 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlendTorch: A Real-Time, Adaptive Domain Randomization Library
Oct 06, 2020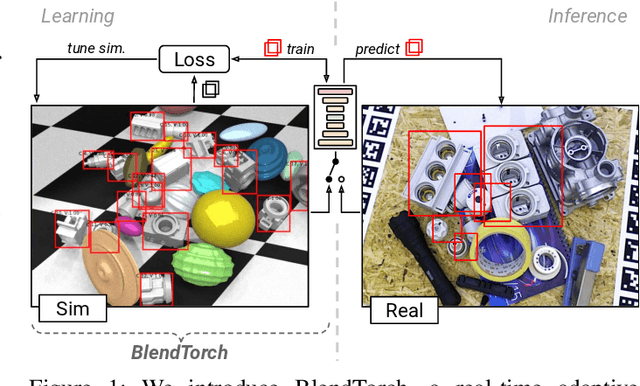
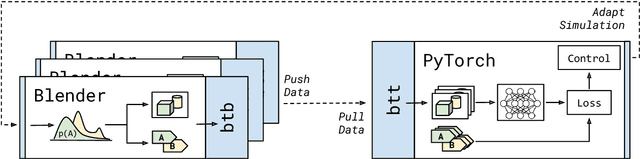

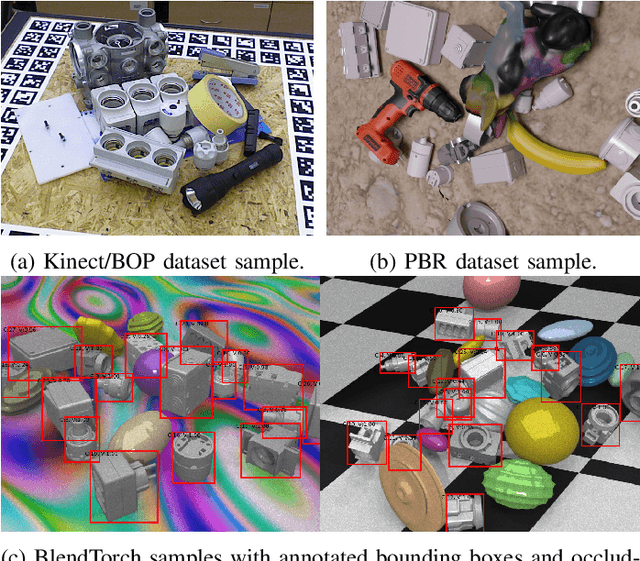
Solving complex computer vision tasks by deep learning techniques relies on large amounts of (supervised) image data, typically unavailable in industrial environments. The lack of training data starts to impede the successful transfer of state-of-the-art methods in computer vision to industrial applications. We introduce BlendTorch, an adaptive Domain Randomization (DR) library, to help creating infinite streams of synthetic training data. BlendTorch generates data by massively randomizing low-fidelity simulations and takes care of distributing artificial training data for model learning in real-time. We show that models trained with BlendTorch repeatedly perform better in an industrial object detection task than those trained on real or photo-realistic datasets.
