 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy, Joint Syntactic-Semantic Parsing with Stack LSTMs
Jul 05, 2018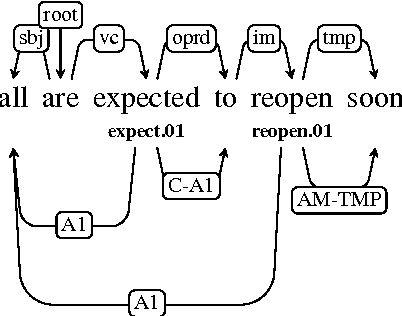


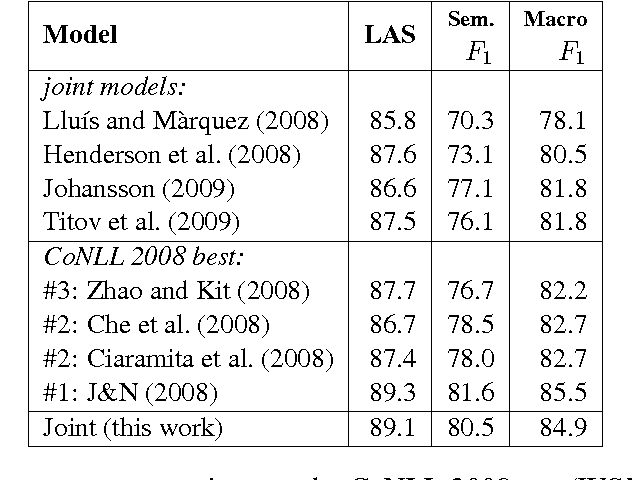
We present a transition-based parser that jointly produces syntactic and semantic dependencies. It learns a representation of the entire algorithm state, using stack long short-term memories. Our greedy inference algorithm has linear time, including feature extraction. On the CoNLL 2008--9 English shared tasks, we obtain the best published parsing performance among models that jointly learn syntax and semantics.
Finding Syntax in Human Encephalography with Beam Search
Jun 11, 2018

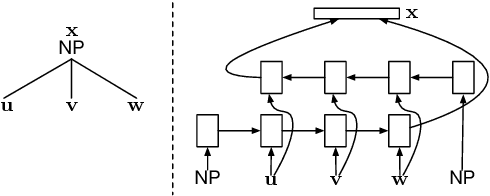

Recurrent neural network grammars (RNNGs) are generative models of (tree,string) pairs that rely on neural networks to evaluate derivational choices. Parsing with them using beam search yields a variety of incremental complexity metrics such as word surprisal and parser action count. When used as regressors against human electrophysiological responses to naturalistic text, they derive two amplitude effects: an early peak and a P600-like later peak. By contrast, a non-syntactic neural language model yields no reliable effects. Model comparisons attribute the early peak to syntactic composition within the RNNG. This pattern of results recommends the RNNG+beam search combination as a mechanistic model of the syntactic processing that occurs during normal human language comprehension.
