 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Teacher-Student approach for extracting informative speaker embeddings from speech mixtures
Jun 01, 2023



We introduce a monaural neural speaker embeddings extractor that computes an embedding for each speaker present in a speech mixture. To allow for supervised training, a teacher-student approach is employed: the teacher computes the target embeddings from each speaker's utterance before the utterances are added to form the mixture, and the student embedding extractor is then tasked to reproduce those embeddings from the speech mixture at its input. The system much more reliably verifies the presence or absence of a given speaker in a mixture than a conventional speaker embedding extractor, and even exhibits comparable performance to a multi-channel approach that exploits spatial information for embedding extraction. Further, it is shown that a speaker embedding computed from a mixture can be used to check for the presence of that speaker in another mixture.
Frame-wise and overlap-robust speaker embeddings for meeting diarization
Jun 01, 2023



Using a Teacher-Student training approach we developed a speaker embedding extraction system that outputs embeddings at frame rate. Given this high temporal resolution and the fact that the student produces sensible speaker embeddings even for segments with speech overlap, the frame-wise embeddings serve as an appropriate representation of the input speech signal for an end-to-end neural meeting diarization (EEND) system. We show in experiments that this representation helps mitigate a well-known problem of EEND systems: when increasing the number of speakers the diarization performance drop is significantly reduced. We also introduce block-wise processing to be able to diarize arbitrarily long meetings.
TS-SEP: Joint Diarization and Separation Conditioned on Estimated Speaker Embeddings
Mar 08, 2023



Since diarization and source separation of meeting data are closely related tasks, we here propose an approach to perform the two objectives jointly. It builds upon the target-speaker voice activity detection (TS-VAD) diarization approach, which assumes that initial speaker embeddings are available. We replace the final combined speaker activity estimation network of TS-VAD with a network that produces speaker activity estimates at a time-frequency resolution. Those act as masks for source extraction, either via masking or via beamforming. The technique can be applied both for single-channel and multi-channel input and, in both cases, achieves a new state-of-the-art word error rate (WER) on the LibriCSS meeting data recognition task. We further compute speaker-aware and speaker-agnostic WERs to isolate the contribution of diarization errors to the overall WER performance.
On Word Error Rate Definitions and their Efficient Computation for Multi-Speaker Speech Recognition Systems
Nov 29, 2022We present a general framework to compute the word error rate (WER) of ASR systems that process recordings containing multiple speakers at their input and that produce multiple output word sequences (MIMO). Such ASR systems are typically required, e.g., for meeting transcription. We provide an efficient implementation based on a dynamic programming search in a multi-dimensional Levenshtein distance tensor under the constraint that a reference utterance must be matched consistently with one hypothesis output. This also results in an efficient implementation of the ORC WER which previously suffered from exponential complexity. We give an overview of commonly used WER definitions for multi-speaker scenarios and show that they are specializations of the above MIMO WER tuned to particular application scenarios. We conclude with a discussion of the pros and cons of the various WER definitions and a recommendation when to use which.
Reverberation as Supervision for Speech Separation
Nov 15, 2022



This paper proposes reverberation as supervision (RAS), a novel unsupervised loss function for single-channel reverberant speech separation. Prior methods for unsupervised separation required the synthesis of mixtures of mixtures or assumed the existence of a teacher model, making them difficult to consider as potential methods explaining the emergence of separation abilities in an animal's auditory system. We assume the availability of two-channel mixtures at training time, and train a neural network to separate the sources given one of the channels as input such that the other channel may be predicted from the separated sources. As the relationship between the room impulse responses (RIRs) of each channel depends on the locations of the sources, which are unknown to the network, the network cannot rely on learning that relationship. Instead, our proposed loss function fits each of the separated sources to the mixture in the target channel via Wiener filtering, and compares the resulting mixture to the ground-truth one. We show that minimizing the scale-invariant signal-to-distortion ratio (SI-SDR) of the predicted right-channel mixture with respect to the ground truth implicitly guides the network towards separating the left-channel sources. On a semi-supervised reverberant speech separation task based on the WHAMR! dataset, using training data where just 5% (resp., 10%) of the mixtures are labeled with associated isolated sources, we achieve 70% (resp., 78%) of the SI-SDR improvement obtained when training with supervision on the full training set, while a model trained only on the labeled data obtains 43% (resp., 45%).