Graph Neural Networks for Node-Level Predictions
Jun 22, 2020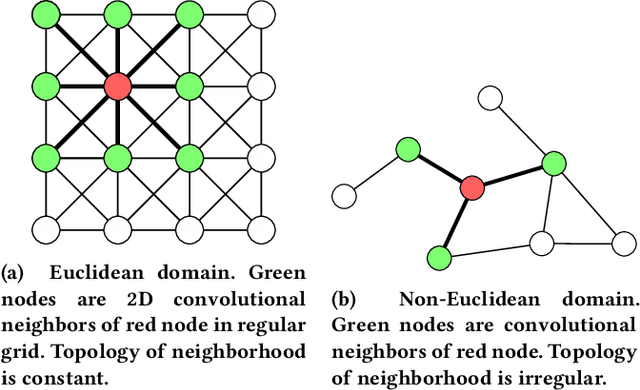

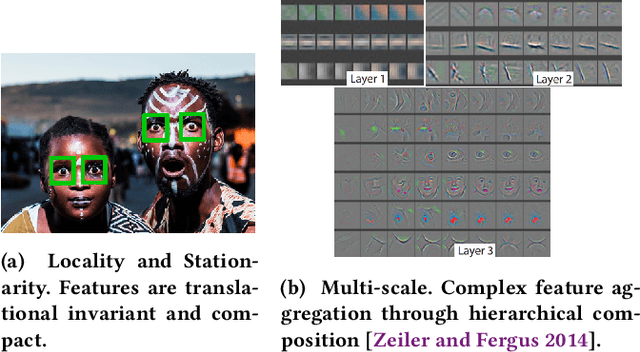
The success of deep learning has revolutionized many fields of research including areas of computer vision, text and speech processing. Enormous research efforts have led to numerous methods that are capable of efficiently analyzing data, especially in the Euclidean space. However, many problems are posed in non-Euclidean domains modeled as general graphs with complex connection patterns. Increased problem complexity and computational power constraints have limited early approaches to static and small-sized graphs. In recent years, a rising interest in machine learning on graph-structured data has been accompanied by improved methods that overcome the limitations of their predecessors. These methods paved the way for dealing with large-scale and time-dynamic graphs. This work aims to provide an overview of early and modern graph neural network based machine learning methods for node-level prediction tasks. Under the umbrella of taxonomies already established in the literature, we explain the core concepts and provide detailed explanations for convolutional methods that have had strong impact. In addition, we introduce common benchmarks and present selected applications from various areas. Finally, we discuss open problems for further research.
Enhanced Human-Machine Interaction by Combining Proximity Sensing with Global Perception
Oct 16, 2019

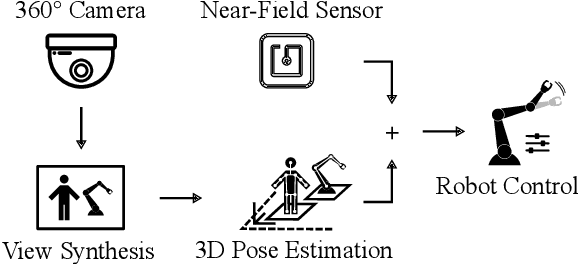
The raise of collaborative robotics has led to wide range of sensor technologies to detect human-machine interactions: at short distances, proximity sensors detect nontactile gestures virtually occlusion-free, while at medium distances, active depth sensors are frequently used to infer human intentions. We describe an optical system for large workspaces to capture human pose based on a single panoramic color camera. Despite the two-dimensional input, our system is able to predict metric 3D pose information over larger field of views than would be possible with active depth measurement cameras. We merge posture context with proximity perception to reduce occlusions and improve accuracy at long distances. We demonstrate the capabilities of our system in two use cases involving multiple humans and robots.
End-to-End Defect Detection in Automated Fiber Placement Based on Artificially Generated Data
Oct 11, 2019Automated fiber placement (AFP) is an advanced manufacturing technology that increases the rate of production of composite materials. At the same time, the need for adaptable and fast inline control methods of such parts raises. Existing inspection systems make use of handcrafted filter chains and feature detectors, tuned for a specific measurement methods by domain experts. These methods hardly scale to new defects or different measurement devices. In this paper, we propose to formulate AFP defect detection as an image segmentation problem that can be solved in an end-to-end fashion using artificially generated training data. We employ a probabilistic graphical model to generate training images and annotations. We then train a deep neural network based on recent architectures designed for image segmentation. This leads to an appealing method that scales well with new defect types and measurement devices and requires little real world data for training.
