 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Loss Function for Temperature Scaling to have Better Calibrated Deep Networks
Oct 27, 2018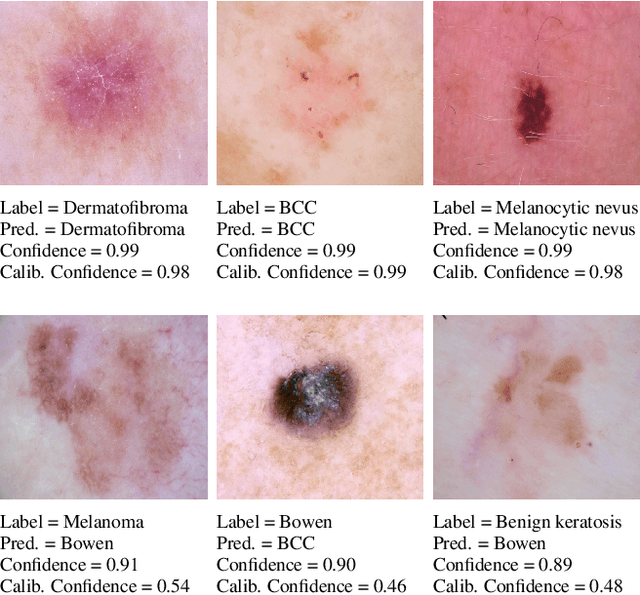
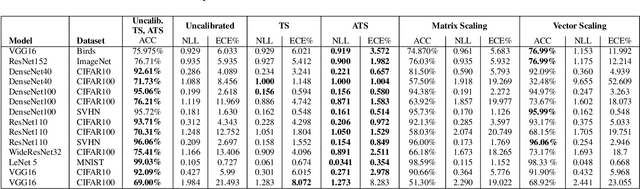
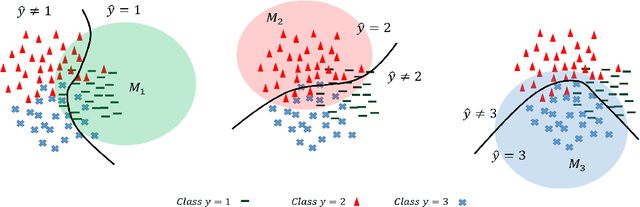
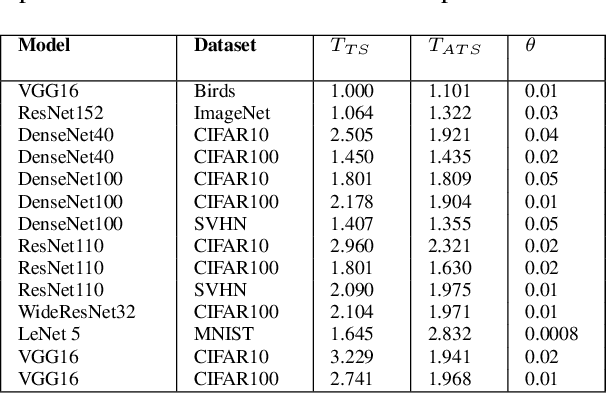
However Deep neural networks recently have achieved impressive results for different tasks, they suffer from poor uncertainty prediction. Temperature Scaling(TS) is an efficient post-processing method for calibrating DNNs toward to have more accurate uncertainty prediction. TS relies on a single parameter T which softens the logit layer of a DNN and the optimal value of it is found by minimizing on Negative Log Likelihood (NLL) loss function. In this paper, we discuss about weakness of NLL loss function, especially for DNNs with high accuracy and propose a new loss function called Attended-NLL which can improve TS calibration ability significantly
Accumulating Knowledge for Lifelong Online Learning
Oct 26, 2018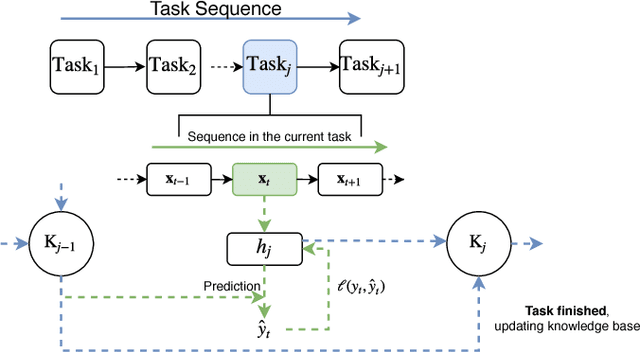

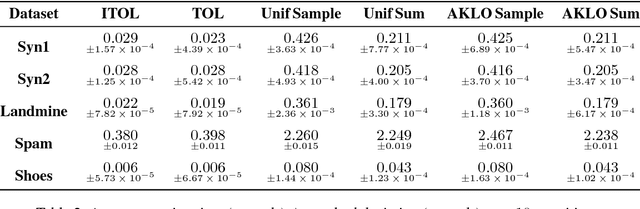
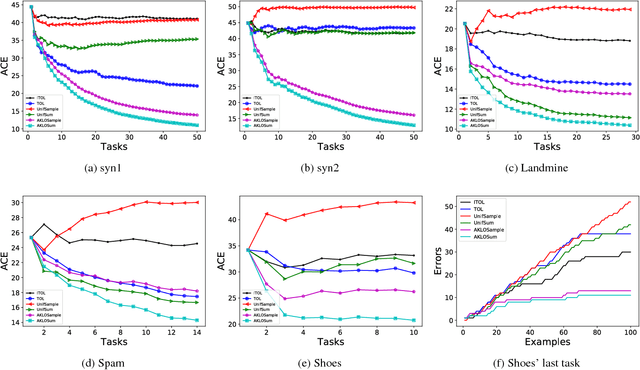
Lifelong learning can be viewed as a continuous transfer learning procedure over consecutive tasks, where learning a given task depends on accumulated knowledge --- the so-called knowledge base. Most published work on lifelong learning makes a batch processing of each task, implying that a data collection step is required beforehand. We are proposing a new framework, lifelong online learning, in which the learning procedure for each task is interactive. This is done through a computationally efficient algorithm where the predicted result for a given task is made by combining two intermediate predictions: by using only the information from the current task and by relying on the accumulated knowledge. In this work, two challenges are tackled: making no assumption on the task generation distribution, and processing with a possibly unknown number of instances for each task. We are providing a theoretical analysis of this algorithm, with a cumulative error upper bound for each task. We find that under some mild conditions, the algorithm can still benefit from a small cumulative error even when facing few interactions. Moreover, we provide experimental results on both synthetic and real datasets that validate the correct behavior and practical usefulness of the proposed algorithm.