Unsupervised Text Style Transfer using Language Models as Discriminators
May 31, 2018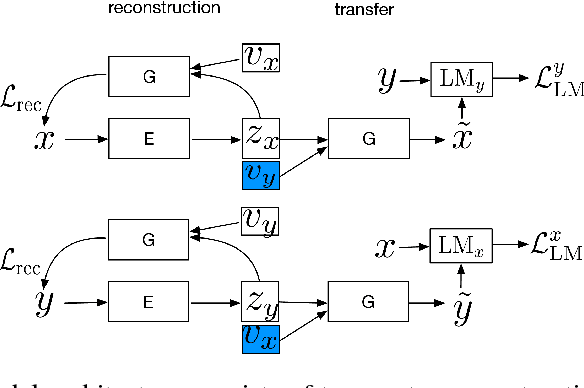
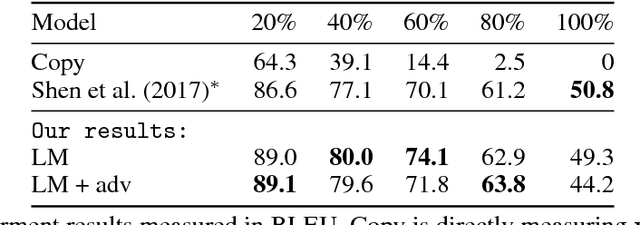
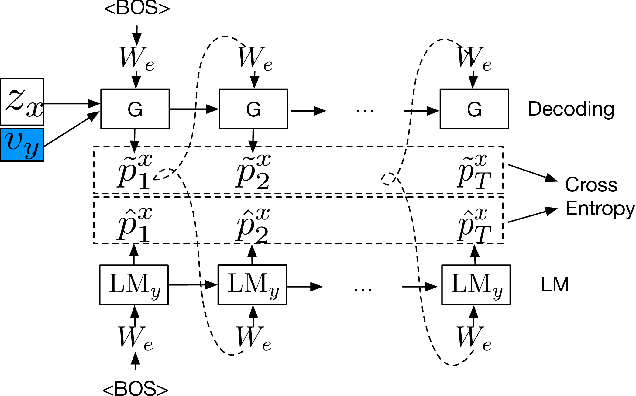
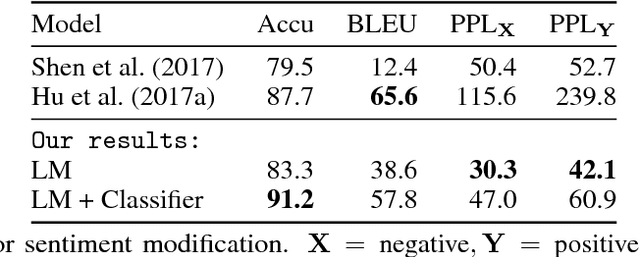
Binary classifiers are often employed as discriminators in GAN-based unsupervised style transfer systems to ensure that transferred sentences are similar to sentences in the target domain. One difficulty with this approach is that the error signal provided by the discriminator can be unstable and is sometimes insufficient to train the generator to produce fluent language. In this paper, we propose a new technique that uses a target domain language model as the discriminator, providing richer and more stable token-level feedback during the learning process. We train the generator to minimize the negative log likelihood (NLL) of generated sentences, evaluated by the language model. By using a continuous approximation of discrete sampling under the generator, our model can be trained using back-propagation in an end- to-end fashion. Moreover, our empirical results show that when using a language model as a structured discriminator, it is possible to forgoe adversarial steps during training, making the process more stable. We compare our model with previous work using convolutional neural networks (CNNs) as discriminators and show that our approach leads to improved performance on three tasks: word substitution decipherment, sentiment modification, and related language translation.
Fast Parametric Learning with Activation Memorization
Mar 27, 2018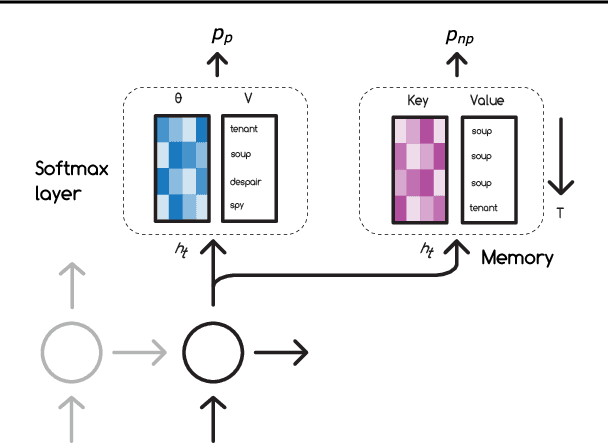
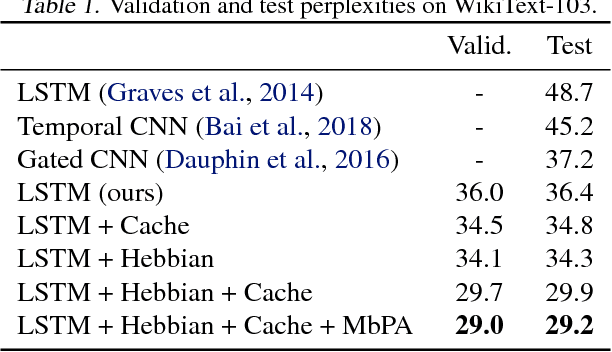
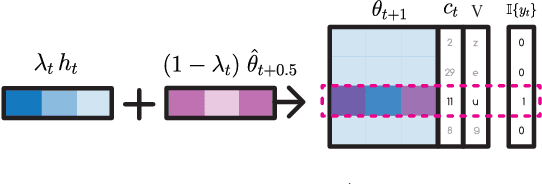
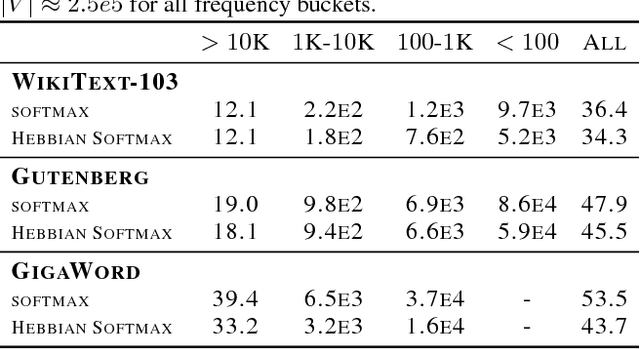
Neural networks trained with backpropagation often struggle to identify classes that have been observed a small number of times. In applications where most class labels are rare, such as language modelling, this can become a performance bottleneck. One potential remedy is to augment the network with a fast-learning non-parametric model which stores recent activations and class labels