Metric Pose Estimation for Human-Machine Interaction Using Monocular Vision
Oct 08, 2019
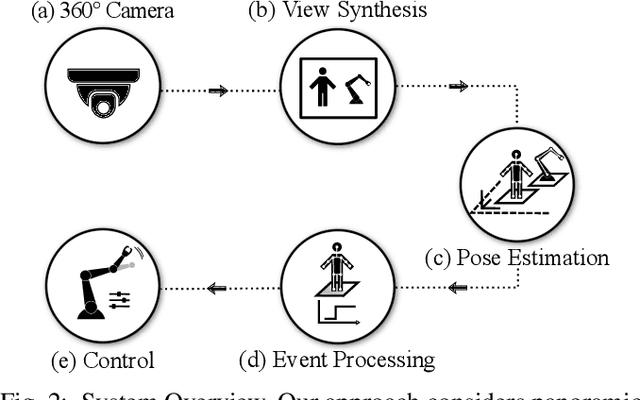
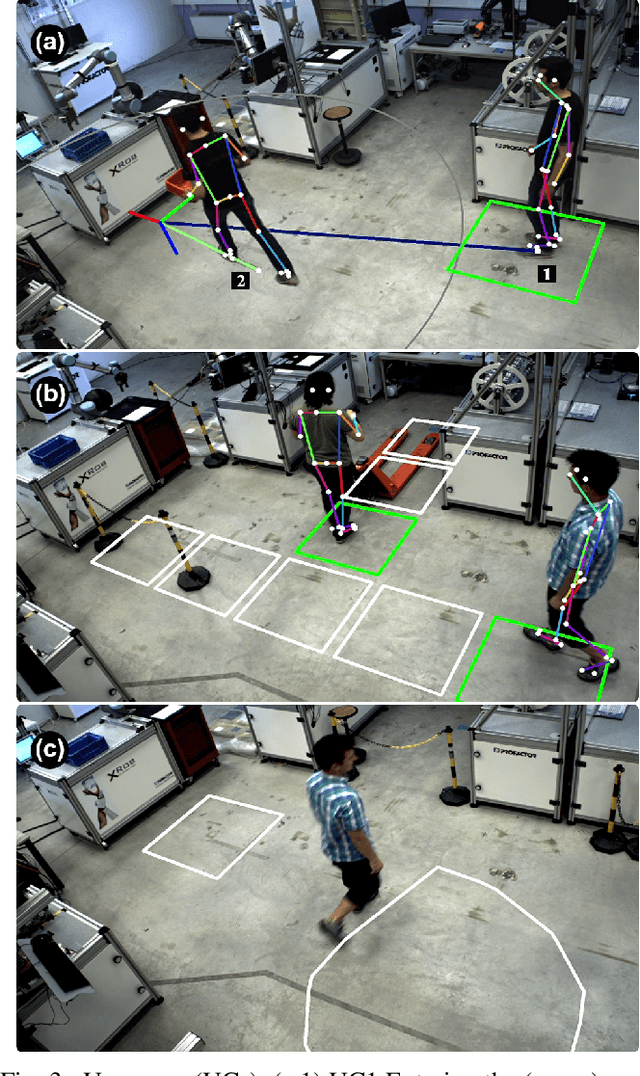
The rapid growth of collaborative robotics in production requires new automation technologies that take human and machine equally into account. In this work, we describe a monocular camera based system to detect human-machine interactions from a bird's-eye perspective. Our system predicts poses of humans and robots from a single wide-angle color image. Even though our approach works on 2D color input, we lift the majority of detections to a metric 3D space. Our system merges pose information with predefined virtual sensors to coordinate human-machine interactions. We demonstrate the advantages of our system in three use cases.
Learning to Predict Robot Keypoints Using Artificially Generated Images
Jul 03, 2019
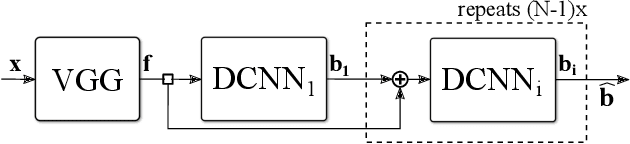
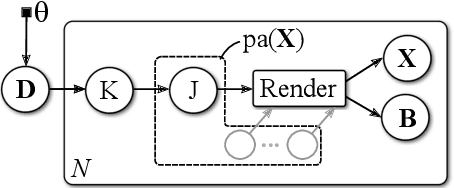
This work considers robot keypoint estimation on color images as a supervised machine learning task. We propose the use of probabilistically created renderings to overcome the lack of labeled real images. Rather than sampling from stationary distributions, our approach introduces a feedback mechanism that constantly adapts probability distributions according to current training progress. Initial results show, our approach achieves near-human-level accuracy on real images. Additionally, we demonstrate that feedback leads to fewer required training steps, while maintaining the same model quality on synthetic data sets.
