 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSufficient Context: A New Lens on Retrieval Augmented Generation Systems
Nov 09, 2024



Augmenting LLMs with context leads to improved performance across many applications. Despite much research on Retrieval Augmented Generation (RAG) systems, an open question is whether errors arise because LLMs fail to utilize the context from retrieval or the context itself is insufficient to answer the query. To shed light on this, we develop a new notion of sufficient context, along with a way to classify instances that have enough information to answer the query. We then use sufficient context to analyze several models and datasets. By stratifying errors based on context sufficiency, we find that proprietary LLMs (Gemini, GPT, Claude) excel at answering queries when the context is sufficient, but often output incorrect answers instead of abstaining when the context is not. On the other hand, open-source LLMs (Llama, Mistral, Gemma) hallucinate or abstain often, even with sufficient context. We further categorize cases when the context is useful, and improves accuracy, even though it does not fully answer the query and the model errs without the context. Building on our findings, we explore ways to reduce hallucinations in RAG systems, including a new selective generation method that leverages sufficient context information for guided abstention. Our method improves the fraction of correct answers among times where the model responds by 2-10% for Gemini, GPT, and Gemma.
SLED: Self Logits Evolution Decoding for Improving Factuality in Large Language Models
Nov 01, 2024



Large language models (LLMs) have demonstrated remarkable capabilities, but their outputs can sometimes be unreliable or factually incorrect. To address this, we introduce Self Logits Evolution Decoding (SLED), a novel decoding framework that enhances the truthfulness of LLMs without relying on external knowledge bases or requiring further fine-tuning. From an optimization perspective, our SLED framework leverages the latent knowledge embedded within the LLM by contrasting the output logits from the final layer with those from early layers. It then utilizes an approximate gradient approach to enable latent knowledge to guide the self-refinement of outputs, thereby effectively improving factual accuracy. Extensive experiments have been conducted on established benchmarks across a diverse range of model families (LLaMA 2, LLaMA 3, Gemma) and scales (from 2B to 70B), including more advanced architectural configurations such as the mixture of experts (MoE). Our evaluation spans a wide variety of tasks, including multi-choice, open-generation, and adaptations to chain-of-thought reasoning tasks. The results demonstrate that SLED consistently improves factual accuracy by up to 20\% compared to existing decoding methods while maintaining natural language fluency and negligible latency overhead. Furthermore, it can be flexibly combined with other decoding methods to further enhance their performance.
Substance or Style: What Does Your Image Embedding Know?
Jul 10, 2023Probes are small networks that predict properties of underlying data from embeddings, and they provide a targeted, effective way to illuminate the information contained in embeddings. While analysis through the use of probes has become standard in NLP, there has been much less exploration in vision. Image foundation models have primarily been evaluated for semantic content. Better understanding the non-semantic information in popular embeddings (e.g., MAE, SimCLR, or CLIP) will shed new light both on the training algorithms and on the uses for these foundation models. We design a systematic transformation prediction task and measure the visual content of embeddings along many axes, including image style, quality, and a range of natural and artificial transformations. Surprisingly, six embeddings (including SimCLR) encode enough non-semantic information to identify dozens of transformations. We also consider a generalization task, where we group similar transformations and hold out several for testing. We find that image-text models (CLIP and ALIGN) are better at recognizing new examples of style transfer than masking-based models (CAN and MAE). Overall, our results suggest that the choice of pre-training algorithm impacts the types of information in the embedding, and certain models are better than others for non-semantic downstream tasks.