into an external memory. We explore a simplified architecture where we treat a subset of the model parameters as fast memory stores. This can help retain information over longer time intervals than a traditional memory, and does not require additional space or compute. In the case of image classification, we display faster binding of novel classes on an Omniglot image curriculum task. We also show improved performance for word-based language models on news reports (GigaWord), books (Project Gutenberg) and Wikipedia articles (WikiText-103) --- the latter achieving a state-of-the-art perplexity of 29.2.
Learning Deep Generative Models of Graphs
Mar 08, 2018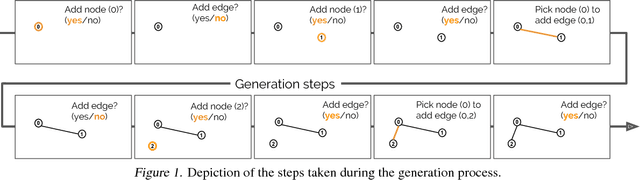
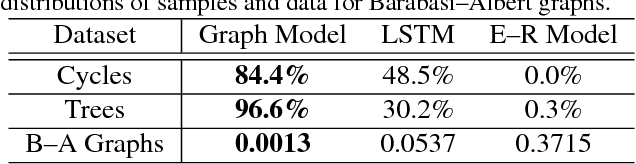
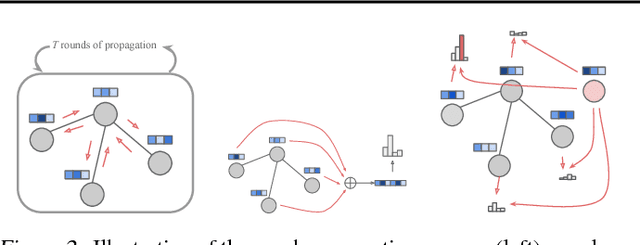
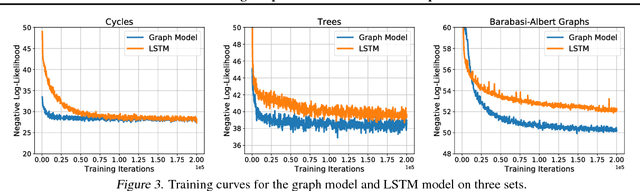
Graphs are fundamental data structures which concisely capture the relational structure in many important real-world domains, such as knowledge graphs, physical and social interactions, language, and chemistry. Here we introduce a powerful new approach for learning generative models over graphs, which can capture both their structure and attributes. Our approach uses graph neural networks to express probabilistic dependencies among a graph's nodes and edges, and can, in principle, learn distributions over any arbitrary graph. In a series of experiments our results show that once trained, our models can generate good quality samples of both synthetic graphs as well as real molecular graphs, both unconditionally and conditioned on data. Compared to baselines that do not use graph-structured representations, our models often perform far better. We also explore key challenges of learning generative models of graphs, such as how to handle symmetries and ordering of elements during the graph generation process, and offer possible solutions. Our work is the first and most general approach for learning generative models over arbitrary graphs, and opens new directions for moving away from restrictions of vector- and sequence-like knowledge representations, toward more expressive and flexible relational data structures.