The Surprising Creativity of Digital Evolution: A Collection of Anecdotes from the Evolutionary Computation and Artificial Life Research Communities
Aug 14, 2018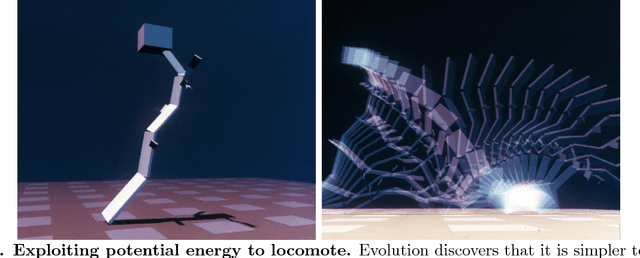



Biological evolution provides a creative fount of complex and subtle adaptations, often surprising the scientists who discover them. However, because evolution is an algorithmic process that transcends the substrate in which it occurs, evolution's creativity is not limited to nature. Indeed, many researchers in the field of digital evolution have observed their evolving algorithms and organisms subverting their intentions, exposing unrecognized bugs in their code, producing unexpected adaptations, or exhibiting outcomes uncannily convergent with ones in nature. Such stories routinely reveal creativity by evolution in these digital worlds, but they rarely fit into the standard scientific narrative. Instead they are often treated as mere obstacles to be overcome, rather than results that warrant study in their own right. The stories themselves are traded among researchers through oral tradition, but that mode of information transmission is inefficient and prone to error and outright loss. Moreover, the fact that these stories tend to be shared only among practitioners means that many natural scientists do not realize how interesting and lifelike digital organisms are and how natural their evolution can be. To our knowledge, no collection of such anecdotes has been published before. This paper is the crowd-sourced product of researchers in the fields of artificial life and evolutionary computation who have provided first-hand accounts of such cases. It thus serves as a written, fact-checked collection of scientifically important and even entertaining stories. In doing so we also present here substantial evidence that the existence and importance of evolutionary surprises extends beyond the natural world, and may indeed be a universal property of all complex evolving systems.