CARLS: Cross-platform Asynchronous Representation Learning System
May 26, 2021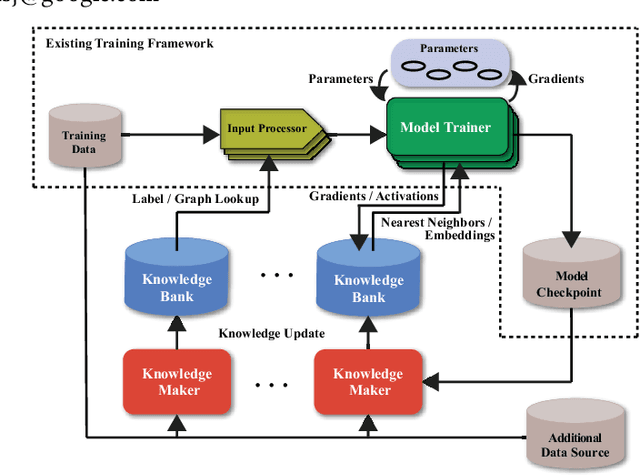
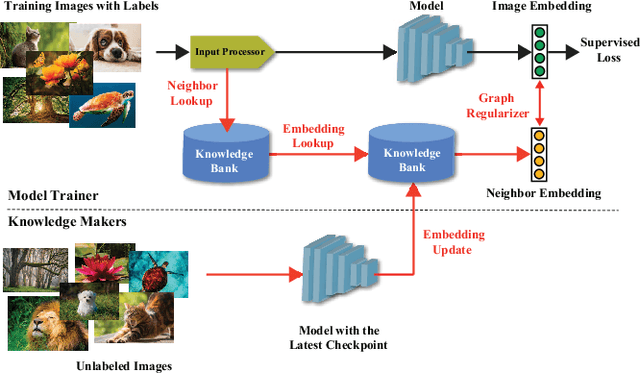
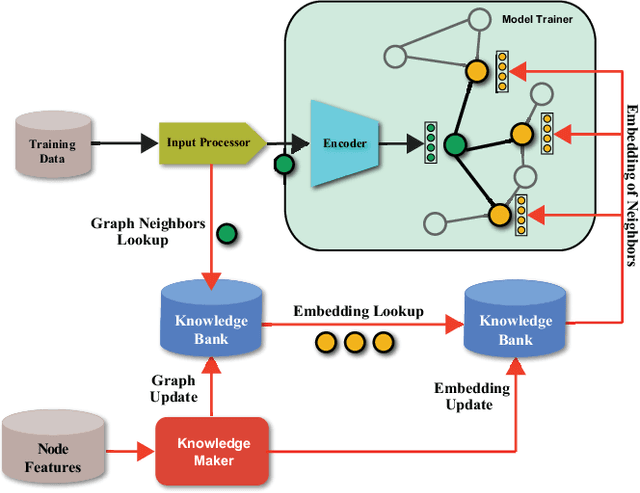
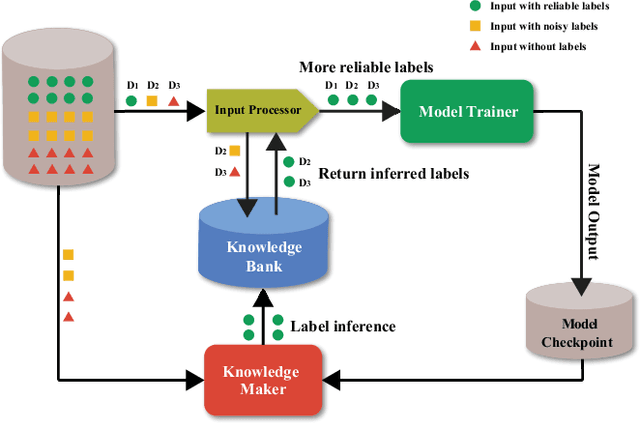
In this work, we propose CARLS, a novel framework for augmenting the capacity of existing deep learning frameworks by enabling multiple components -- model trainers, knowledge makers and knowledge banks -- to concertedly work together in an asynchronous fashion across hardware platforms. The proposed CARLS is particularly suitable for learning paradigms where model training benefits from additional knowledge inferred or discovered during training, such as node embeddings for graph neural networks or reliable pseudo labels from model predictions. We also describe three learning paradigms -- semi-supervised learning, curriculum learning and multimodal learning -- as examples that can be scaled up efficiently by CARLS. One version of CARLS has been open-sourced and available for download at: https://github.com/tensorflow/neural-structured-learning/tree/master/research/carls
Demystifying the Better Performance of Position Encoding Variants for Transformer
Apr 18, 2021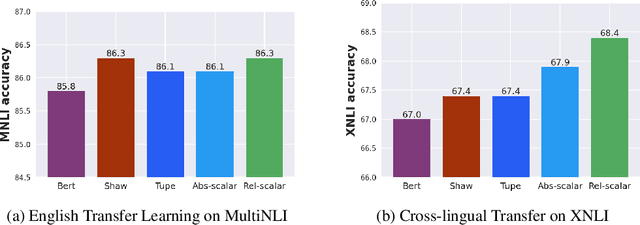

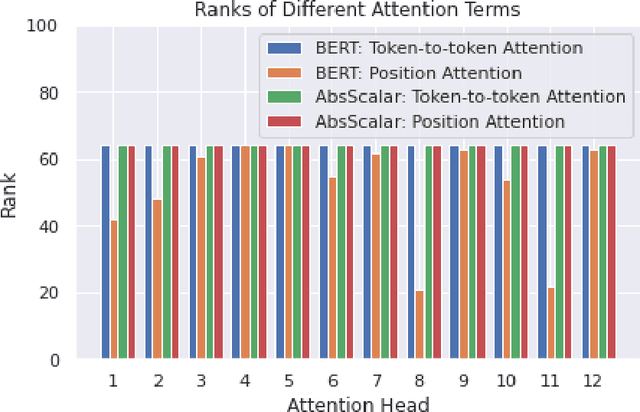

Transformers are state of the art models in NLP that map a given input sequence of vectors to an output sequence of vectors. However these models are permutation equivariant, and additive position embeddings to the input are used to supply the information