 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAeroRIT: A New Scene for Hyperspectral Image Analysis
Dec 17, 2019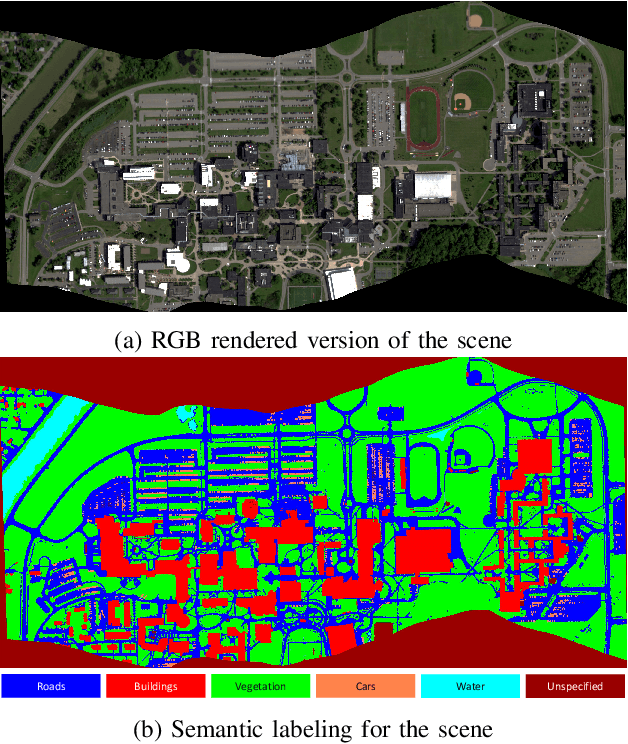
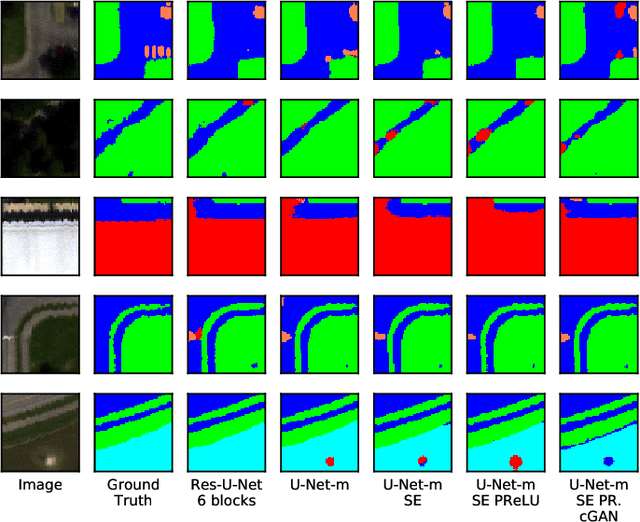
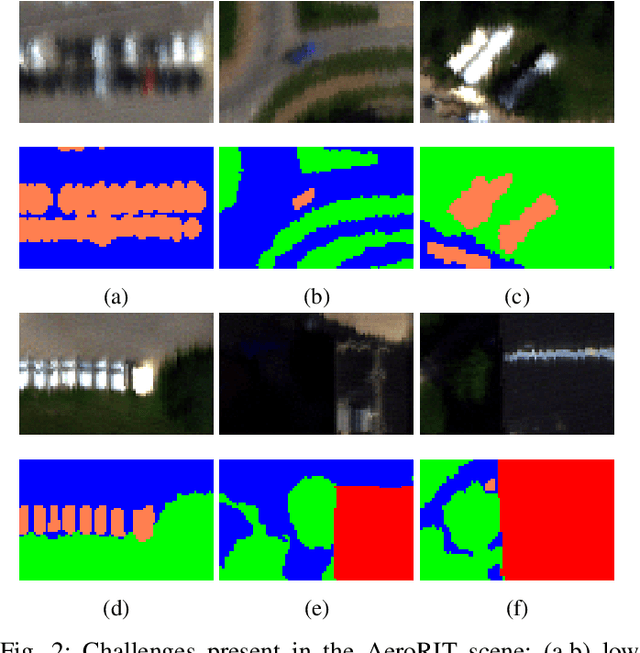

Hyperspectral imagery oriented research like image super-resolution and image fusion is often conducted on open source datasets captured via point and shoot camera setups (ICVL, CAVE) that have high signal to noise ratio. In contrast, spectral images captured from aircrafts have low spatial resolution and suffer from higher noise interference due to factors pertaining to atmospheric conditions. This leads to challenges in extracting contextual information from the captured data as convolutional neural networks are very noise-sensitive and slight atmospheric changes can often lead to a large distribution spread in spectral values overlooking the same object. To understand the challenges faced with aerial spectral data, we collect and label a flight line over the university campus, AeroRIT, and explore the task of semantic segmentation. To the best of our knowledge, this is the first comprehensive large-scale hyperspectral scene with nearly seven million semantic annotations for identifying cars, roads and buildings. We compare the performance of three popular architectures - SegNet, U-Net and Res-U-Net, for scene understanding and object identification. To date, aerial hyperspectral image analysis has been restricted to small datasets with limited train/test splits capabilities. We believe AeroRIT will help advance the research in the field with a more complex object distribution.
