 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Neural Segmental Models for Speech Recognition
Aug 15, 2017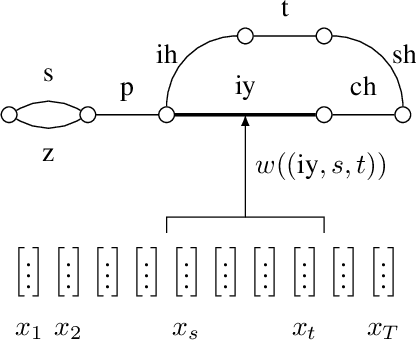
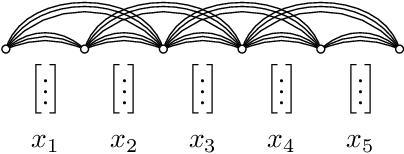
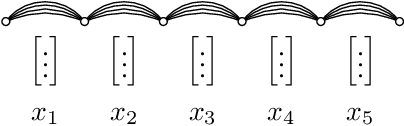
Segmental models are an alternative to frame-based models for sequence prediction, where hypothesized path weights are based on entire segment scores rather than a single frame at a time. Neural segmental models are segmental models that use neural network-based weight functions. Neural segmental models have achieved competitive results for speech recognition, and their end-to-end training has been explored in several studies. In this work, we review neural segmental models, which can be viewed as consisting of a neural network-based acoustic encoder and a finite-state transducer decoder. We study end-to-end segmental models with different weight functions, including ones based on frame-level neural classifiers and on segmental recurrent neural networks. We study how reducing the search space size impacts performance under different weight functions. We also compare several loss functions for end-to-end training. Finally, we explore training approaches, including multi-stage vs. end-to-end training and multitask training that combines segmental and frame-level losses.
Reference-Aware Language Models
Aug 09, 2017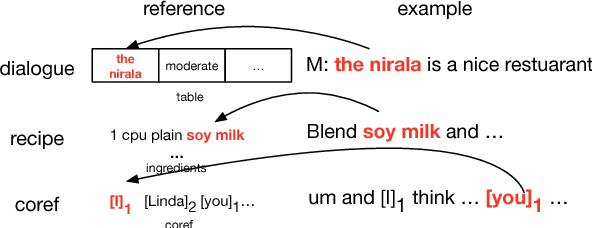

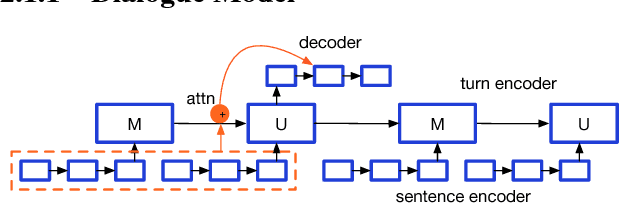
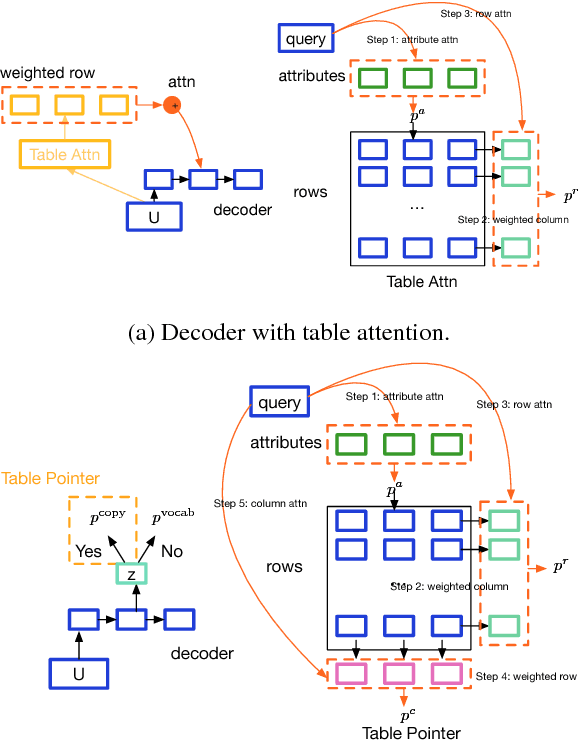
We propose a general class of language models that treat reference as an explicit stochastic latent variable. This architecture allows models to create mentions of entities and their attributes by accessing external databases (required by, e.g., dialogue generation and recipe generation) and internal state (required by, e.g. language models which are aware of coreference). This facilitates the incorporation of information that can be accessed in predictable locations in databases or discourse context, even when the targets of the reference may be rare words. Experiments on three tasks shows our model variants based on deterministic attention.
