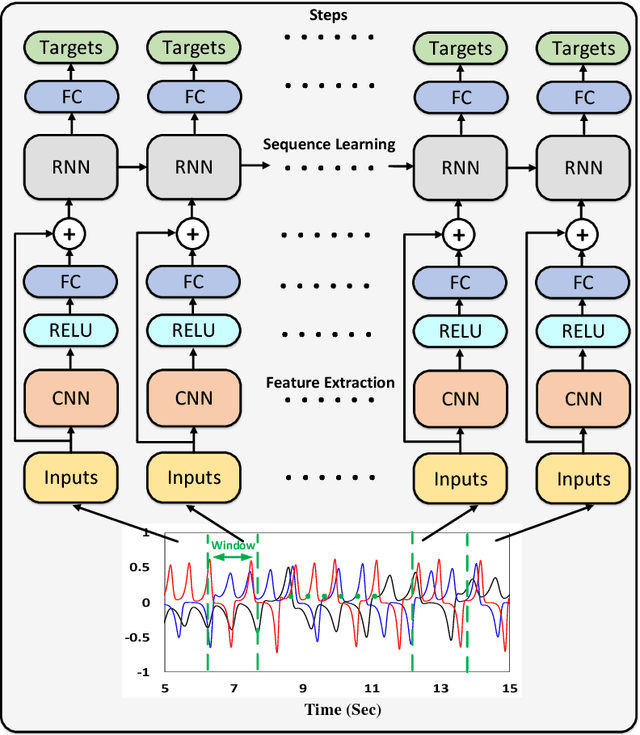

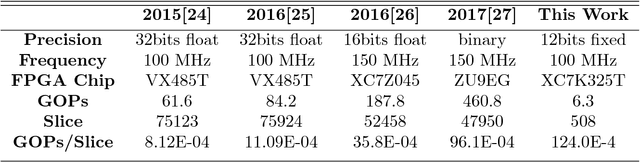
Nowadays a diverse range of physiological data can be captured continuously for various applications in particular wellbeing and healthcare. Such data require efficient methods for classification and analysis. Deep learning algorithms have shown remarkable potential regarding such analyses, however, the use of these algorithms on low-power wearable devices is challenged by resource constraints such as area and power consumption. Most of the available on-chip deep learning processors contain complex and dense hardware architectures in order to achieve the highest possible throughput. Such a trend in hardware design may not be efficient in applications where on-node computation is required and the focus is more on the area and power efficiency as in the case of portable and embedded biomedical devices. This paper presents an efficient time-series classifier capable of automatically detecting effective features and classifying the input signals in real-time. In the proposed classifier, throughput is traded off with hardware complexity and cost using resource sharing techniques. A Convolutional Neural Network (CNN) is employed to extract input features and then a Long-Short-Term-Memory (LSTM) architecture with ternary weight precision classifies the input signals according to the extracted features. Hardware implementation on a Xilinx FPGA confirm that the proposed hardware can accurately classify multiple complex biomedical time series data with low area and power consumption and outperform all previously presented state-of-the-art records. Most notably, our classifier reaches 1.3$\times$ higher GOPs/Slice than similar state of the art FPGA-based accelerators.
Continual Reinforcement Learning with Complex Synapses
Jun 19, 2018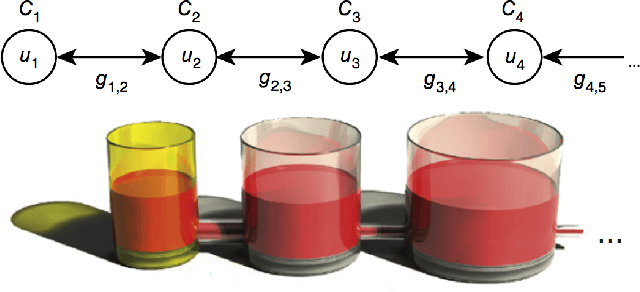
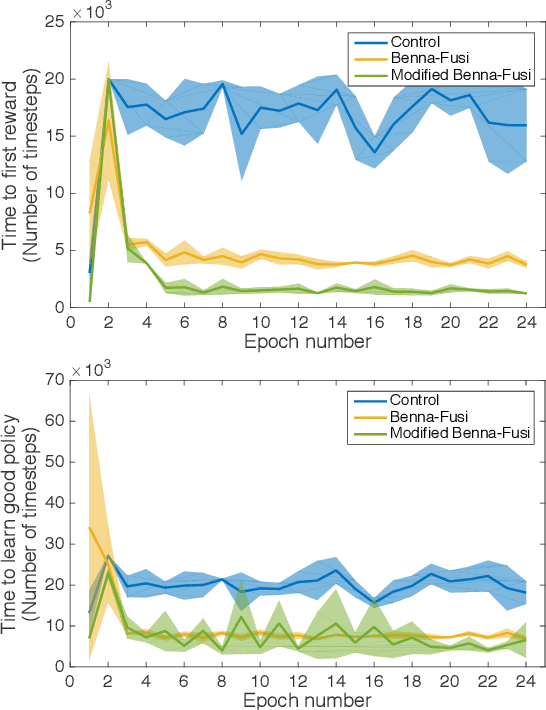
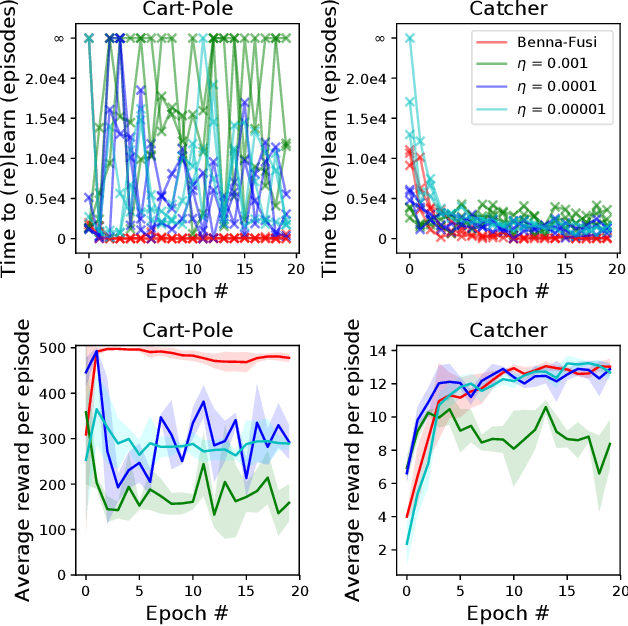