Towards calibrated and scalable uncertainty representations for neural networks
Dec 04, 2019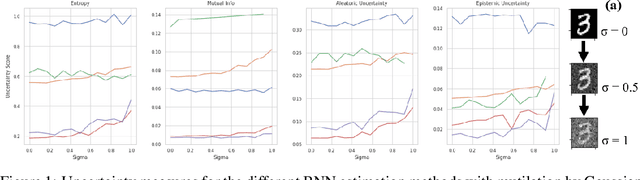
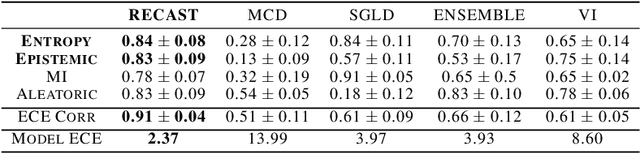
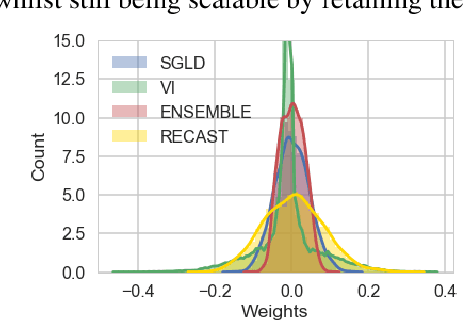
For many applications it is critical to know the uncertainty of a neural network's predictions. While a variety of neural network parameter estimation methods have been proposed for uncertainty estimation, they have not been rigorously compared across uncertainty measures. We assess four of these parameter estimation methods to calibrate uncertainty estimation using four different uncertainty measures: entropy, mutual information, aleatoric uncertainty and epistemic uncertainty. We evaluate the calibration of these parameter estimation methods using expected calibration error. Additionally, we propose a novel method of neural network parameter estimation called RECAST, which combines cosine annealing with warm restarts with Stochastic Gradient Langevin Dynamics, capturing more diverse parameter distributions. When benchmarked against mutilated image data, we show that RECAST is well-calibrated and when combined with predictive entropy and epistemic uncertainty it offers the best calibrated measure of uncertainty when compared to recent methods.
Are Out-of-Distribution Detection Methods Effective on Large-Scale Datasets?