Evaluating and Characterizing Incremental Learning from Non-Stationary Data
Jun 18, 2018
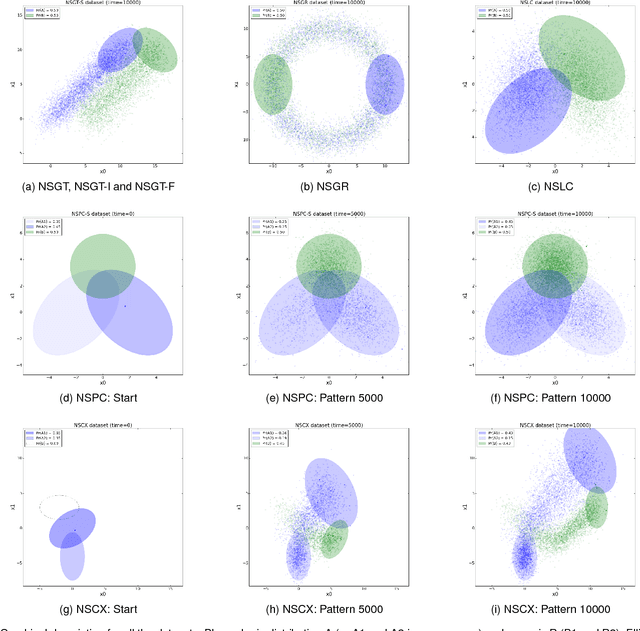
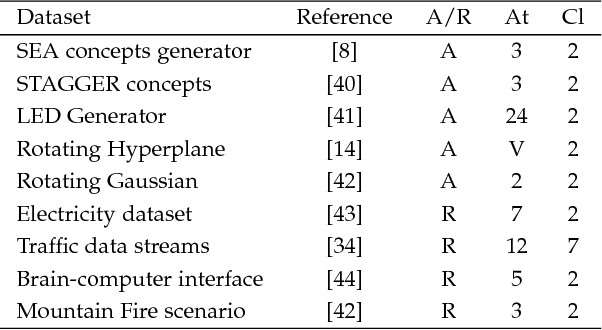
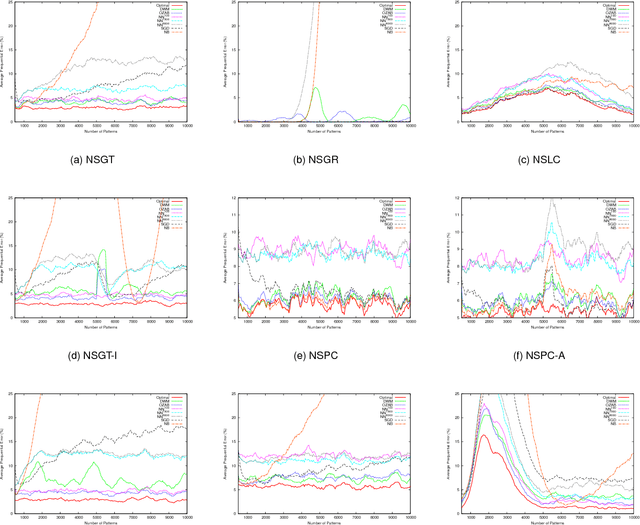
Incremental learning from non-stationary data poses special challenges to the field of machine learning. Although new algorithms have been developed for this, assessment of results and comparison of behaviors are still open problems, mainly because evaluation metrics, adapted from more traditional tasks, can be ineffective in this context. Overall, there is a lack of common testing practices. This paper thus presents a testbed for incremental non-stationary learning algorithms, based on specially designed synthetic datasets. Also, test results are reported for some well-known algorithms to show that the proposed methodology is effective at characterizing their strengths and weaknesses. It is expected that this methodology will provide a common basis for evaluating future contributions in the field.