Frame-Semantic Parsing with Softmax-Margin Segmental RNNs and a Syntactic Scaffold
Jun 29, 2017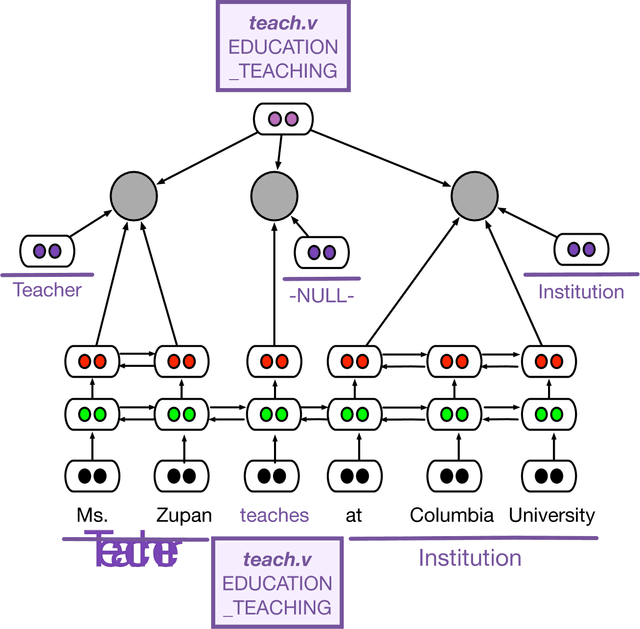
We present a new, efficient frame-semantic parser that labels semantic arguments to FrameNet predicates. Built using an extension to the segmental RNN that emphasizes recall, our basic system achieves competitive performance without any calls to a syntactic parser. We then introduce a method that uses phrase-syntactic annotations from the Penn Treebank during training only, through a multitask objective; no parsing is required at training or test time. This "syntactic scaffold" offers a cheaper alternative to traditional syntactic pipelining, and achieves state-of-the-art performance.
Multitask Learning with CTC and Segmental CRF for Speech Recognition
Jun 05, 2017
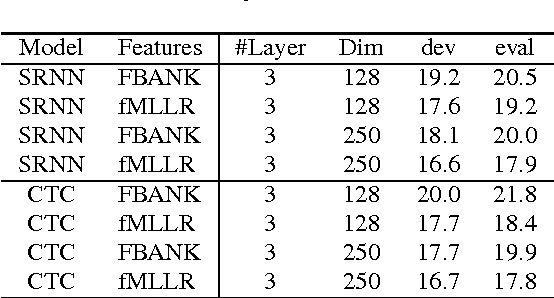
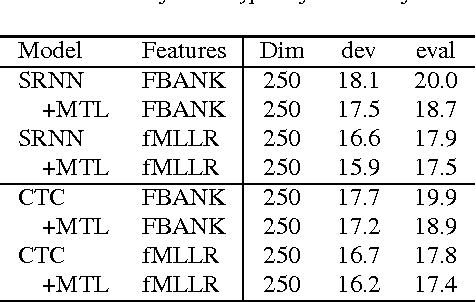

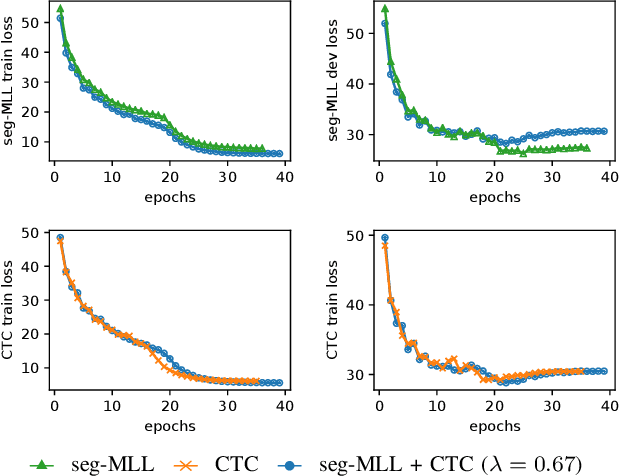
Segmental conditional random fields (SCRFs) and connectionist temporal classification (CTC) are two sequence labeling methods used for end-to-end training of speech recognition models. Both models define a transcription probability by marginalizing decisions about latent segmentation alternatives to derive a sequence probability: the former uses a globally normalized joint model of segment labels and durations, and the latter classifies each frame as either an output symbol or a "continuation" of the previous label. In this paper, we train a recognition model by optimizing an interpolation between the SCRF and CTC losses, where the same recurrent neural network (RNN) encoder is used for feature extraction for both outputs. We find that this multitask objective improves recognition accuracy when decoding with either the SCRF or CTC models. Additionally, we show that CTC can also be used to pretrain the RNN encoder, which improves the convergence rate when learning the joint model.