Oct 30, 2019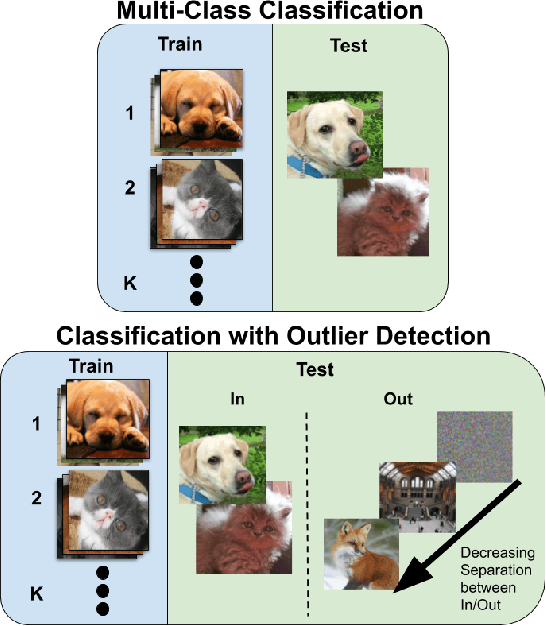

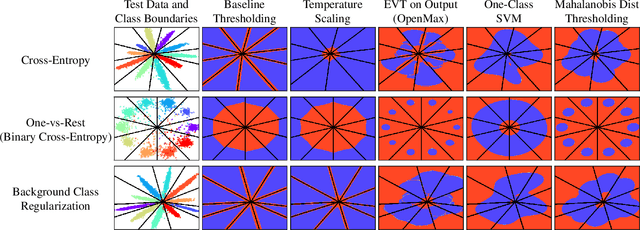
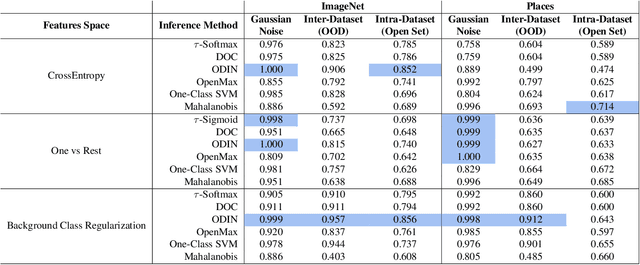
Supervised classification methods often assume the train and test data distributions are the same and that all classes in the test set are present in the training set. However, deployed classifiers often require the ability to recognize inputs from outside the training set as unknowns. This problem has been studied under multiple paradigms including out-of-distribution detection and open set recognition. For convolutional neural networks, there have been two major approaches: 1) inference methods to separate knowns from unknowns and 2) feature space regularization strategies to improve model robustness to outlier inputs. There has been little effort to explore the relationship between the two approaches and directly compare performance on anything other than small-scale datasets that have at most 100 categories. Using ImageNet-1K and Places-434, we identify novel combinations of regularization and specialized inference methods that perform best across multiple outlier detection problems of increasing difficulty level. We found that input perturbation and temperature scaling yield the best performance on large scale datasets regardless of the feature space regularization strategy. Improving the feature space by regularizing against a background class can be helpful if an appropriate background class can be found, but this is impractical for large scale image classification datasets.
