 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting the Black Box: Circuit-Level Analysis of LLM Vulnerability Detection
May 28, 2026Large language models (LLMs) can detect software vulnerabilities, but how do they actually identify vulnerable code? We address this question using mechanistic interpretability; analyzing the internal computations of a neural network to understand its reasoning process.Using Circuit Tracer on Gemma-2-2b, we trace the computational pathways activated when the model classifies 472 C/C++ code samples as vulnerable or safe. Our analysis reveals a surprising finding: the model primarily relies on safety detectors, attention heads that recognize safe coding patterns, rather than directly detecting vulnerability signatures. When these safety detectors fail to activate, the model classifies code as vulnerable. We identify the critical neural components: specific attention heads in early layers (L5, L7) that focus on safety patterns, and Multilayer Perceptron (MLP) neurons in Layer 7 that encode vulnerability-related features. Ablation experiments confirm their causal role; removing Layer 11 drops vulnerability detection accuracy from 100% to 6%, while ablating just 20 neurons in Layer 7 reduces it by 50%.Our findings show that LLM vulnerability detection uses sparse, interpretable circuits (only 16% of model capacity), enabling circuit-level explanations for security predictions and targeted improvements to detection systems.
Aerial Vision-and-Dialog Navigation
May 24, 2022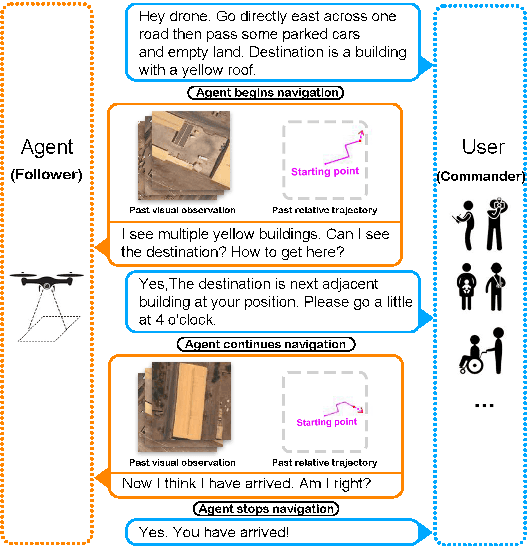
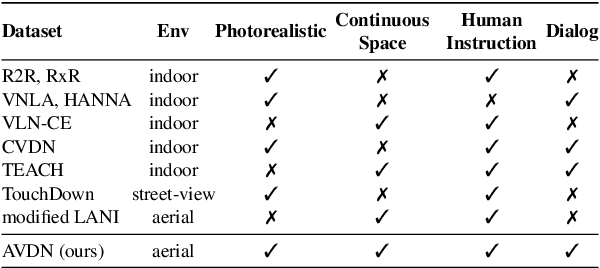

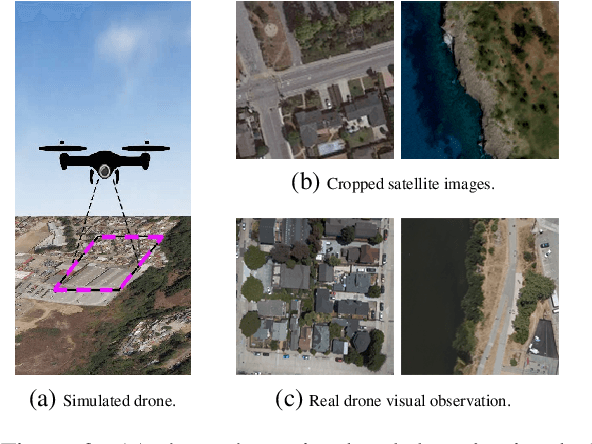
The ability to converse with humans and follow commands in natural language is crucial for intelligent unmanned aerial vehicles (a.k.a. drones). It can relieve people's burden of holding a controller all the time, allow multitasking, and make drone control more accessible for people with disabilities or with their hands occupied. To this end, we introduce Aerial Vision-and-Dialog Navigation (AVDN), to navigate a drone via natural language conversation. We build a drone simulator with a continuous photorealistic environment and collect a new AVDN dataset of over 3k recorded navigation trajectories with asynchronous human-human dialogs between commanders and followers. The commander provides initial navigation instruction and further guidance by request, while the follower navigates the drone in the simulator and asks questions when needed. During data collection, followers' attention on the drone's visual observation is also recorded. Based on the AVDN dataset, we study the tasks of aerial navigation from (full) dialog history and propose an effective Human Attention Aided (HAA) baseline model, which learns to predict both navigation waypoints and human attention. Dataset and code will be released.