Paraphrase-Supervised Models of Compositionality
Jan 31, 2018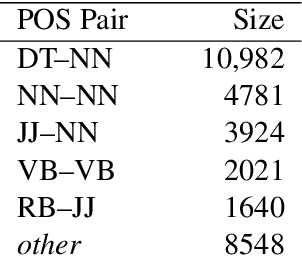
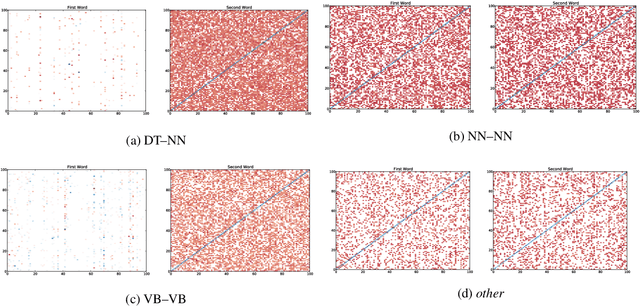
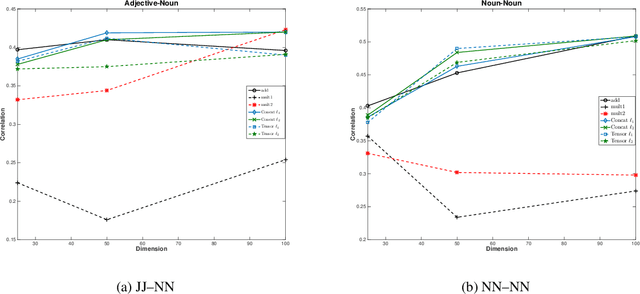
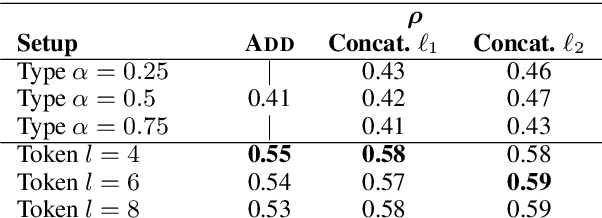
Compositional vector space models of meaning promise new solutions to stubborn language understanding problems. This paper makes two contributions toward this end: (i) it uses automatically-extracted paraphrase examples as a source of supervision for training compositional models, replacing previous work which relied on manual annotations used for the same purpose, and (ii) develops a context-aware model for scoring phrasal compositionality. Experimental results indicate that these multiple sources of information can be used to learn partial semantic supervision that matches previous techniques in intrinsic evaluation tasks. Our approaches are also evaluated for their impact on a machine translation system where we show improvements in translation quality, demonstrating that compositionality in interpretation correlates with compositionality in translation.
The NarrativeQA Reading Comprehension Challenge
Dec 19, 2017Reading comprehension (RC)---in contrast to information retrieval---requires integrating information and reasoning about events, entities, and their relations across a full document. Question answering is conventionally used to assess RC ability, in both artificial agents and children learning to read. However, existing RC datasets and tasks are dominated by questions that can be solved by selecting answers using superficial information (e.g., local context similarity or global term frequency); they thus fail to test for the essential integrative aspect of RC. To encourage progress on deeper comprehension of language, we present a new dataset and set of tasks in which the reader must answer questions about stories by reading entire books or movie scripts. These tasks are designed so that successfully answering their questions requires understanding the underlying narrative rather than relying on shallow pattern matching or salience. We show that although humans solve the tasks easily, standard RC models struggle on the tasks presented here. We provide an analysis of the dataset and the challenges it presents.