REMIND Your Neural Network to Prevent Catastrophic Forgetting
Oct 06, 2019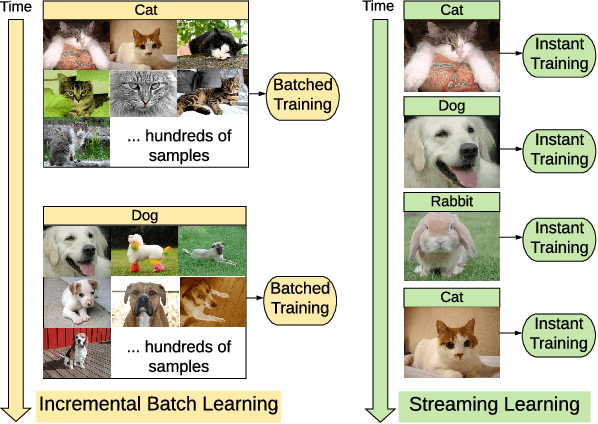
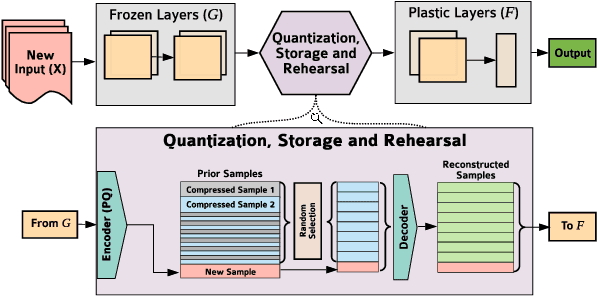
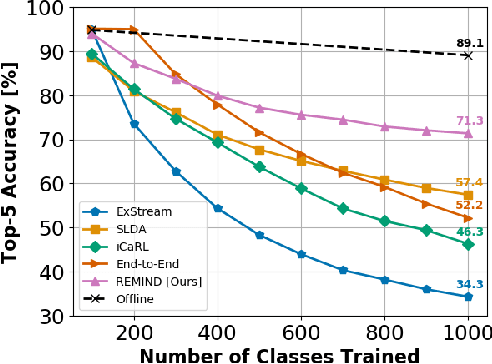
In lifelong machine learning, a robotic agent must be incrementally updated with new knowledge, instead of having distinct train and deployment phases. Conventional neural networks are often used for interpreting sensor data, however, if they are updated on non-stationary data streams, they suffer from catastrophic forgetting, with new learning overwriting past knowledge. A common remedy is replay, which involves mixing old examples with new ones. For incrementally training convolutional neural network models, prior work has enabled replay by storing raw images, but this is memory intensive and not ideal for embedded agents. Here, we propose REMIND, a tensor quantization approach that enables efficient replay with tensors. Unlike other methods, REMIND is trained in a streaming manner, meaning it learns one example at a time rather than in large batches containing multiple classes. Our approach achieves state-of-the-art results for incremental class learning on the ImageNet-1K dataset. We also probe REMIND's robustness to different