Spatio-thermal depth correction of RGB-D sensors based on Gaussian Processes in real-time
Jul 01, 2019Commodity RGB-D sensors capture color images along with dense pixel-wise depth information in real-time. Typical RGB-D sensors are provided with a factory calibration and exhibit erratic depth readings due to coarse calibration values, ageing and thermal influence effects. This limits their applicability in computer vision and robotics. We propose a novel method to accurately calibrate depth considering spatial and thermal influences jointly. Our work is based on Gaussian Process Regression in a four dimensional Cartesian and thermal domain. We propose to leverage modern GPUs for dense depth map correction in real-time. For reproducibility we make our dataset and source code publicly available.
Large Area 3D Human Pose Detection Via Stereo Reconstruction in Panoramic Cameras
Jul 01, 2019
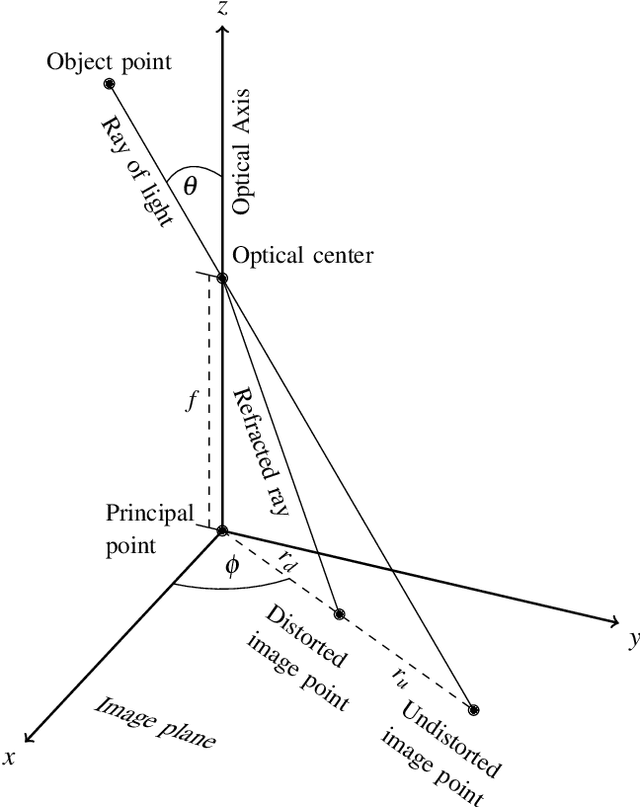
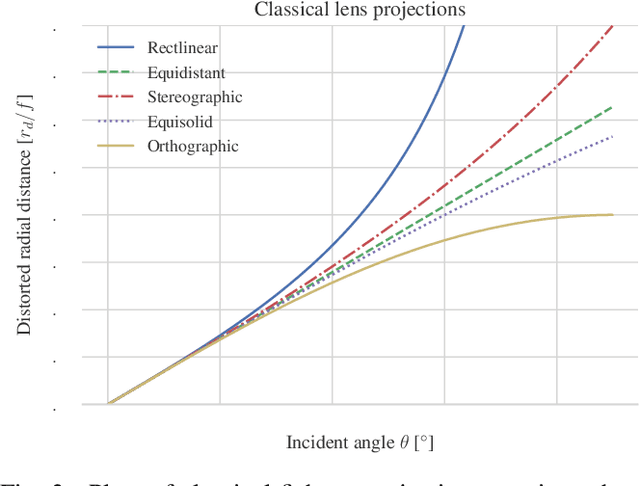

We propose a novel 3D human pose detector using two panoramic cameras. We show that transforming fisheye perspectives to rectilinear views allows a direct application of two-dimensional deep-learning pose estimation methods, without the explicit need for a costly re-training step to compensate for fisheye image distortions. By utilizing panoramic cameras, our method is capable of accurately estimating human poses over a large field of view. This renders our method suitable for ergonomic analyses and other pose based assessments.