Towards Dependable Deep Convolutional Neural Networks (CNNs) with Out-distribution Learning
May 16, 2018
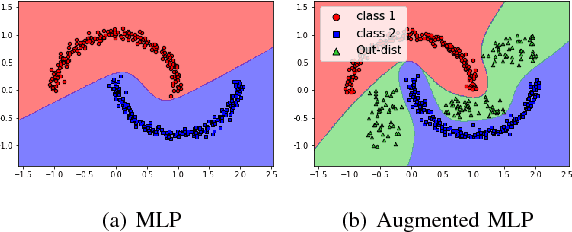

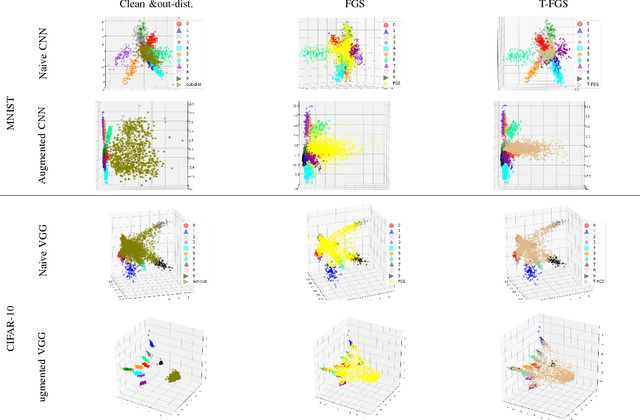
Detection and rejection of adversarial examples in security sensitive and safety-critical systems using deep CNNs is essential. In this paper, we propose an approach to augment CNNs with out-distribution learning in order to reduce misclassification rate by rejecting adversarial examples. We empirically show that our augmented CNNs can either reject or classify correctly most adversarial examples generated using well-known methods ( >95% for MNIST and >75% for CIFAR-10 on average). Furthermore, we achieve this without requiring to train using any specific type of adversarial examples and without sacrificing the accuracy of models on clean samples significantly (< 4%).
Learning to Become an Expert: Deep Networks Applied To Super-Resolution Microscopy
Mar 28, 2018
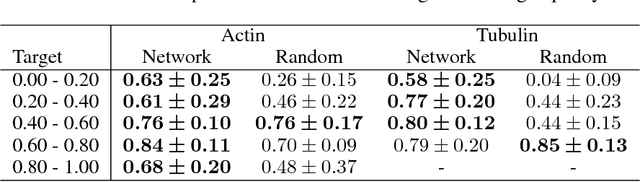

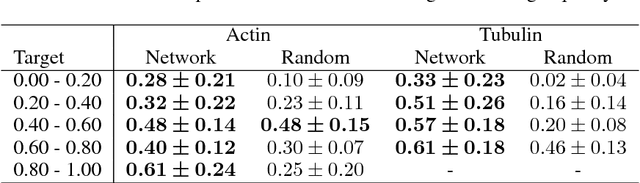
With super-resolution optical microscopy, it is now possible to observe molecular interactions in living cells. The obtained images have a very high spatial precision but their overall quality can vary a lot depending on the structure of interest and the imaging parameters. Moreover, evaluating this quality is often difficult for non-expert users. In this work, we tackle the problem of learning the quality function of super- resolution images from scores provided by experts. More specifically, we are proposing a system based on a deep neural network that can provide a quantitative quality measure of a STED image of neuronal structures given as input. We conduct a user study in order to evaluate the quality of the predictions of the neural network against those of a human expert. Results show the potential while highlighting some of the limits of the proposed approach.