data ordering schemes using the CORe50 streaming dataset. We demonstrate REMIND's generality by pioneering multi-modal incremental learning for visual question answering (VQA), which cannot be readily done with comparison models. We establish strong baselines on the CLEVR and TDIUC datasets for VQA. The generality of REMIND for multi-modal tasks can enable robotic agents to learn about their visual environment using natural language understanding in an interactive way.
RITnet: Real-time Semantic Segmentation of the Eye for Gaze Tracking
Oct 01, 2019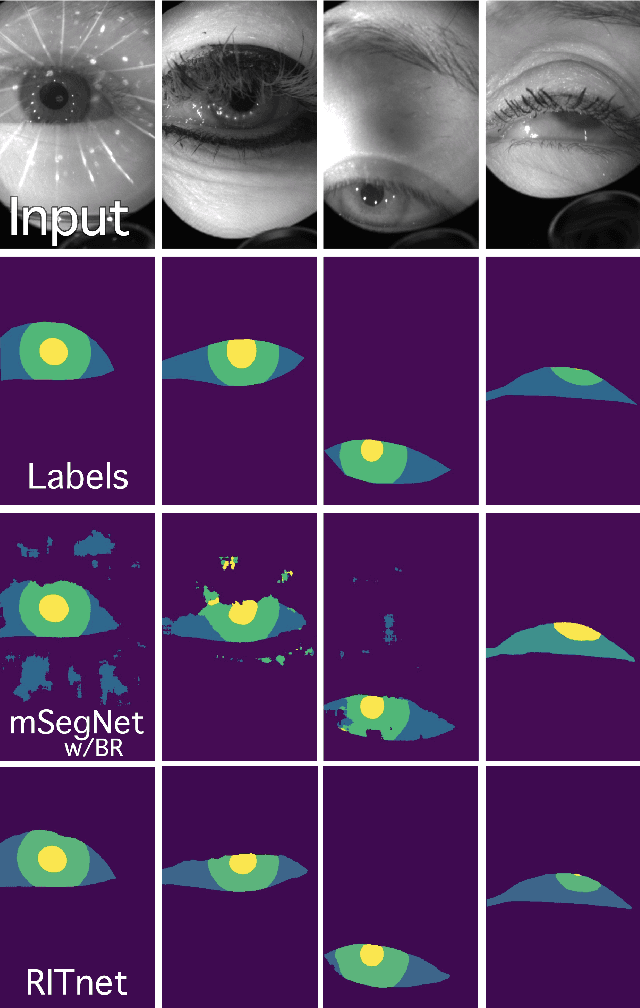
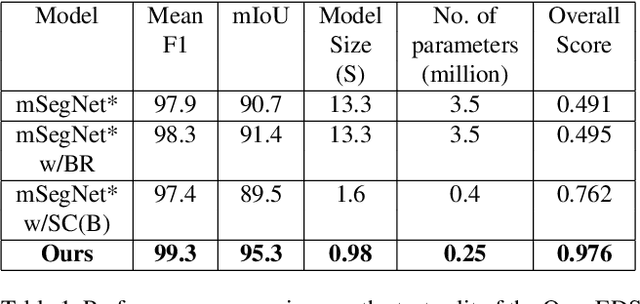
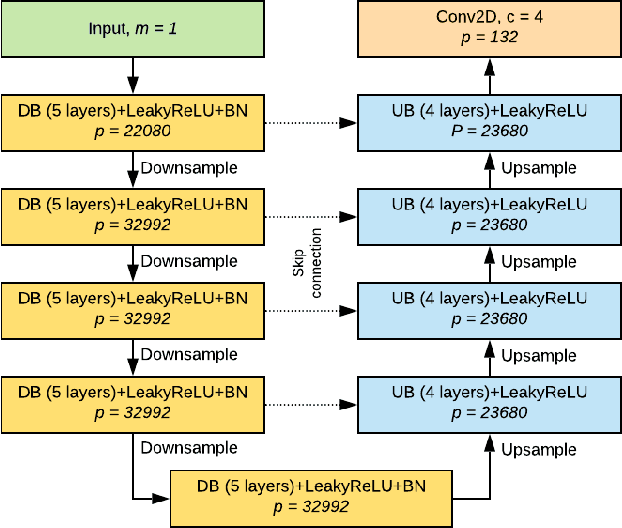
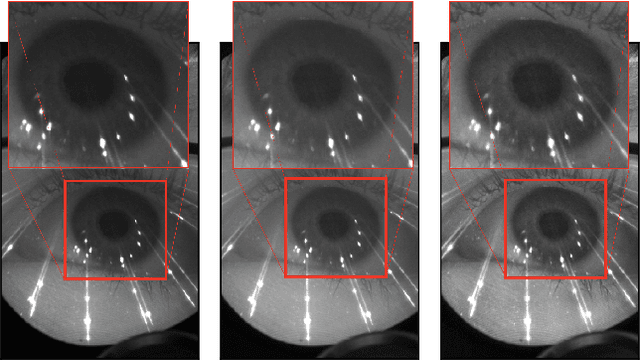
Accurate eye segmentation can improve eye-gaze estimation and support interactive computing based on visual attention; however, existing eye segmentation methods suffer from issues such as person-dependent accuracy, lack of robustness, and an inability to be run in real-time. Here, we present the RITnet model, which is a deep neural network that combines U-Net and DenseNet. RITnet is under 1 MB and achieves 95.3\% accuracy on the 2019 OpenEDS Semantic Segmentation challenge. Using a GeForce GTX 1080 Ti, RITnet tracks at $>$ 300Hz, enabling real-time gaze tracking applications. Pre-trained models and source code are available https://bitbucket.org/eye-ush/ritnet/.