On the State of the Art of Evaluation in Neural Language Models
Nov 20, 2017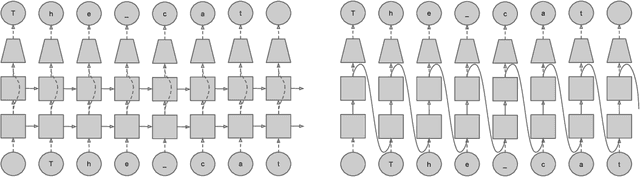
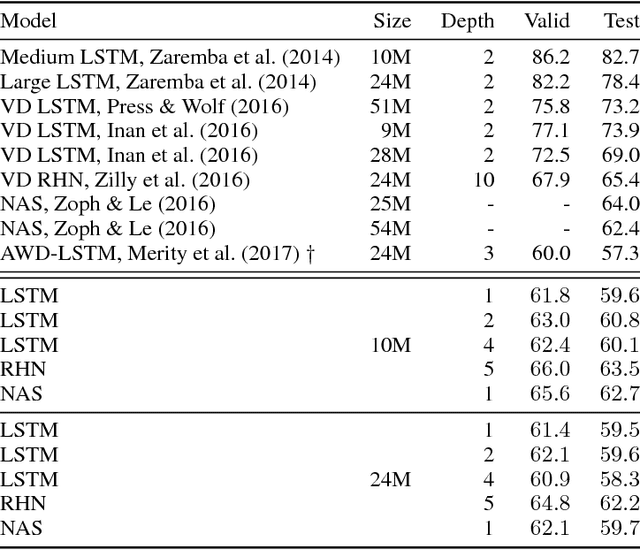
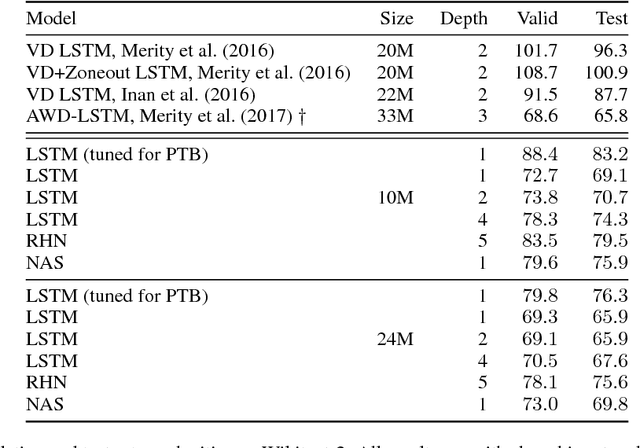
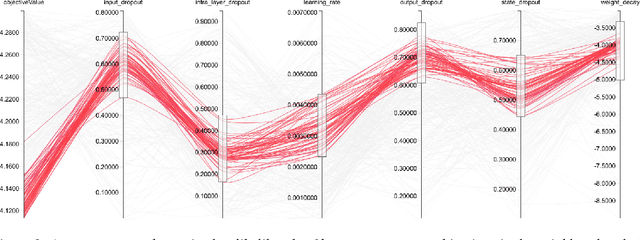
Ongoing innovations in recurrent neural network architectures have provided a steady influx of apparently state-of-the-art results on language modelling benchmarks. However, these have been evaluated using differing code bases and limited computational resources, which represent uncontrolled sources of experimental variation. We reevaluate several popular architectures and regularisation methods with large-scale automatic black-box hyperparameter tuning and arrive at the somewhat surprising conclusion that standard LSTM architectures, when properly regularised, outperform more recent models. We establish a new state of the art on the Penn Treebank and Wikitext-2 corpora, as well as strong baselines on the Hutter Prize dataset.