Unlike humans, who are capable of continual learning over their lifetimes, artificial neural networks have long been known to suffer from a phenomenon known as catastrophic forgetting, whereby new learning can lead to abrupt erasure of previously acquired knowledge. Whereas in a neural network the parameters are typically modelled as scalar values, an individual synapse in the brain comprises a complex network of interacting biochemical components that evolve at different timescales. In this paper, we show that by equipping tabular and deep reinforcement learning agents with a synaptic model that incorporates this biological complexity (Benna & Fusi, 2016), catastrophic forgetting can be mitigated at multiple timescales. In particular, we find that as well as enabling continual learning across sequential training of two simple tasks, it can also be used to overcome within-task forgetting by reducing the need for an experience replay database.
Overcoming catastrophic forgetting in neural networks
Jan 25, 2017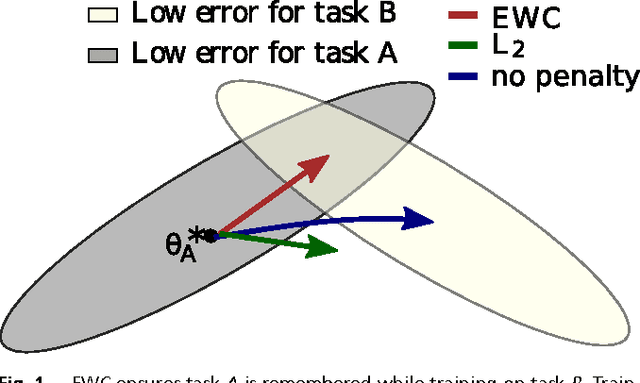
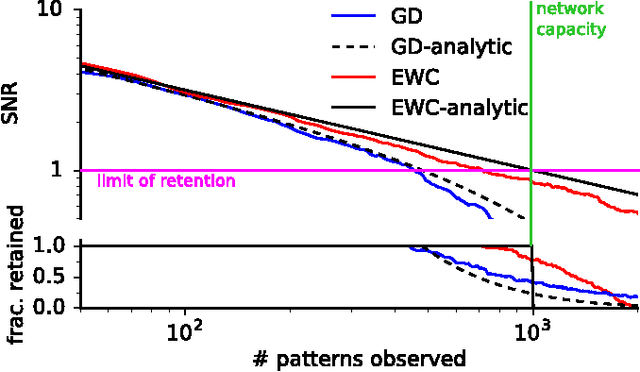
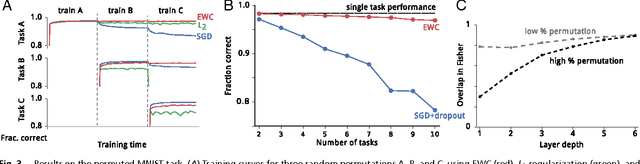
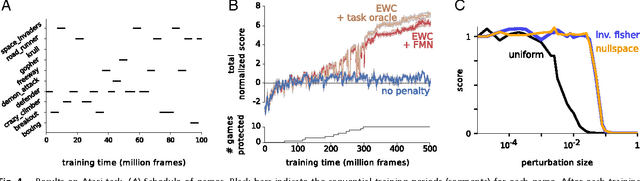
The ability to learn tasks in a sequential fashion is crucial to the development of artificial intelligence. Neural networks are not, in general, capable of this and it has been widely thought that catastrophic forgetting is an inevitable feature of connectionist models. We show that it is possible to overcome this limitation and train networks that can maintain expertise on tasks which they have not experienced for a long time. Our approach remembers old tasks by selectively slowing down learning on the weights important for those tasks. We demonstrate our approach is scalable and effective by solving a set of classification tasks based on the MNIST hand written digit dataset and by learning several Atari 2600 games sequentially.