about the order of the input tokens. Further, for some tasks, additional additive segment embeddings are used to denote different types of input sentences. Recent works proposed variations of positional encodings with relative position encodings achieving better performance. In this work, we do a systematic study comparing different position encodings and understanding the reasons for differences in their performance. We demonstrate a simple yet effective way to encode position and segment into the Transformer models. The proposed method performs on par with SOTA on GLUE, XTREME and WMT benchmarks while saving computation costs.
Adversarial Robustness Across Representation Spaces
Dec 01, 2020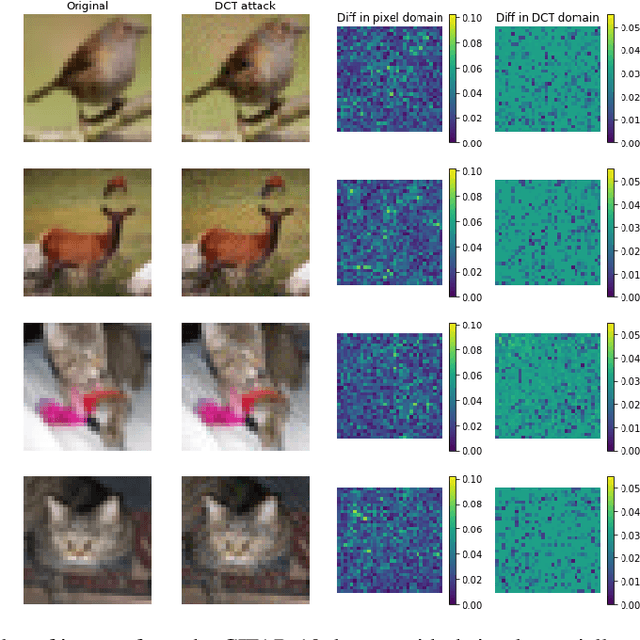
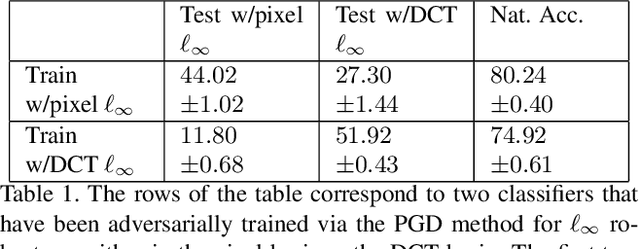

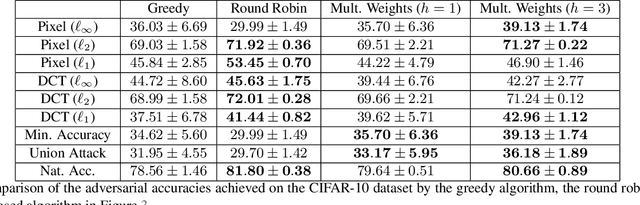
Adversarial robustness corresponds to the susceptibility of deep neural networks to imperceptible perturbations made at test time. In the context of image tasks, many algorithms have been proposed to make neural networks robust to adversarial perturbations made to the input pixels. These perturbations are typically measured in an $\ell_p$ norm. However, robustness often holds only for the specific attack used for training. In this work we extend the above setting to consider the problem of training of deep neural networks that can be made simultaneously robust to perturbations applied in multiple natural representation spaces. For the case of image data, examples include the standard pixel representation as well as