Lifelong Machine Learning with Deep Streaming Linear Discriminant Analysis
Sep 04, 2019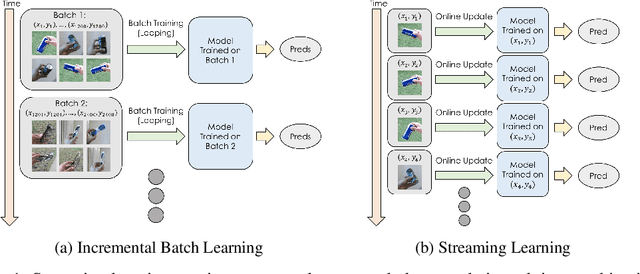
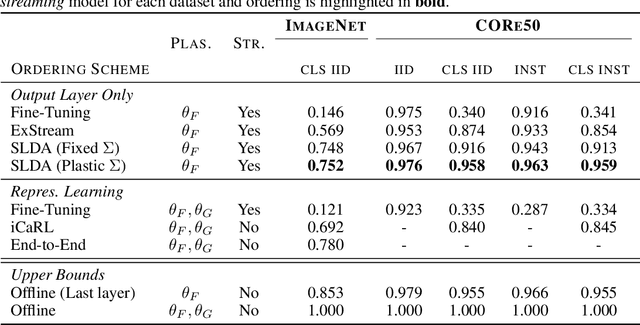
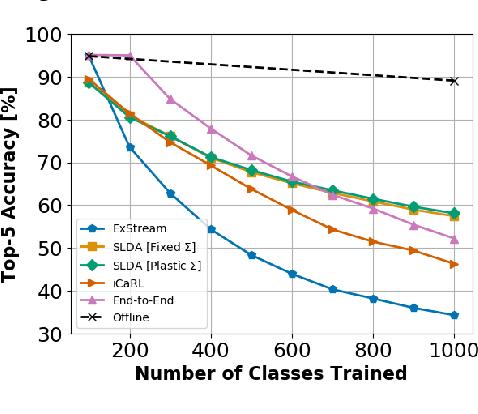
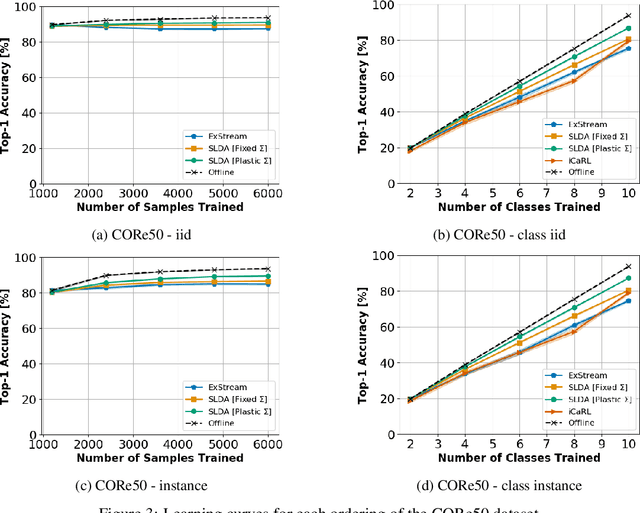
When a robot acquires new information, ideally it would immediately be capable of using that information to understand its environment. While deep neural networks are now widely used by robots for inferring semantic information, conventional neural networks suffer from catastrophic forgetting when they are incrementally updated, with new knowledge overwriting established representations. While a variety of approaches have been developed that attempt to mitigate catastrophic forgetting in the incremental batch learning scenario, in which an agent learns a large collection of labeled samples at once, streaming learning has been much less studied in the robotics and deep learning communities. In streaming learning, an agent learns instances one-by-one and can be tested at any time. Here, we revisit streaming linear discriminant analysis, which has been widely used in the data mining research community. By combining streaming linear discriminant analysis with deep learning, we are able to outperform both incremental batch learning and streaming learning algorithms on both ImageNet-1K and CORe50.