Generative and Discriminative Text Classification with Recurrent Neural Networks
May 26, 2017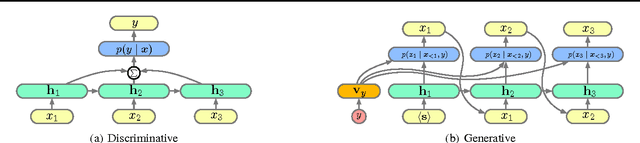
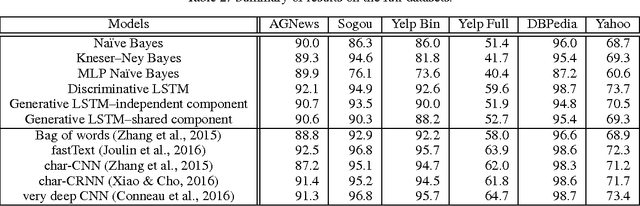
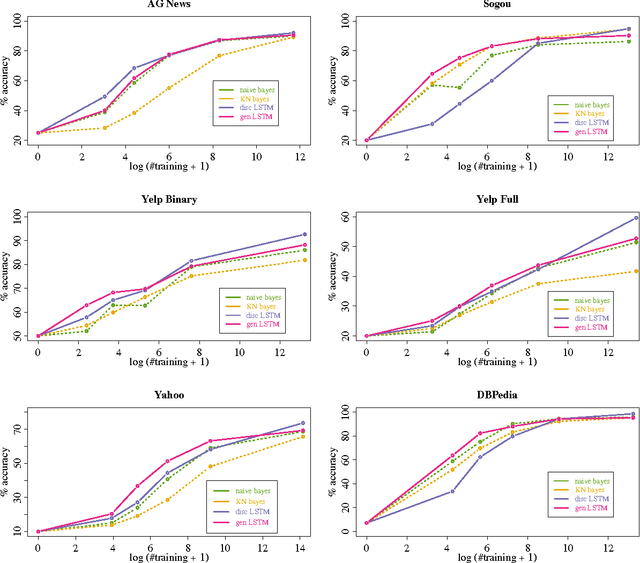
We empirically characterize the performance of discriminative and generative LSTM models for text classification. We find that although RNN-based generative models are more powerful than their bag-of-words ancestors (e.g., they account for conditional dependencies across words in a document), they have higher asymptotic error rates than discriminatively trained RNN models. However we also find that generative models approach their asymptotic error rate more rapidly than their discriminative counterparts---the same pattern that Ng & Jordan (2001) proved holds for linear classification models that make more naive conditional independence assumptions. Building on this finding, we hypothesize that RNN-based generative classification models will be more robust to shifts in the data distribution. This hypothesis is confirmed in a series of experiments in zero-shot and continual learning settings that show that generative models substantially outperform discriminative models.