Out-distribution training confers robustness to deep neural networks
Mar 01, 2018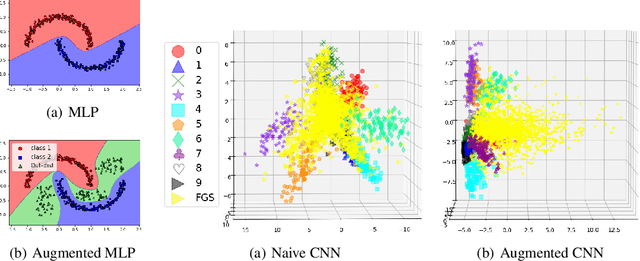
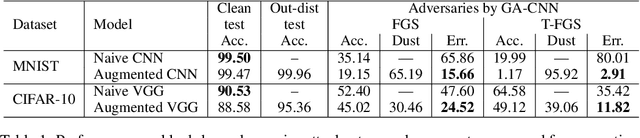


The easiness at which adversarial instances can be generated in deep neural networks raises some fundamental questions on their functioning and concerns on their use in critical systems. In this paper, we draw a connection between over-generalization and adversaries: a possible cause of adversaries lies in models designed to make decisions all over the input space, leading to inappropriate high-confidence decisions in parts of the input space not represented in the training set. We empirically show an augmented neural network, which is not trained on any types of adversaries, can increase the robustness by detecting black-box one-step adversaries, i.e. assimilated to out-distribution samples, and making generation of white-box one-step adversaries harder.
Diversity regularization in deep ensembles
Feb 22, 2018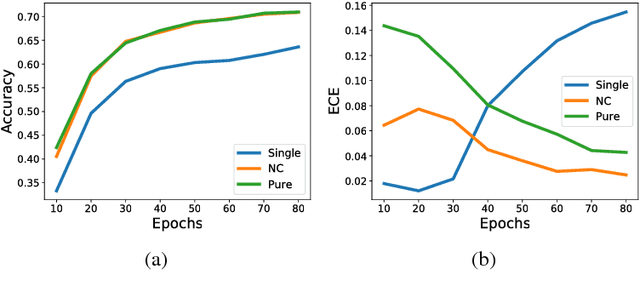

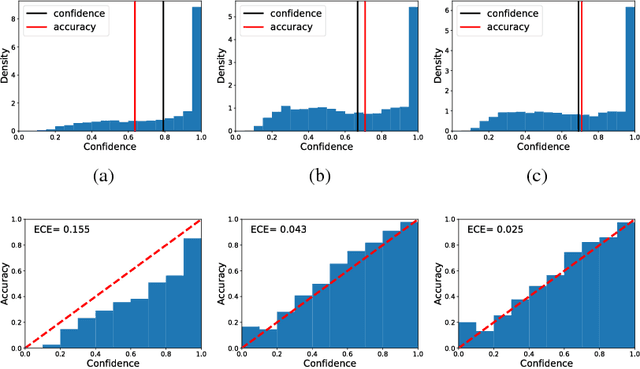

Calibrating the confidence of supervised learning models is important for a variety of contexts where the certainty over predictions should be reliable. However, it has been reported that deep neural network models are often too poorly calibrated for achieving complex tasks requiring reliable uncertainty estimates in their prediction. In this work, we are proposing a strategy for training deep ensembles with a diversity function regularization, which improves the calibration property while maintaining a similar prediction accuracy.
Learning to Predict Indoor Illumination from a Single Image
Nov 21, 2017


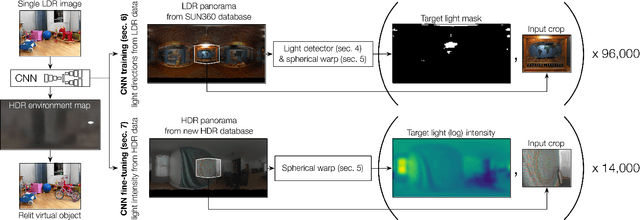
We propose an automatic method to infer high dynamic range illumination from a single, limited field-of-view, low dynamic range photograph of an indoor scene. In contrast to previous work that relies on specialized image capture, user input, and/or simple scene models, we train an end-to-end deep neural network that directly regresses a limited field-of-view photo to HDR illumination, without strong assumptions on scene geometry, material properties, or lighting. We show that this can be accomplished in a three step process: 1) we train a robust lighting classifier to automatically annotate the location of light sources in a large dataset of LDR environment maps, 2) we use these annotations to train a deep neural network that predicts the location of lights in a scene from a single limited field-of-view photo, and 3) we fine-tune this network using a small dataset of HDR environment maps to predict light intensities. This allows us to automatically recover high-quality HDR illumination estimates that significantly outperform previous state-of-the-art methods. Consequently, using our illumination estimates for applications like 3D object insertion, we can achieve results that are photo-realistic, which is validated via a perceptual user study.