Answering Questions about Data Visualizations using Efficient Bimodal Fusion
Aug 05, 2019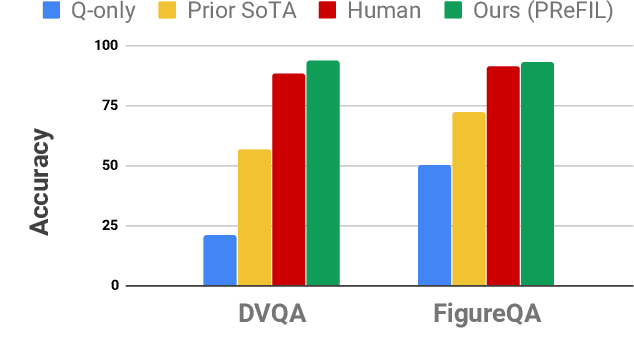

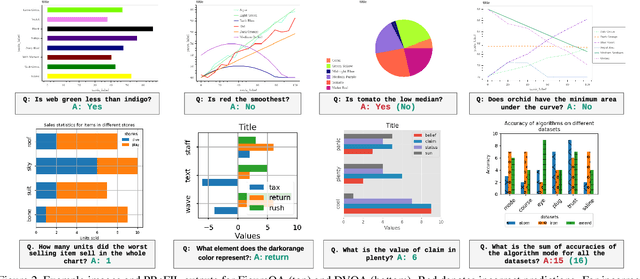
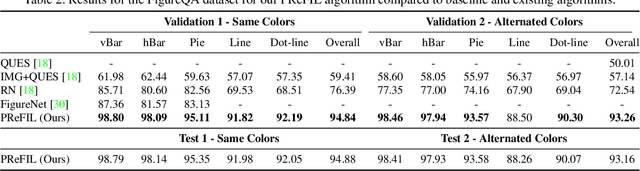
Chart question answering (CQA) is a newly proposed visual question answering (VQA) task where an algorithm must answer questions about data visualizations, e.g. bar charts, pie charts, and line graphs. CQA requires capabilities that natural-image VQA algorithms lack: fine-grained measurements, optical character recognition, and handling out-of-vocabulary words in both questions and answers. Without modifications, state-of-the-art VQA algorithms perform poorly on this task. Here, we propose a novel CQA algorithm called parallel recurrent fusion of image and language (PReFIL). PReFIL first learns bimodal embeddings by fusing question and image features and then intelligently aggregates these learned embeddings to answer the given question. Despite its simplicity, PReFIL greatly surpasses state-of-the art systems and human baselines on both the FigureQA and DVQA datasets. Additionally, we demonstrate that PReFIL can be used to reconstruct tables by asking a series of questions about a chart.
Rethinking Continual Learning for Autonomous Agents and Robots
Jul 02, 2019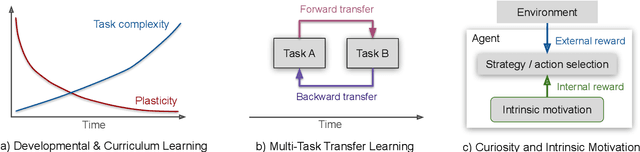
Continual learning refers to the ability of a biological or artificial system to seamlessly learn from continuous streams of information while preventing catastrophic forgetting, i.e., a condition in which new incoming information strongly interferes with previously learned representations. Since it is unrealistic to provide artificial agents with all the necessary prior knowledge to effectively operate in real-world conditions, they must exhibit a rich set of learning capabilities enabling them to interact in complex environments with the aim to process and make sense of continuous streams of (often uncertain) information. While the vast majority of continual learning models are designed to alleviate catastrophic forgetting on simplified classification tasks, here we focus on continual learning for autonomous agents and robots required to operate in much more challenging experimental settings. In particular, we discuss well-established biological learning factors such as developmental and curriculum learning, transfer learning, and intrinsic motivation and their computational counterparts for modeling the progressive acquisition of increasingly complex knowledge and skills in a continual fashion.
Challenges and Prospects in Vision and Language Research
May 24, 2019


Language grounded image understanding tasks have often been proposed as a method for evaluating progress in artificial intelligence. Ideally, these tasks should test a plethora of capabilities that integrate computer vision, reasoning, and natural language understanding. However, rather than behaving as visual Turing tests, recent studies have demonstrated state-of-the-art systems are achieving good performance through flaws in datasets and evaluation procedures. We review the current state of affairs and outline a path forward.