On-the-fly Operation Batching in Dynamic Computation Graphs
May 22, 2017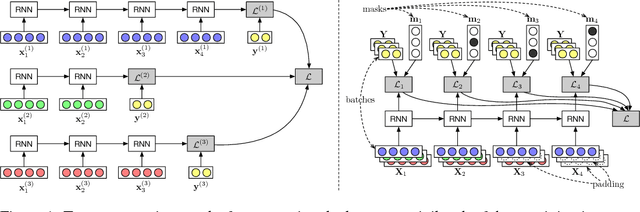

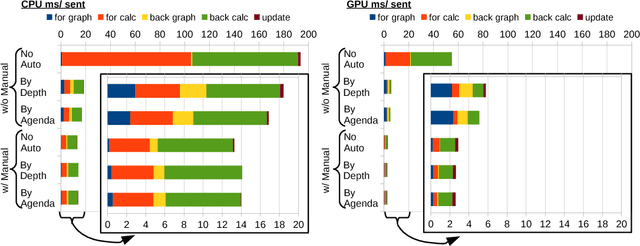
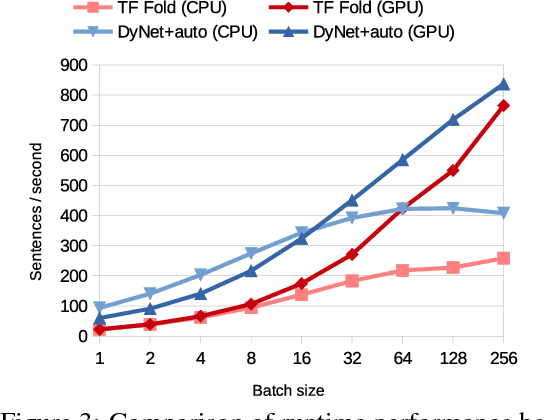
Dynamic neural network toolkits such as PyTorch, DyNet, and Chainer offer more flexibility for implementing models that cope with data of varying dimensions and structure, relative to toolkits that operate on statically declared computations (e.g., TensorFlow, CNTK, and Theano). However, existing toolkits - both static and dynamic - require that the developer organize the computations into the batches necessary for exploiting high-performance algorithms and hardware. This batching task is generally difficult, but it becomes a major hurdle as architectures become complex. In this paper, we present an algorithm, and its implementation in the DyNet toolkit, for automatically batching operations. Developers simply write minibatch computations as aggregations of single instance computations, and the batching algorithm seamlessly executes them, on the fly, using computationally efficient batched operations. On a variety of tasks, we obtain throughput similar to that obtained with manual batches, as well as comparable speedups over single-instance learning on architectures that are impractical to batch manually.
Ontology-Aware Token Embeddings for Prepositional Phrase Attachment
May 08, 2017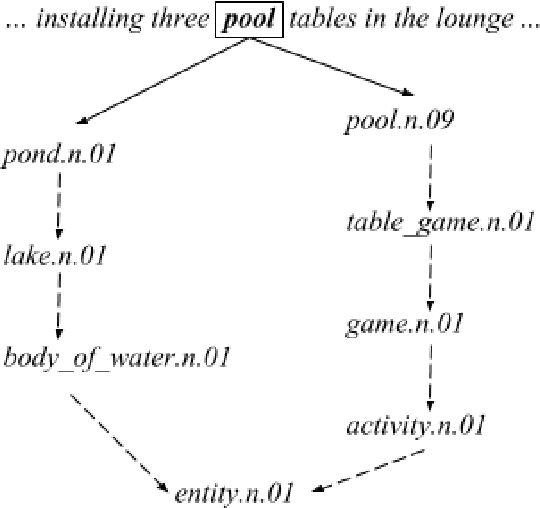

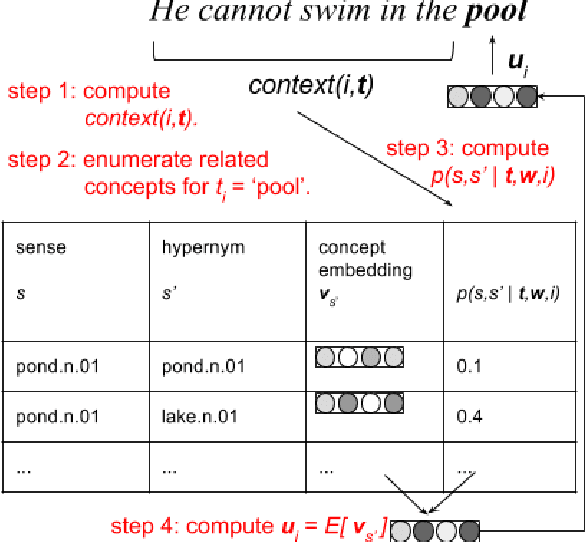
Type-level word embeddings use the same set of parameters to represent all instances of a word regardless of its context, ignoring the inherent lexical ambiguity in language. Instead, we embed semantic concepts (or synsets) as defined in WordNet and represent a word token in a particular context by estimating a distribution over relevant semantic concepts. We use the new, context-sensitive embeddings in a model for predicting prepositional phrase(PP) attachments and jointly learn the concept embeddings and model parameters. We show that using context-sensitive embeddings improves the accuracy of the PP attachment model by 5.4% absolute points, which amounts to a 34.4% relative reduction in errors.
