 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation-Rich Visual Document Generator for Visual Information Extraction
Apr 14, 2025Despite advances in Large Language Models (LLMs) and Multimodal LLMs (MLLMs) for visual document understanding (VDU), visual information extraction (VIE) from relation-rich documents remains challenging due to the layout diversity and limited training data. While existing synthetic document generators attempt to address data scarcity, they either rely on manually designed layouts and templates, or adopt rule-based approaches that limit layout diversity. Besides, current layout generation methods focus solely on topological patterns without considering textual content, making them impractical for generating documents with complex associations between the contents and layouts. In this paper, we propose a Relation-rIch visual Document GEnerator (RIDGE) that addresses these limitations through a two-stage approach: (1) Content Generation, which leverages LLMs to generate document content using a carefully designed Hierarchical Structure Text format which captures entity categories and relationships, and (2) Content-driven Layout Generation, which learns to create diverse, plausible document layouts solely from easily available Optical Character Recognition (OCR) results, requiring no human labeling or annotations efforts. Experimental results have demonstrated that our method significantly enhances the performance of document understanding models on various VIE benchmarks. The code and model will be available at https://github.com/AI-Application-and-Integration-Lab/RIDGE .
Open-Vocabulary Panoptic Segmentation Using BERT Pre-Training of Vision-Language Multiway Transformer Model
Dec 25, 2024Open-vocabulary panoptic segmentation remains a challenging problem. One of the biggest difficulties lies in training models to generalize to an unlimited number of classes using limited categorized training data. Recent popular methods involve large-scale vision-language pre-trained foundation models, such as CLIP. In this paper, we propose OMTSeg for open-vocabulary segmentation using another large-scale vision-language pre-trained model called BEiT-3 and leveraging the cross-modal attention between visual and linguistic features in BEiT-3 to achieve better performance. Experiments result demonstrates that OMTSeg performs favorably against state-of-the-art models.
ACCEPT: Adaptive Codebook for Composite and Efficient Prompt Tuning
Oct 10, 2024



Prompt Tuning has been a popular Parameter-Efficient Fine-Tuning method attributed to its remarkable performance with few updated parameters on various large-scale pretrained Language Models (PLMs). Traditionally, each prompt has been considered indivisible and updated independently, leading the parameters increase proportionally as prompt length grows. To address this issue, we propose Adaptive Codebook for Composite and Efficient Prompt Tuning (ACCEPT). In our method, we refer to the concept of product quantization (PQ), allowing all soft prompts to share a set of learnable codebook vectors in each subspace, with each prompt differentiated by a set of adaptive weights. We achieve the superior performance on 17 diverse natural language tasks including natural language understanding (NLU) and question answering (QA) tasks by tuning only 0.3% of parameters of the PLMs. Our approach also excels in few-shot and large model settings, highlighting its significant potential.
Information-Theoretical Principled Trade-off between Jailbreakability and Stealthiness on Vision Language Models
Oct 02, 2024



In recent years, Vision-Language Models (VLMs) have demonstrated significant advancements in artificial intelligence, transforming tasks across various domains. Despite their capabilities, these models are susceptible to jailbreak attacks, which can compromise their safety and reliability. This paper explores the trade-off between jailbreakability and stealthiness in VLMs, presenting a novel algorithm to detect non-stealthy jailbreak attacks and enhance model robustness. We introduce a stealthiness-aware jailbreak attack using diffusion models, highlighting the challenge of detecting AI-generated content. Our approach leverages Fano's inequality to elucidate the relationship between attack success rates and stealthiness scores, providing an explainable framework for evaluating these threats. Our contributions aim to fortify AI systems against sophisticated attacks, ensuring their outputs remain aligned with ethical standards and user expectations.
Defending Against Repetitive-based Backdoor Attacks on Semi-supervised Learning through Lens of Rate-Distortion-Perception Trade-off
Jul 14, 2024Semi-supervised learning (SSL) has achieved remarkable performance with a small fraction of labeled data by leveraging vast amounts of unlabeled data from the Internet. However, this large pool of untrusted data is extremely vulnerable to data poisoning, leading to potential backdoor attacks. Current backdoor defenses are not yet effective against such a vulnerability in SSL. In this study, we propose a novel method, Unlabeled Data Purification (UPure), to disrupt the association between trigger patterns and target classes by introducing perturbations in the frequency domain. By leveraging the Rate- Distortion-Perception (RDP) trade-off, we further identify the frequency band, where the perturbations are added, and justify this selection. Notably, UPure purifies poisoned unlabeled data without the need of extra clean labeled data. Extensive experiments on four benchmark datasets and five SSL algorithms demonstrate that UPure effectively reduces the attack success rate from 99.78% to 0% while maintaining model accuracy
RDPN6D: Residual-based Dense Point-wise Network for 6Dof Object Pose Estimation Based on RGB-D Images
May 14, 2024

