 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlendTorch: A Real-Time, Adaptive Domain Randomization Library
Oct 06, 2020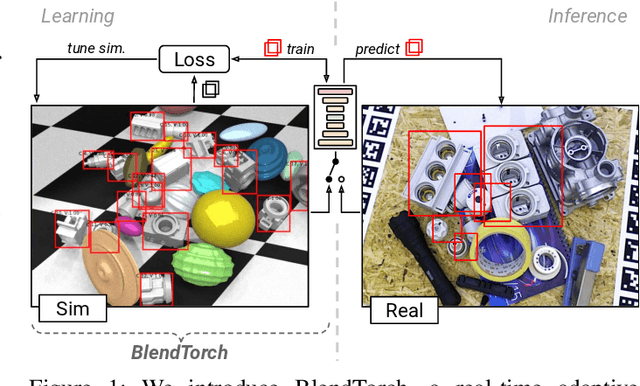
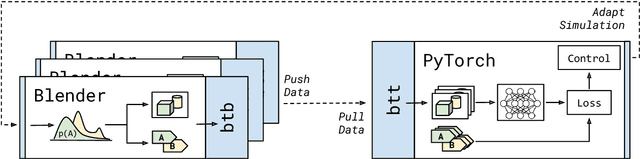

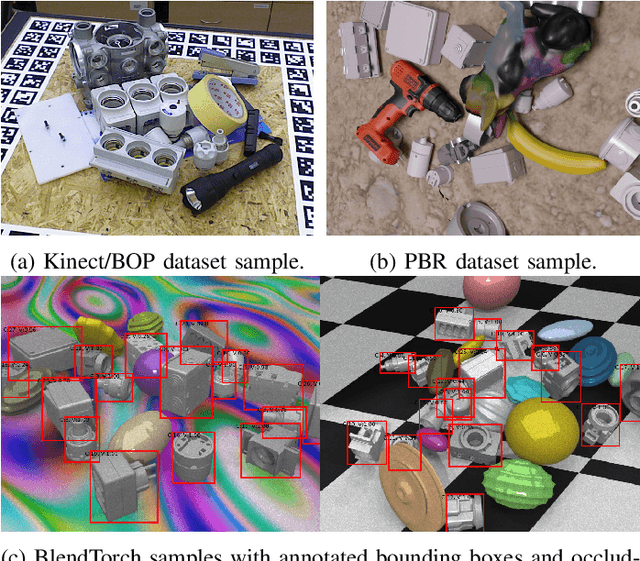
Solving complex computer vision tasks by deep learning techniques relies on large amounts of (supervised) image data, typically unavailable in industrial environments. The lack of training data starts to impede the successful transfer of state-of-the-art methods in computer vision to industrial applications. We introduce BlendTorch, an adaptive Domain Randomization (DR) library, to help creating infinite streams of synthetic training data. BlendTorch generates data by massively randomizing low-fidelity simulations and takes care of distributing artificial training data for model learning in real-time. We show that models trained with BlendTorch repeatedly perform better in an industrial object detection task than those trained on real or photo-realistic datasets.
End-to-End Defect Detection in Automated Fiber Placement Based on Artificially Generated Data
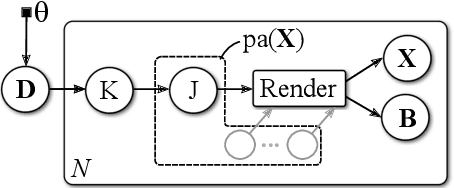
Oct 11, 2019Automated fiber placement (AFP) is an advanced manufacturing technology that increases the rate of production of composite materials. At the same time, the need for adaptable and fast inline control methods of such parts raises. Existing inspection systems make use of handcrafted filter chains and feature detectors, tuned for a specific measurement methods by domain experts. These methods hardly scale to new defects or different measurement devices. In this paper, we propose to formulate AFP defect detection as an image segmentation problem that can be solved in an end-to-end fashion using artificially generated training data. We employ a probabilistic graphical model to generate training images and annotations. We then train a deep neural network based on recent architectures designed for image segmentation. This leads to an appealing method that scales well with new defect types and measurement devices and requires little real world data for training.