Learning to Create and Reuse Words in Open-Vocabulary Neural Language Modeling
Apr 23, 2017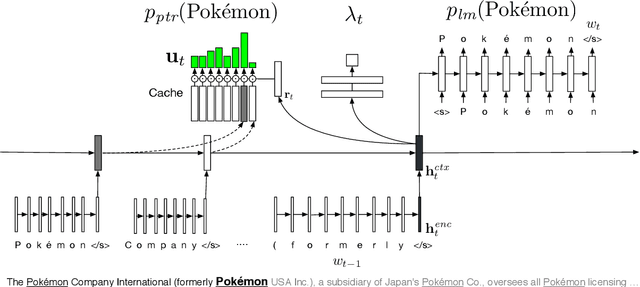
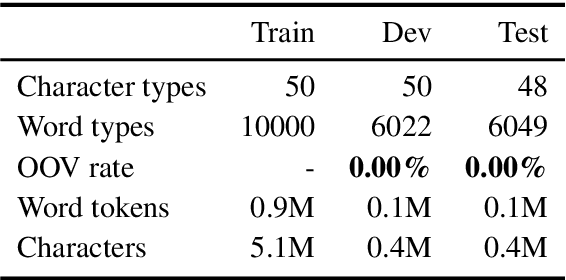
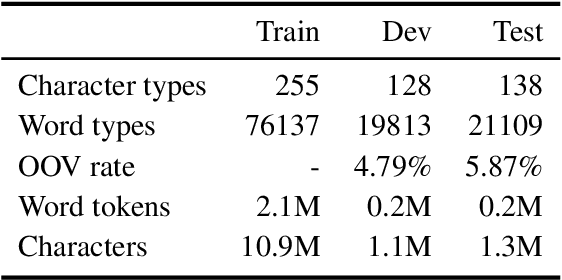
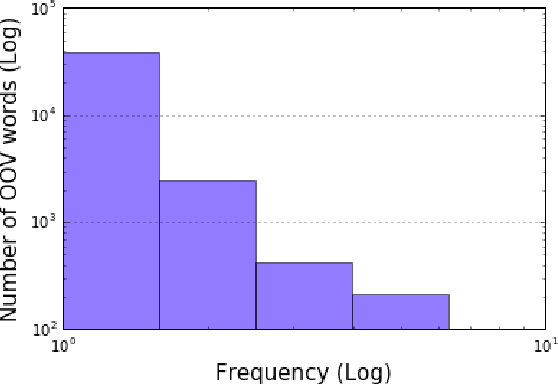
Fixed-vocabulary language models fail to account for one of the most characteristic statistical facts of natural language: the frequent creation and reuse of new word types. Although character-level language models offer a partial solution in that they can create word types not attested in the training corpus, they do not capture the "bursty" distribution of such words. In this paper, we augment a hierarchical LSTM language model that generates sequences of word tokens character by character with a caching mechanism that learns to reuse previously generated words. To validate our model we construct a new open-vocabulary language modeling corpus (the Multilingual Wikipedia Corpus, MWC) from comparable Wikipedia articles in 7 typologically diverse languages and demonstrate the effectiveness of our model across this range of languages.
Differentiable Scheduled Sampling for Credit Assignment
Apr 23, 2017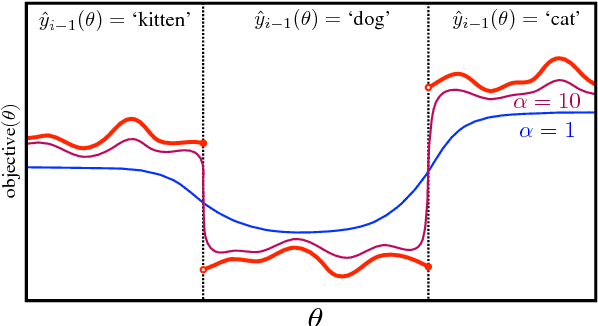
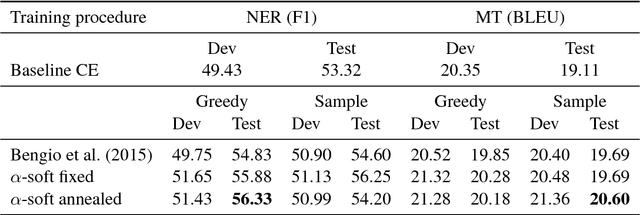
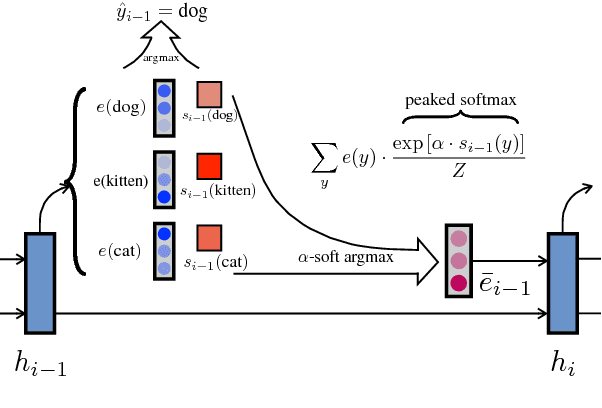
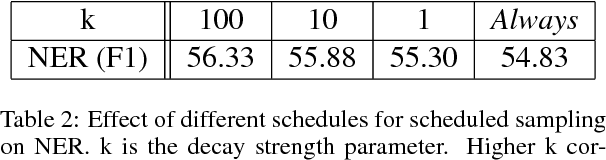
We demonstrate that a continuous relaxation of the argmax operation can be used to create a differentiable approximation to greedy decoding for sequence-to-sequence (seq2seq) models. By incorporating this approximation into the scheduled sampling training procedure (Bengio et al., 2015)--a well-known technique for correcting