MMS-MSG: A Multi-purpose Multi-Speaker Mixture Signal Generator
Sep 23, 2022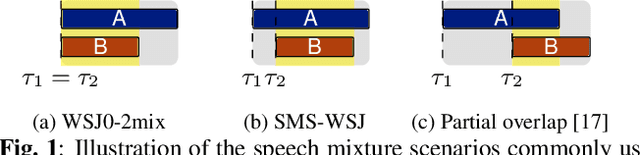
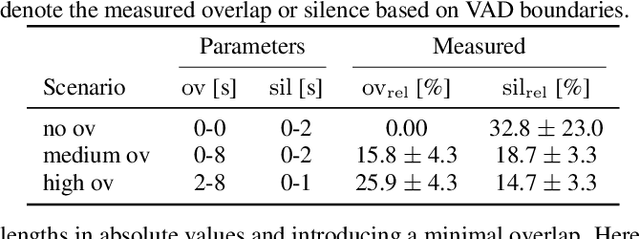
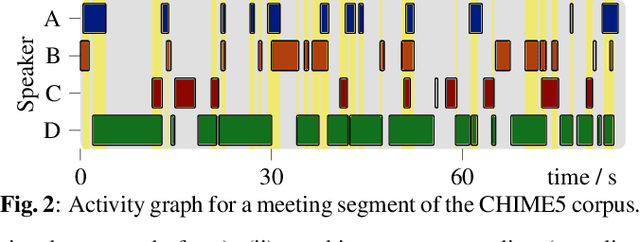
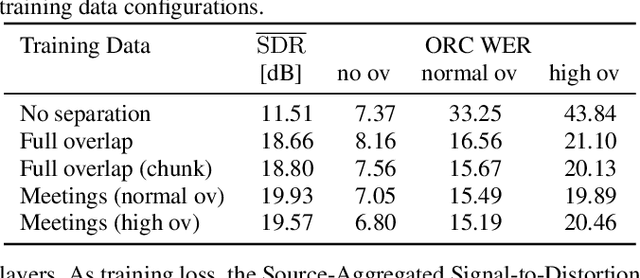
The scope of speech enhancement has changed from a monolithic view of single, independent tasks, to a joint processing of complex conversational speech recordings. Training and evaluation of these single tasks requires synthetic data with access to intermediate signals that is as close as possible to the evaluation scenario. As such data often is not available, many works instead use specialized databases for the training of each system component, e.g WSJ0-mix for source separation. We present a Multi-purpose Multi-Speaker Mixture Signal Generator (MMS-MSG) for generating a variety of speech mixture signals based on any speech corpus, ranging from classical anechoic mixtures (e.g., WSJ0-mix) over reverberant mixtures (e.g., SMS-WSJ) to meeting-style data. Its highly modular and flexible structure allows for the simulation of diverse environments and dynamic mixing, while simultaneously enabling an easy extension and modification to generate new scenarios and mixture types. These meetings can be used for prototyping, evaluation, or training purposes. We provide example evaluation data and baseline results for meetings based on the WSJ corpus. Further, we demonstrate the usefulness for realistic scenarios by using MMS-MSG to provide training data for the LibriCSS database.
Utterance-by-utterance overlap-aware neural diarization with Graph-PIT
Jul 28, 2022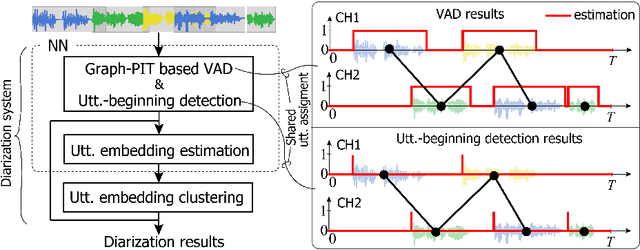
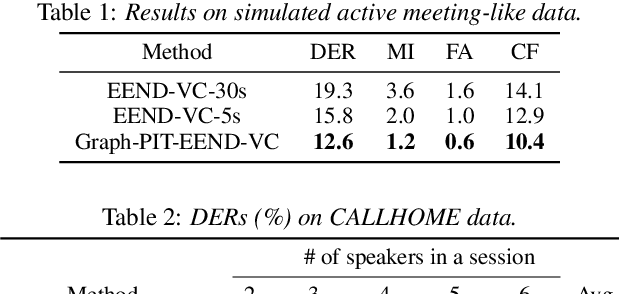
Recent speaker diarization studies showed that integration of end-to-end neural diarization (EEND) and clustering-based diarization is a promising approach for achieving state-of-the-art performance on various tasks. Such an approach first divides an observed signal into fixed-length segments, then performs {\it segment-level} local diarization based on an EEND module, and merges the segment-level results via clustering to form a final global diarization result. The segmentation is done to limit the number of speakers in each segment since the current EEND cannot handle a large number of speakers. In this paper, we argue that such an approach involving the segmentation has several issues; for example, it inevitably faces a dilemma that larger segment sizes increase both the context available for enhancing the performance and the number of speakers for the local EEND module to handle. To resolve such a problem, this paper proposes a novel framework that performs diarization without segmentation. However, it can still handle challenging data containing many speakers and a significant amount of overlapping speech. The proposed method can take an entire meeting for inference and perform {\it utterance-by-utterance} diarization that clusters utterance activities in terms of speakers. To this end, we leverage a neural network training scheme called Graph-PIT proposed recently for neural source separation. Experiments with simulated active-meeting-like data and CALLHOME data show the superiority of the proposed approach over the conventional methods.