Estimating Quality in Multi-Objective Bandits Optimization
Apr 20, 2017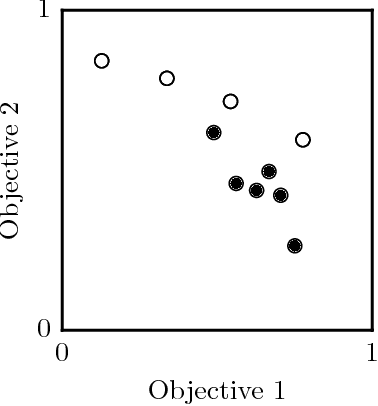
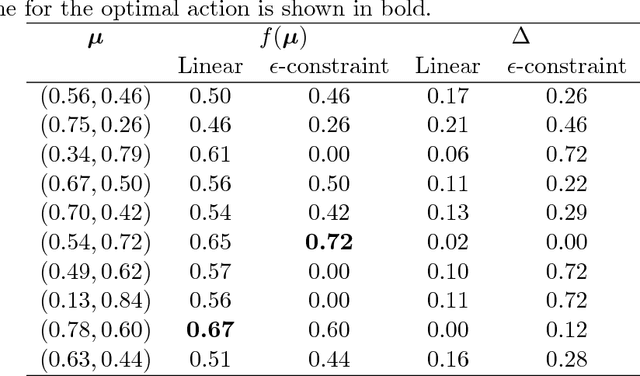
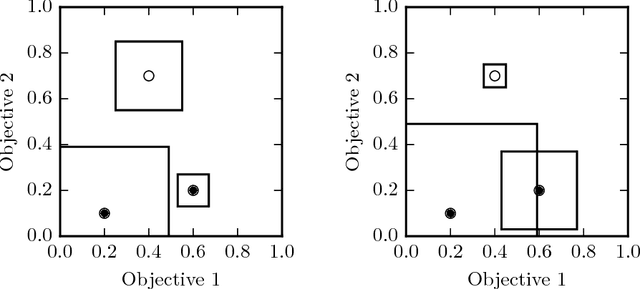
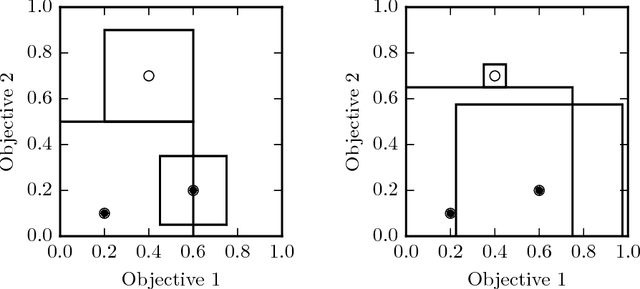
Many real-world applications are characterized by a number of conflicting performance measures. As optimizing in a multi-objective setting leads to a set of non-dominated solutions, a preference function is required for selecting the solution with the appropriate trade-off between the objectives. The question is: how good do estimations of these objectives have to be in order for the solution maximizing the preference function to remain unchanged? In this paper, we introduce the concept of preference radius to characterize the robustness of the preference function and provide guidelines for controlling the quality of estimations in the multi-objective setting. More specifically, we provide a general formulation of multi-objective optimization under the bandits setting. We show how the preference radius relates to the optimal gap and we use this concept to provide a theoretical analysis of the Thompson sampling algorithm from multivariate normal priors. We finally present experiments to support the theoretical results and highlight the fact that one cannot simply scalarize multi-objective problems into single-objective problems.