 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Active Learning with Performance Guarantees
Jun 06, 2021We investigate the problem of active learning in the streaming setting in non-parametric regimes, where the labels are stochastically generated from a class of functions on which we make no assumptions whatsoever. We rely on recently proposed Neural Tangent Kernel (NTK) approximation tools to construct a suitable neural embedding that determines the feature space the algorithm operates on and the learned model computed atop. Since the shape of the label requesting threshold is tightly related to the complexity of the function to be learned, which is a-priori unknown, we also derive a version of the algorithm which is agnostic to any prior knowledge. This algorithm relies on a regret balancing scheme to solve the resulting online model selection problem, and is computationally efficient. We prove joint guarantees on the cumulative regret and number of requested labels which depend on the complexity of the labeling function at hand. In the linear case, these guarantees recover known minimax results of the generalization error as a function of the label complexity in a standard statistical learning setting.
Regret Bound Balancing and Elimination for Model Selection in Bandits and RL
Dec 24, 2020

We propose a simple model selection approach for algorithms in stochastic bandit and reinforcement learning problems. As opposed to prior work that (implicitly) assumes knowledge of the optimal regret, we only require that each base algorithm comes with a candidate regret bound that may or may not hold during all rounds. In each round, our approach plays a base algorithm to keep the candidate regret bounds of all remaining base algorithms balanced, and eliminates algorithms that violate their candidate bound. We prove that the total regret of this approach is bounded by the best valid candidate regret bound times a multiplicative factor. This factor is reasonably small in several applications, including linear bandits and MDPs with nested function classes, linear bandits with unknown misspecification, and LinUCB applied to linear bandits with different confidence parameters. We further show that, under a suitable gap-assumption, this factor only scales with the number of base algorithms and not their complexity when the number of rounds is large enough. Finally, unlike recent efforts in model selection for linear stochastic bandits, our approach is versatile enough to also cover cases where the context information is generated by an adversarial environment, rather than a stochastic one.
Reinforcement Learning with Feedback Graphs
May 07, 2020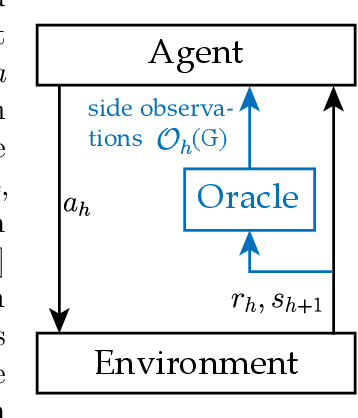


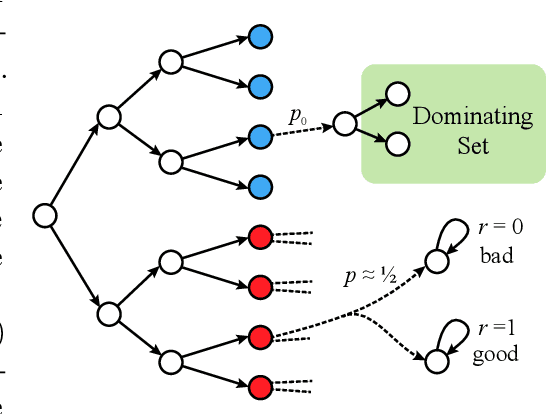
We study episodic reinforcement learning in Markov decision processes when the agent receives additional feedback per step in the form of several transition observations. Such additional observations are available in a range of tasks through extended sensors or prior knowledge about the environment (e.g., when certain actions yield similar outcome). We formalize this setting using a feedback graph over state-action pairs and show that model-based algorithms can leverage the additional feedback for more sample-efficient learning. We give a regret bound that, ignoring logarithmic factors and lower-order terms, depends only on the size of the maximum acyclic subgraph of the feedback graph, in contrast with a polynomial dependency on the number of states and actions in the absence of a feedback graph. Finally, we highlight challenges when leveraging a small dominating set of the feedback graph as compared to the bandit setting and propose a new algorithm that can use knowledge of such a dominating set for more sample-efficient learning of a near-optimal policy.