A Meeting Transcription System for an Ad-Hoc Acoustic Sensor Network
May 02, 2022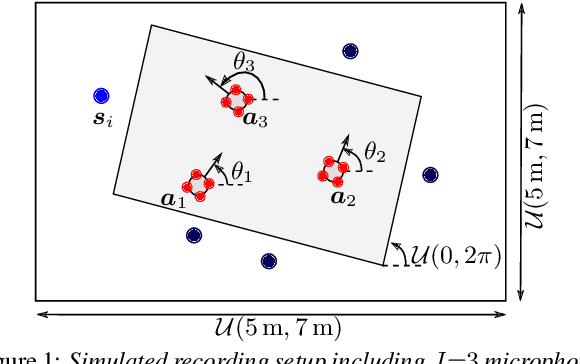
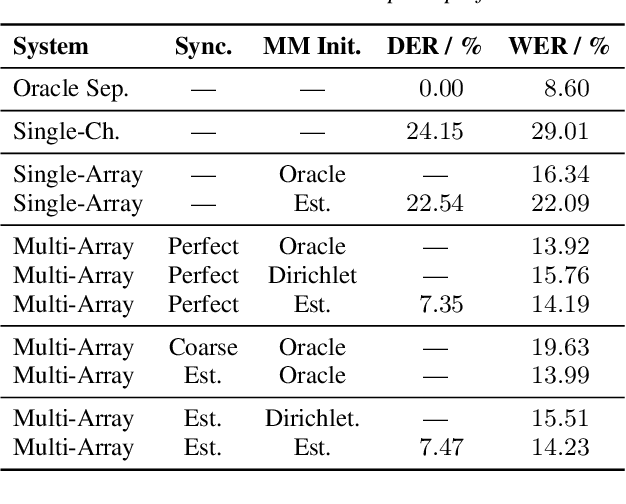
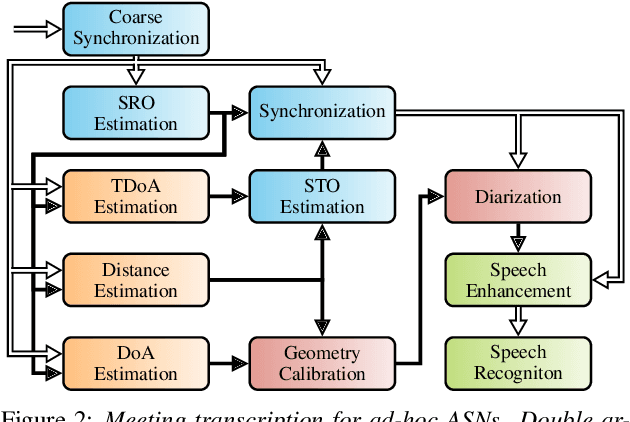
We propose a system that transcribes the conversation of a typical meeting scenario that is captured by a set of initially unsynchronized microphone arrays at unknown positions. It consists of subsystems for signal synchronization, including both sampling rate and sampling time offset estimation, diarization based on speaker and microphone array position estimation, multi-channel speech enhancement, and automatic speech recognition. With the estimated diarization information, a spatial mixture model is initialized that is used to estimate beamformer coefficients for source separation. Simulations show that the speech recognition accuracy can be improved by synchronizing and combining multiple distributed microphone arrays compared to a single compact microphone array. Furthermore, the proposed informed initialization of the spatial mixture model delivers a clear performance advantage over random initialization.
