 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 4D Representation for Training-Free Agentic Reasoning from Monocular Laparoscopic Video
Apr 01, 2026Spatiotemporal reasoning is a fundamental capability for artificial intelligence (AI) in soft tissue surgery, paving the way for intelligent assistive systems and autonomous robotics. While 2D vision-language models show increasing promise at understanding surgical video, the spatial complexity of surgical scenes suggests that reasoning systems may benefit from explicit 4D representations. Here, we propose a framework for equipping surgical agents with spatiotemporal tools based on an explicit 4D representation, enabling AI systems to ground their natural language reasoning in both time and 3D space. Leveraging models for point tracking, depth, and segmentation, we develop a coherent 4D model with spatiotemporally consistent tool and tissue semantics. A Multimodal Large Language Model (MLLM) then acts as an agent on tools derived from the explicit 4D representation (e.g., trajectories) without any fine-tuning. We evaluate our method on a new dataset of 134 clinically relevant questions and find that the combination of a general purpose reasoning backbone and our 4D representation significantly improves spatiotemporal understanding and allows for 4D grounding. We demonstrate that spatiotemporal intelligence can be "assembled" from 2D MLLMs and 3D computer vision models without additional training. Code, data, and examples are available at https://tum-ai.github.io/surg4d/
TrackOR: Towards Personalized Intelligent Operating Rooms Through Robust Tracking
Aug 11, 2025Providing intelligent support to surgical teams is a key frontier in automated surgical scene understanding, with the long-term goal of improving patient outcomes. Developing personalized intelligence for all staff members requires maintaining a consistent state of who is located where for long surgical procedures, which still poses numerous computational challenges. We propose TrackOR, a framework for tackling long-term multi-person tracking and re-identification in the operating room. TrackOR uses 3D geometric signatures to achieve state-of-the-art online tracking performance (+11% Association Accuracy over the strongest baseline), while also enabling an effective offline recovery process to create analysis-ready trajectories. Our work shows that by leveraging 3D geometric information, persistent identity tracking becomes attainable, enabling a critical shift towards the more granular, staff-centric analyses required for personalized intelligent systems in the operating room. This new capability opens up various applications, including our proposed temporal pathway imprints that translate raw tracking data into actionable insights for improving team efficiency and safety and ultimately providing personalized support.
Beyond Role-Based Surgical Domain Modeling: Generalizable Re-Identification in the Operating Room
Mar 17, 2025



Surgical domain models improve workflow optimization through automated predictions of each staff member's surgical role. However, mounting evidence indicates that team familiarity and individuality impact surgical outcomes. We present a novel staff-centric modeling approach that characterizes individual team members through their distinctive movement patterns and physical characteristics, enabling long-term tracking and analysis of surgical personnel across multiple procedures. To address the challenge of inter-clinic variability, we develop a generalizable re-identification framework that encodes sequences of 3D point clouds to capture shape and articulated motion patterns unique to each individual. Our method achieves 86.19% accuracy on realistic clinical data while maintaining 75.27% accuracy when transferring between different environments - a 12% improvement over existing methods. When used to augment markerless personnel tracking, our approach improves accuracy by over 50%. Through extensive validation across three datasets and the introduction of a novel workflow visualization technique, we demonstrate how our framework can reveal novel insights into surgical team dynamics and space utilization patterns, advancing methods to analyze surgical workflows and team coordination.
Know your sensORs -- A Modality Study For Surgical Action Classification
Mar 22, 2022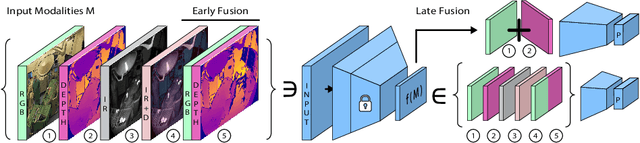
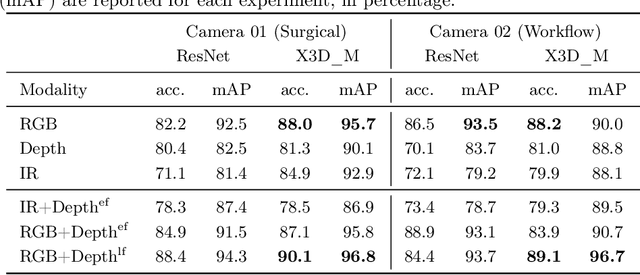
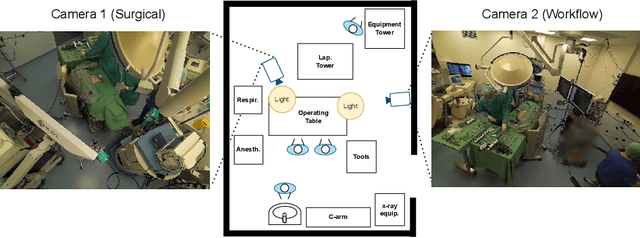
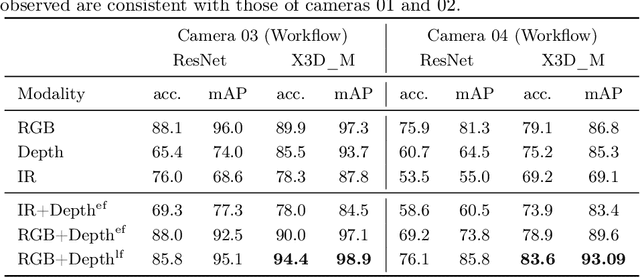
The surgical operating room (OR) presents many opportunities for automation and optimization. Videos from various sources in the OR are becoming increasingly available. The medical community seeks to leverage this wealth of data to develop automated methods to advance interventional care, lower costs, and improve overall patient outcomes. Existing datasets from OR room cameras are thus far limited in size or modalities acquired, leaving it unclear which sensor modalities are best suited for tasks such as recognizing surgical action from videos. This study demonstrates that surgical action recognition performance can vary depending on the image modalities used. We perform a methodical analysis on several commonly available sensor modalities, presenting two fusion approaches that improve classification performance. The analyses are carried out on a set of multi-view RGB-D video recordings of 18 laparoscopic procedures.