3D Robot Pose Estimation from 2D Images
Feb 13, 2019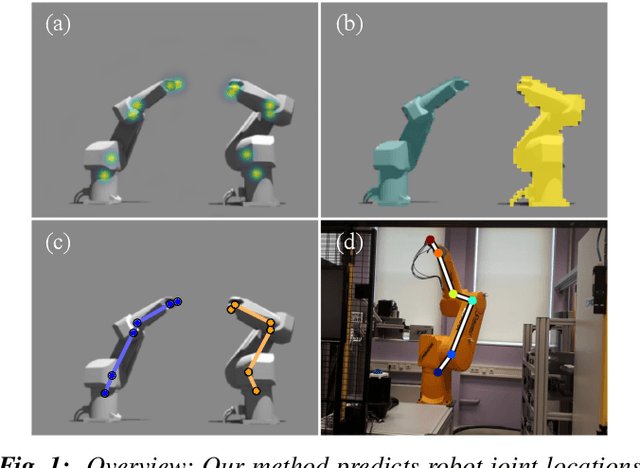

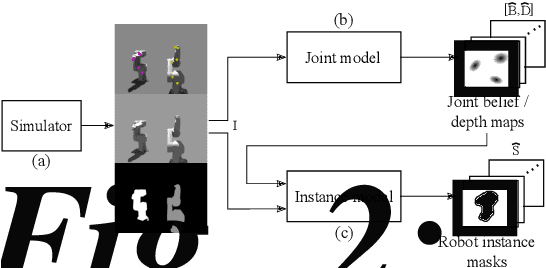
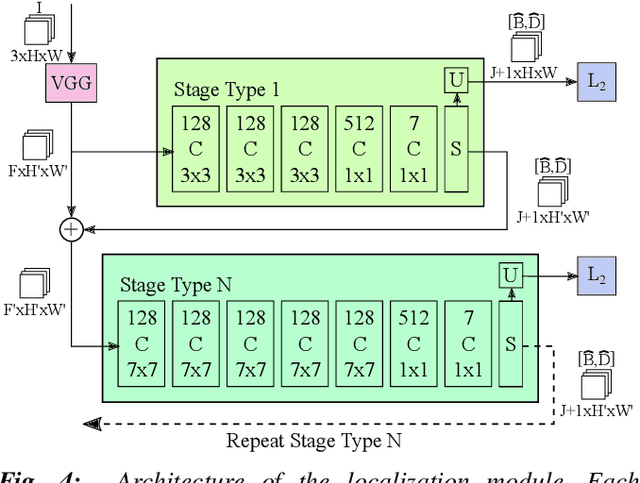
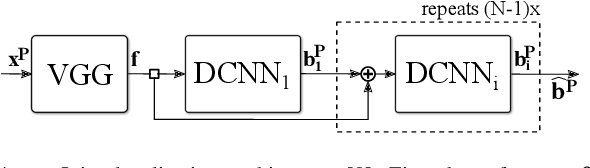
This paper considers the task of locating articulated poses of multiple robots in images. Our approach simultaneously infers the number of robots in a scene, identifies joint locations and estimates sparse depth maps around joint locations. The proposed method applies staged convolutional feature detectors to 2D image inputs and computes robot instance masks using a recurrent network architecture. In addition, regression maps of most likely joint locations in pixel coordinates together with depth information are computed. Compositing 3D robot joint kinematics is accomplished by applying masks to joint readout maps. Our end-to-end formulation is in contrast to previous work in which the composition of robot joints into kinematics is performed in a separate post-processing step. Despite the fact that our models are trained on artificial data, we demonstrate generalizability to real world images.