exposure bias--we introduce a new training objective that is continuous and differentiable everywhere and that can provide informative gradients near points where previous decoding decisions change their value. In addition, by using a related approximation, we demonstrate a similar approach to sampled-based training. Finally, we show that our approach outperforms cross-entropy training and scheduled sampling procedures in two sequence prediction tasks: named entity recognition and machine translation.
The Neural Noisy Channel
Mar 06, 2017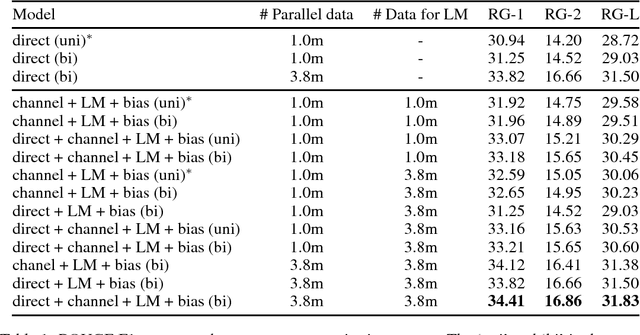
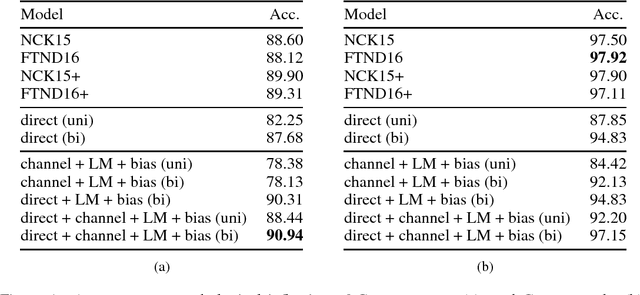
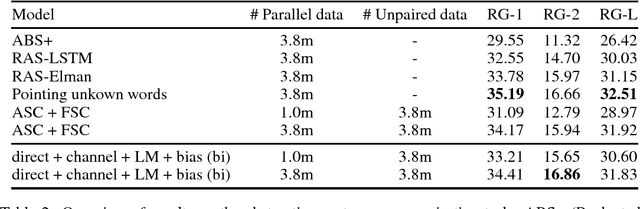
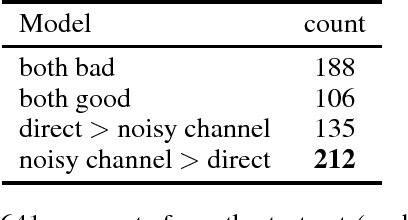
We formulate sequence to sequence transduction as a noisy channel decoding problem and use recurrent neural networks to parameterise the source and channel models. Unlike direct models which can suffer from explaining-away effects during training, noisy channel models must produce outputs that explain their inputs, and their component models can be trained with not only paired training samples but also unpaired samples from the marginal output distribution. Using a latent variable to control how much of the conditioning sequence the channel model needs to read in order to generate a subsequent symbol, we obtain a tractable and effective beam search decoder. Experimental results on abstractive sentence summarisation, morphological inflection, and machine translation show that noisy channel models outperform direct models, and that they significantly benefit from increased amounts of unpaired output data that direct models cannot easily use.