Being Optimistic to Be Conservative: Quickly Learning a CVaR Policy
Nov 05, 2019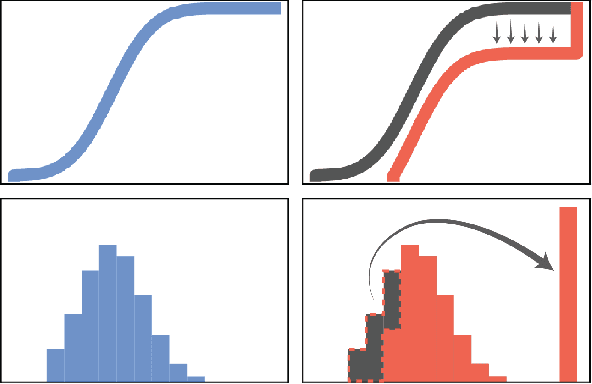
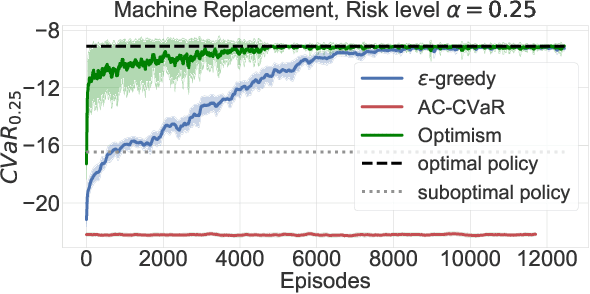
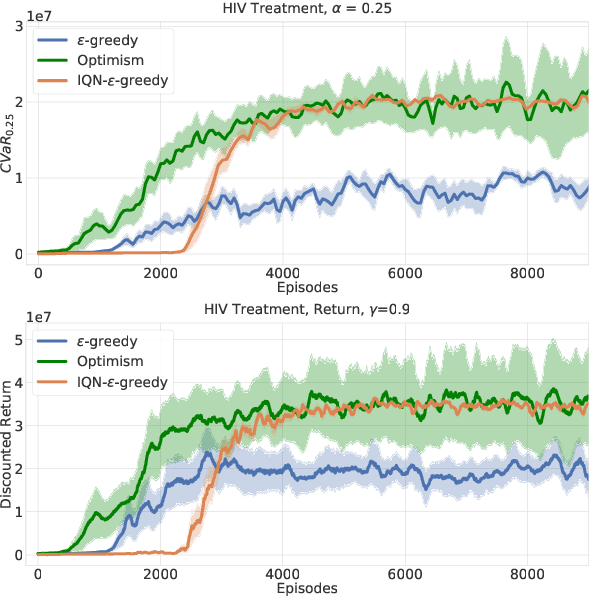
While maximizing expected return is the goal in most reinforcement learning approaches, risk-sensitive objectives such as conditional value at risk (CVaR) are more suitable for many high-stakes applications. However, relatively little is known about how to explore to quickly learn policies with good CVaR. In this paper, we present the first algorithm for sample-efficient learning of CVaR-optimal policies in Markov decision processes based on the optimism in the face of uncertainty principle. This method relies on a novel optimistic version of the distributional Bellman operator that moves probability mass from the lower to the upper tail of the return distribution. We prove asymptotic convergence and optimism of this operator for the tabular policy evaluation case. We further demonstrate that our algorithm finds CVaR-optimal policies substantially faster than existing baselines in several simulated environments with discrete and continuous state spaces.