In this work, we introduce a novel method for calculating the 6DoF pose of an object using a single RGB-D image. Unlike existing methods that either directly predict objects' poses or rely on sparse keypoints for pose recovery, our approach addresses this challenging task using dense correspondence, i.e., we regress the object coordinates for each visible pixel. Our method leverages existing object detection methods. We incorporate a re-projection mechanism to adjust the camera's intrinsic matrix to accommodate cropping in RGB-D images. Moreover, we transform the 3D object coordinates into a residual representation, which can effectively reduce the output space and yield superior performance. We conducted extensive experiments to validate the efficacy of our approach for 6D pose estimation. Our approach outperforms most previous methods, especially in occlusion scenarios, and demonstrates notable improvements over the state-of-the-art methods. Our code is available on https://github.com/AI-Application-and-Integration-Lab/RDPN6D.
LC4SV: A Denoising Framework Learning to Compensate for Unseen Speaker Verification Models
Nov 28, 2023The performance of speaker verification (SV) models may drop dramatically in noisy environments. A speech enhancement (SE) module can be used as a front-end strategy. However, existing SE methods may fail to bring performance improvements to downstream SV systems due to artifacts in the predicted signals of SE models. To compensate for artifacts, we propose a generic denoising framework named LC4SV, which can serve as a pre-processor for various unknown downstream SV models. In LC4SV, we employ a learning-based interpolation agent to automatically generate the appropriate coefficients between the enhanced signal and its noisy input to improve SV performance in noisy environments. Our experimental results demonstrate that LC4SV consistently improves the performance of various unseen SV systems. To the best of our knowledge, this work is the first attempt to develop a learning-based interpolation scheme aiming at improving SV performance in noisy environments.
D4AM: A General Denoising Framework for Downstream Acoustic Models
Nov 28, 2023The performance of acoustic models degrades notably in noisy environments. Speech enhancement (SE) can be used as a front-end strategy to aid automatic speech recognition (ASR) systems. However, existing training objectives of SE methods are not fully effective at integrating speech-text and noisy-clean paired data for training toward unseen ASR systems. In this study, we propose a general denoising framework, D4AM, for various downstream acoustic models. Our framework fine-tunes the SE model with the backward gradient according to a specific acoustic model and the corresponding classification objective. In addition, our method aims to consider the regression objective as an auxiliary loss to make the SE model generalize to other unseen acoustic models. To jointly train an SE unit with regression and classification objectives, D4AM uses an adjustment scheme to directly estimate suitable weighting coefficients rather than undergoing a grid search process with additional training costs. The adjustment scheme consists of two parts: gradient calibration and regression objective weighting. The experimental results show that D4AM can consistently and effectively provide improvements to various unseen acoustic models and outperforms other combination setups. Specifically, when evaluated on the Google ASR API with real noisy data completely unseen during SE training, D4AM achieves a relative WER reduction of 24.65% compared with the direct feeding of noisy input. To our knowledge, this is the first work that deploys an effective combination scheme of regression (denoising) and classification (ASR) objectives to derive a general pre-processor applicable to various unseen ASR systems. Our code is available at https://github.com/ChangLee0903/D4AM.
Domain-Generalized Face Anti-Spoofing with Unknown Attacks
Oct 18, 2023Although face anti-spoofing (FAS) methods have achieved remarkable performance on specific domains or attack types, few studies have focused on the simultaneous presence of domain changes and unknown attacks, which is closer to real application scenarios. To handle domain-generalized unknown attacks, we introduce a new method, DGUA-FAS, which consists of a Transformer-based feature extractor and a synthetic unknown attack sample generator (SUASG). The SUASG network simulates unknown attack samples to assist the training of the feature extractor. Experimental results show that our method achieves superior performance on domain generalization FAS with known or unknown attacks.
Globally Consistent Video Depth and Pose Estimation with Efficient Test-Time Training
Aug 04, 2022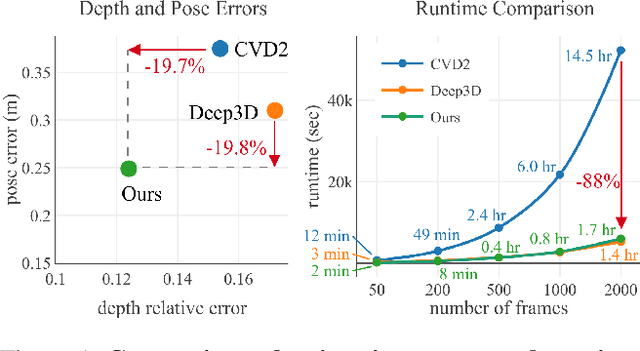
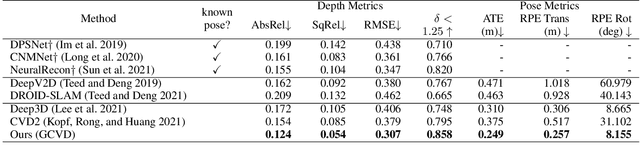

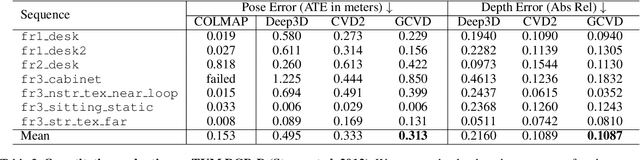
Dense depth and pose estimation is a vital prerequisite for various video applications. Traditional solutions suffer from the robustness of sparse feature tracking and insufficient camera baselines in videos. Therefore, recent methods utilize learning-based optical flow and depth prior to estimate dense depth. However, previous works require heavy computation time or yield sub-optimal depth results. We present GCVD, a globally consistent method for learning-based video structure from motion (SfM) in this paper. GCVD integrates a compact pose graph into the CNN-based optimization to achieve globally consistent estimation from an effective keyframe selection mechanism. It can improve the robustness of learning-based methods with flow-guided keyframes and well-established depth prior. Experimental results show that GCVD outperforms the state-of-the-art methods on both depth and pose estimation. Besides, the runtime experiments reveal that it provides strong efficiency in both short- and long-term videos with global consistency provided.