Gaze-in-wild: A dataset for studying eye and head coordination in everyday activities
May 09, 2019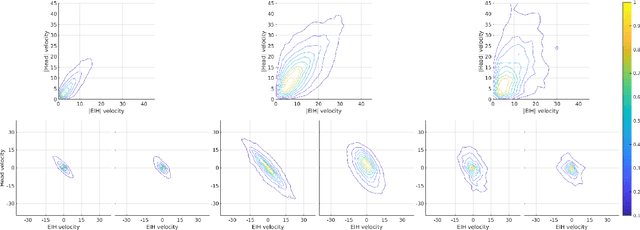
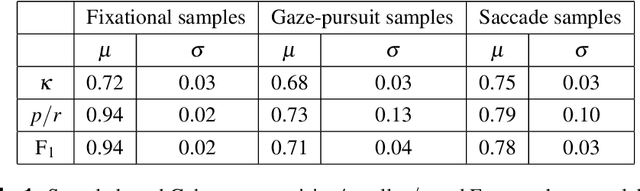
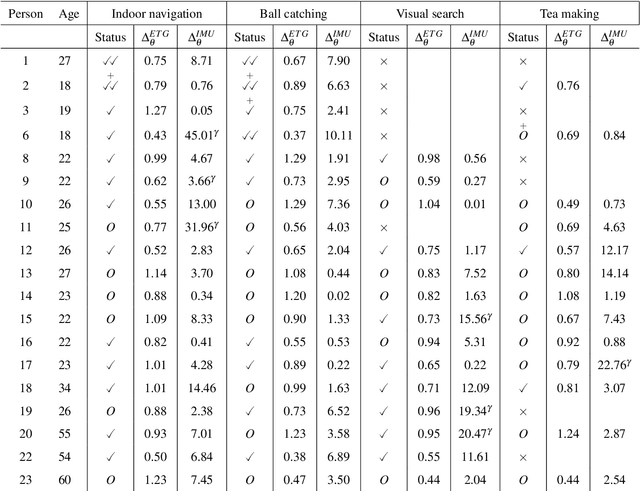
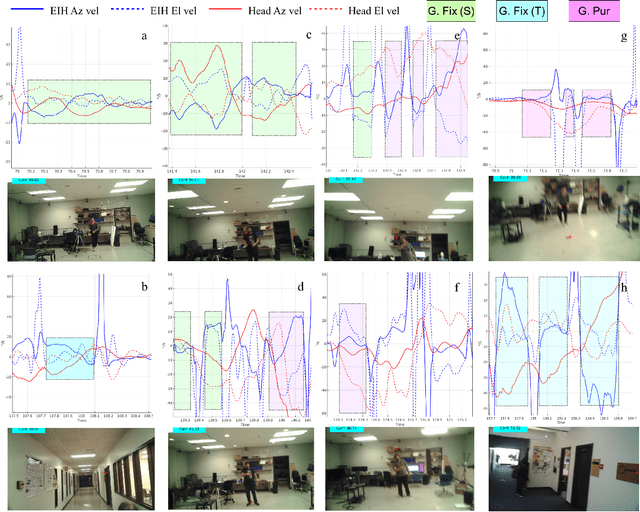
The interaction between the vestibular and ocular system has primarily been studied in controlled environments. Consequently, off-the shelf tools for categorization of gaze events (e.g. fixations, pursuits, saccade) fail when head movements are allowed. Our approach was to collect a novel, naturalistic, and multimodal dataset of eye+head movements when subjects performed everyday tasks while wearing a mobile eye tracker equipped with an inertial measurement unit and a 3D stereo camera. This Gaze-in-the-Wild dataset (GW) includes eye+head rotational velocities (deg/s), infrared eye images and scene imagery (RGB+D). A portion was labelled by coders into gaze motion events with a mutual agreement of 0.72 sample based Cohen's $\kappa$. This labelled data was used to train and evaluate two machine learning algorithms, Random Forest and a Recurrent Neural Network model, for gaze event classification. Assessment involved the application of established and novel event based performance metrics. Classifiers achieve $\sim$90$\%$ human performance in detecting fixations and saccades but fall short (60$\%$) on detecting pursuit movements. Moreover, pursuit classification is far worse in the absence of head movement information. A subsequent analysis of feature significance in our best-performing model revealed a reliance upon absolute eye and head velocity, indicating that classification does not require spatial alignment of the head and eye tracking coordinate systems. The GW dataset, trained classifiers and evaluation metrics will be made publicly available with the intention of facilitating growth in the emerging area of head-free gaze event classification.