Learning to Predict Robot Keypoints Using Artificially Generated Images
Jul 03, 2019
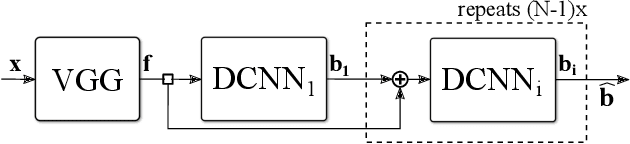
This work considers robot keypoint estimation on color images as a supervised machine learning task. We propose the use of probabilistically created renderings to overcome the lack of labeled real images. Rather than sampling from stationary distributions, our approach introduces a feedback mechanism that constantly adapts probability distributions according to current training progress. Initial results show, our approach achieves near-human-level accuracy on real images. Additionally, we demonstrate that feedback leads to fewer required training steps, while maintaining the same model quality on synthetic data sets.
3D Robot Pose Estimation from 2D Images
Feb 13, 2019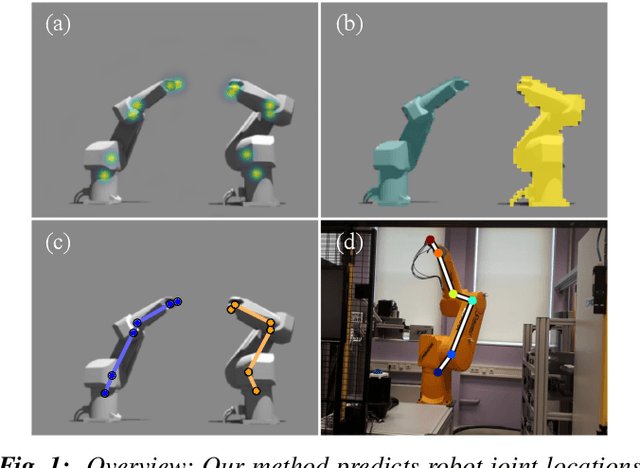

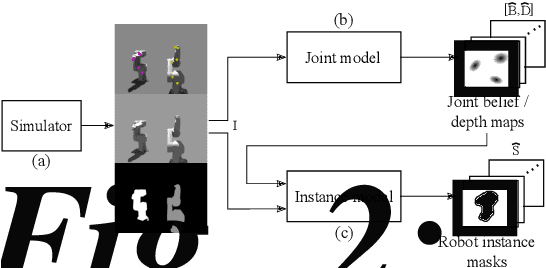
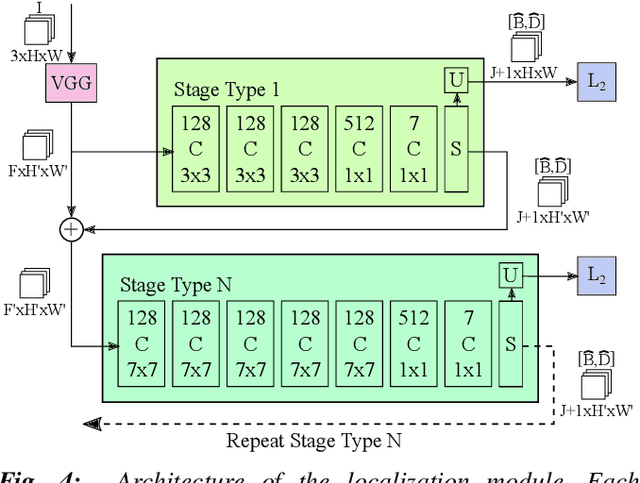
This paper considers the task of locating articulated poses of multiple robots in images. Our approach simultaneously infers the number of robots in a scene, identifies joint locations and estimates sparse depth maps around joint locations. The proposed method applies staged convolutional feature detectors to 2D image inputs and computes robot instance masks using a recurrent network architecture. In addition, regression maps of most likely joint locations in pixel coordinates together with depth information are computed. Compositing 3D robot joint kinematics is accomplished by applying masks to joint readout maps. Our end-to-end formulation is in contrast to previous work in which the composition of robot joints into kinematics is performed in a separate post-processing step. Despite the fact that our models are trained on artificial data, we demonstrate generalizability to real world images.