the representation in the discrete cosine transform~(DCT) basis. We design a theoretically sound algorithm with formal guarantees for the above problem. Furthermore, our guarantees also hold when the goal is to require robustness with respect to multiple $\ell_p$ norm based attacks. We then derive an efficient practical implementation and demonstrate the effectiveness of our approach on standard datasets for image classification.
Finding Fast Transformers: One-Shot Neural Architecture Search by Component Composition
Aug 15, 2020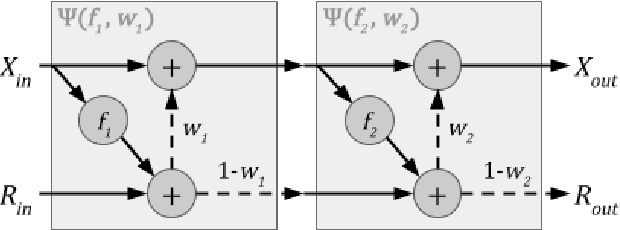
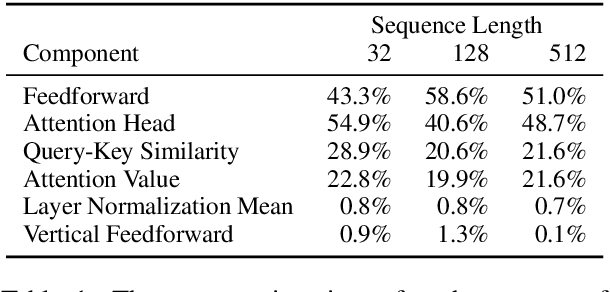
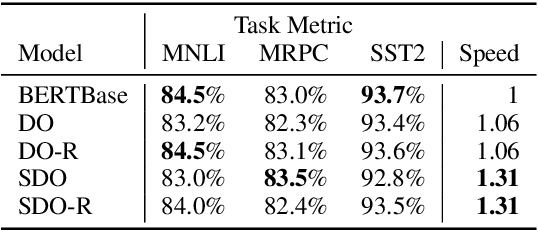
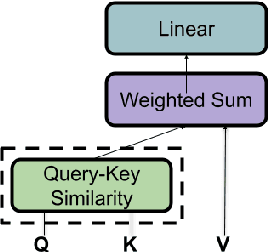
Transformer-based models have achieved stateof-the-art results in many tasks in natural language processing. However, such models are usually slow at inference time, making deployment difficult. In this paper, we develop an efficient algorithm to search for fast models while maintaining model quality. We describe a novel approach to decompose the Transformer architecture into smaller components, and propose a sampling-based one-shot architecture search method to find an optimal model for inference. The model search process is more efficient than alternatives, adding only a small overhead to training time. By applying our methods to BERT-base architectures, we achieve 10% to 30% speedup for pre-trained BERT and 70% speedup on top of a previous state-of-the-art distilled BERT model on Cloud TPU-v2 with a generally acceptable drop in performance.