Policy Certificates: Towards Accountable Reinforcement Learning
Nov 07, 2018
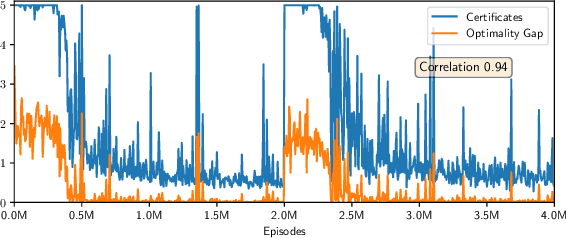
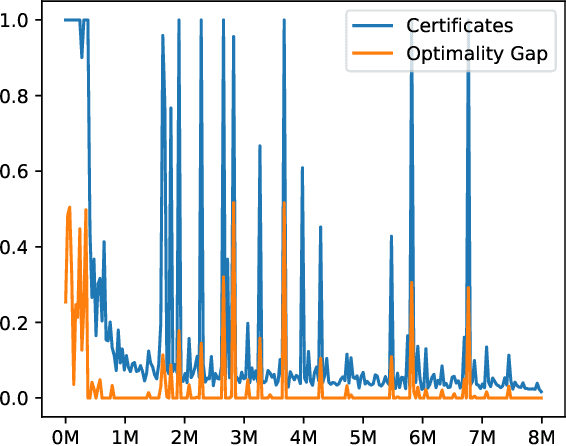
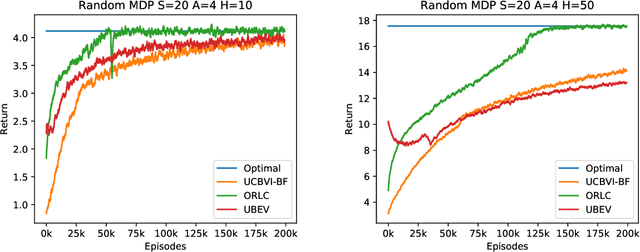
The performance of a reinforcement learning algorithm can vary drastically during learning because of exploration. Existing algorithms provide little information about their current policy's quality before executing it, and thus have limited use in high-stakes applications like healthcare. In this paper, we address such a lack of accountability by proposing that algorithms output policy certificates, which upper bound the suboptimality in the next episode, allowing humans to intervene when the certified quality is not satisfactory. We further present a new learning framework (IPOC) for finite-sample analysis with policy certificates, and develop two IPOC algorithms that enjoy guarantees for the quality of both their policies and certificates.
On Oracle-Efficient PAC RL with Rich Observations
Oct 31, 2018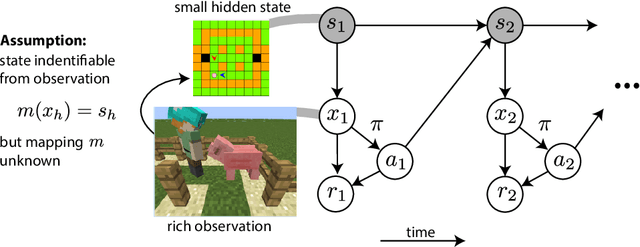
We study the computational tractability of PAC reinforcement learning with rich observations. We present new provably sample-efficient algorithms for environments with deterministic hidden state dynamics and stochastic rich observations. These methods operate in an oracle model of computation -- accessing policy and value function classes exclusively through standard optimization primitives -- and therefore represent computationally efficient alternatives to prior algorithms that require enumeration. With stochastic hidden state dynamics, we prove that the only known sample-efficient algorithm, OLIVE, cannot be implemented in the oracle model. We also present several examples that illustrate fundamental challenges of tractable PAC reinforcement learning in such general settings.
Unifying PAC and Regret: Uniform PAC Bounds for Episodic Reinforcement Learning
Jan 02, 2018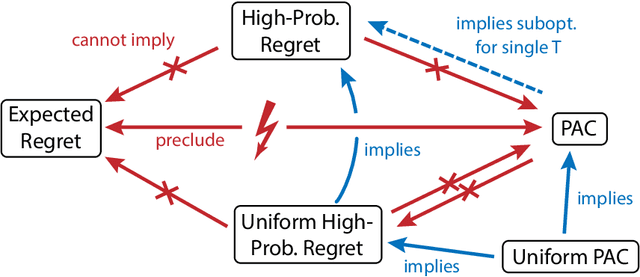
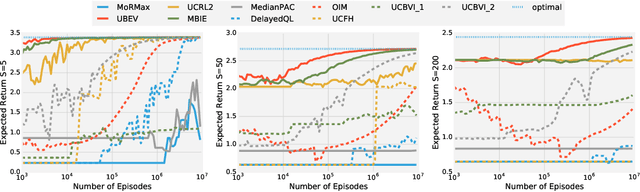
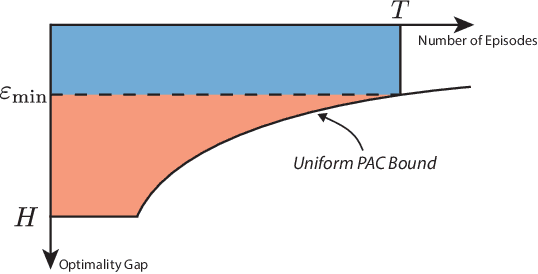
Statistical performance bounds for reinforcement learning (RL) algorithms can be critical for high-stakes applications like healthcare. This paper introduces a new framework for theoretically measuring the performance of such algorithms called Uniform-PAC, which is a strengthening of the classical Probably Approximately Correct (PAC) framework. In contrast to the PAC framework, the uniform version may be used to derive high probability regret guarantees and so forms a bridge between the two setups that has been missing in the literature. We demonstrate the benefits of the new framework for finite-state episodic MDPs with a new algorithm that is Uniform-PAC and simultaneously achieves optimal regret and PAC guarantees except for a factor of the horizon.