An Initialization Scheme for Meeting Separation with Spatial Mixture Models
Apr 04, 2022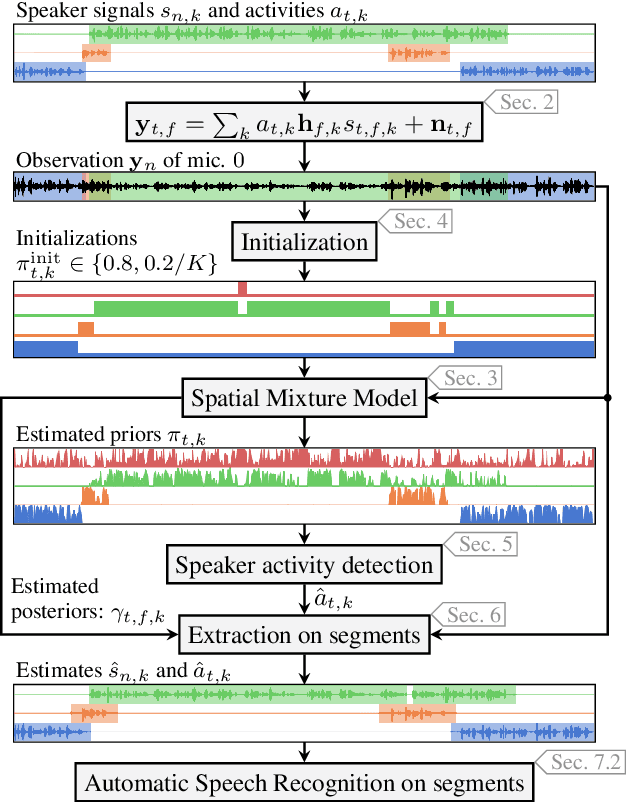
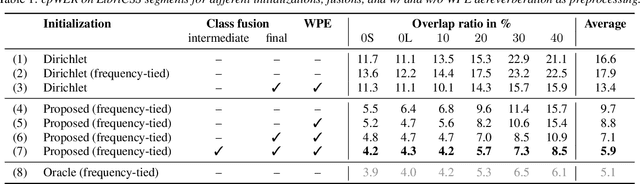
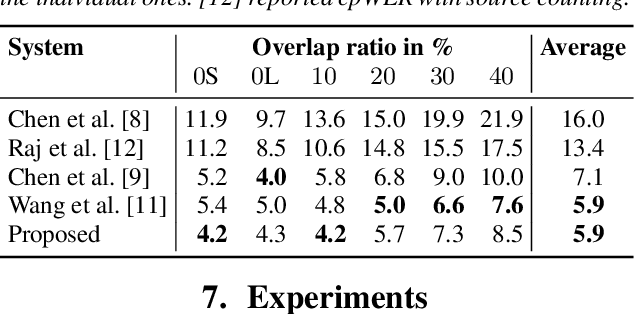
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.
Monaural source separation: From anechoic to reverberant environments
Nov 15, 2021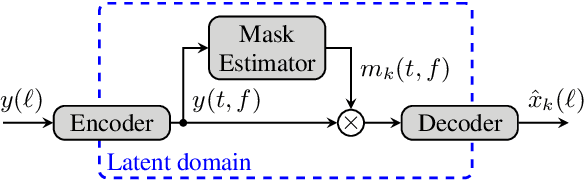
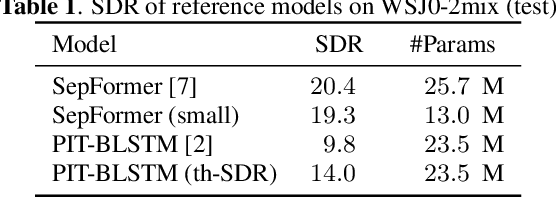
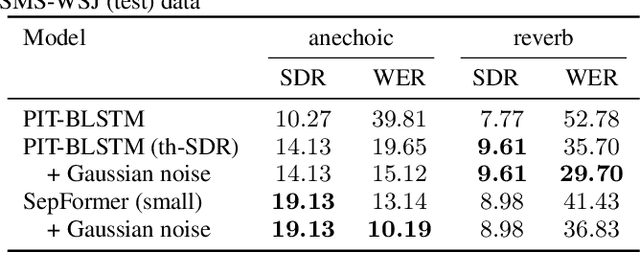
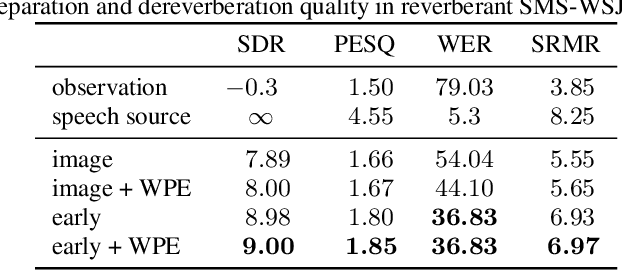
Impressive progress in neural network-based single-channel speech source separation has been made in recent years. But those improvements have been mostly reported on anechoic data, a situation that is hardly met in practice. Taking the SepFormer as a starting point, which achieves state-of-the-art performance on anechoic mixtures, we gradually modify it to optimize its performance on reverberant mixtures. Although this leads to a word error rate improvement by 8 percentage points compared to the standard SepFormer implementation, the system ends up with only marginally better performance than our improved PIT-BLSTM separation system, that is optimized with rather straightforward means. This is surprising and at the same time sobering, challenging the practical usefulness of many improvements reported in recent years for monaural source separation on nonreverberant data.