Decoupling Learning Rules from Representations
Jun 09, 2017
In the artificial intelligence field, learning often corresponds to changing the parameters of a parameterized function. A learning rule is an algorithm or mathematical expression that specifies precisely how the parameters should be changed. When creating an artificial intelligence system, we must make two decisions: what representation should be used (i.e., what parameterized function should be used) and what learning rule should be used to search through the resulting set of representable functions. Using most learning rules, these two decisions are coupled in a subtle (and often unintentional) way. That is, using the same learning rule with two different representations that can represent the same sets of functions can result in two different outcomes. After arguing that this coupling is undesirable, particularly when using artificial neural networks, we present a method for partially decoupling these two decisions for a broad class of learning rules that span unsupervised learning, reinforcement learning, and supervised learning.
Sample Efficient Policy Search for Optimal Stopping Domains
May 24, 2017
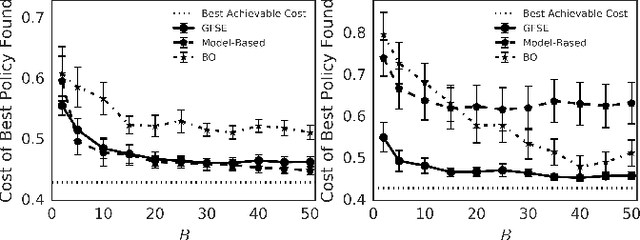
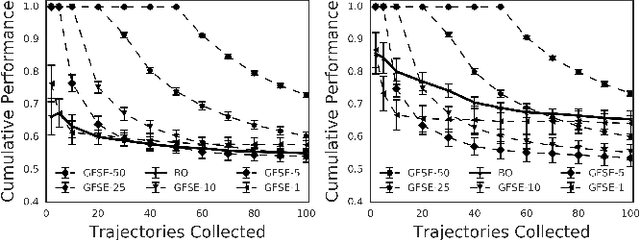
Optimal stopping problems consider the question of deciding when to stop an observation-generating process in order to maximize a return. We examine the problem of simultaneously learning and planning in such domains, when data is collected directly from the environment. We propose GFSE, a simple and flexible model-free policy search method that reuses data for sample efficiency by leveraging problem structure. We bound the sample complexity of our approach to guarantee uniform convergence of policy value estimates, tightening existing PAC bounds to achieve logarithmic dependence on horizon length for our setting. We also examine the benefit of our method against prevalent model-based and model-free approaches on 3 domains taken from diverse fields.
Memory Lens: How Much Memory Does an Agent Use?
Nov 21, 2016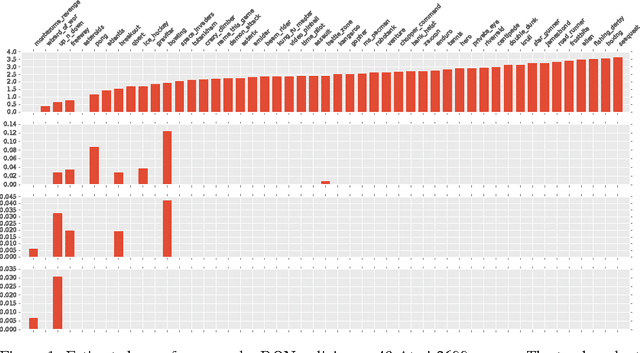
We propose a new method to study the internal memory used by reinforcement learning policies. We estimate the amount of relevant past information by estimating mutual information between behavior histories and the current action of an agent. We perform this estimation in the passive setting, that is, we do not intervene but merely observe the natural behavior of the agent. Moreover, we provide a theoretical justification for our approach by showing that it yields an implementation-independent lower bound on the minimal memory capacity of any agent that implement the observed policy. We demonstrate our approach by estimating the use of memory of DQN policies on concatenated Atari frames, demonstrating sharply different use of memory across 49 games. The study of memory as information that flows from the past to the current action opens avenues to understand and improve successful reinforcement learning algorithms.