Program Induction by Rationale Generation : Learning to Solve and Explain Algebraic Word Problems
Oct 23, 2017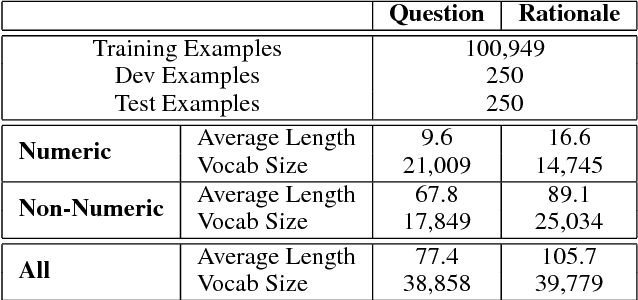
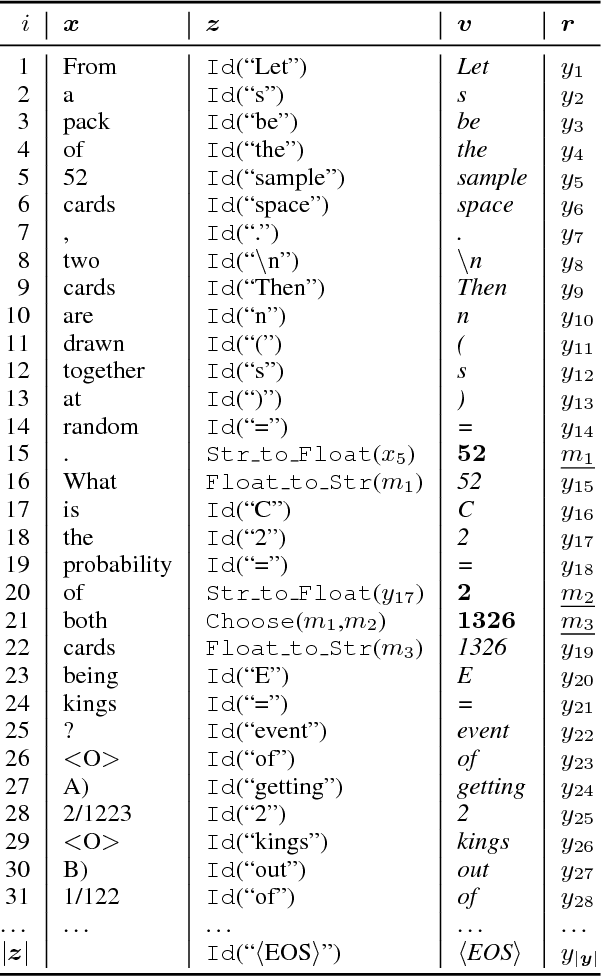
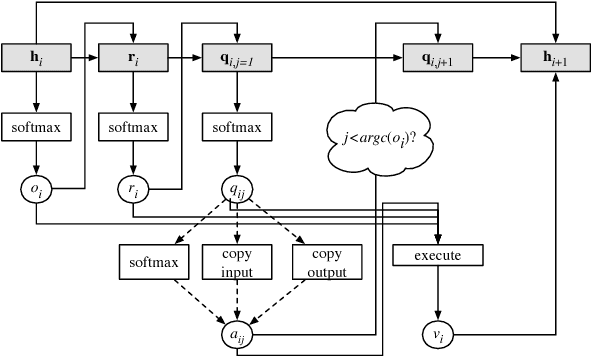
Solving algebraic word problems requires executing a series of arithmetic operations---a program---to obtain a final answer. However, since programs can be arbitrarily complicated, inducing them directly from question-answer pairs is a formidable challenge. To make this task more feasible, we solve these problems by generating answer rationales, sequences of natural language and human-readable mathematical expressions that derive the final answer through a series of small steps. Although rationales do not explicitly specify programs, they provide a scaffolding for their structure via intermediate milestones. To evaluate our approach, we have created a new 100,000-sample dataset of questions, answers and rationales. Experimental results show that indirect supervision of program learning via answer rationales is a promising strategy for inducing arithmetic programs.
A Continuous Relaxation of Beam Search for End-to-end Training of Neural Sequence Models
Oct 06, 2017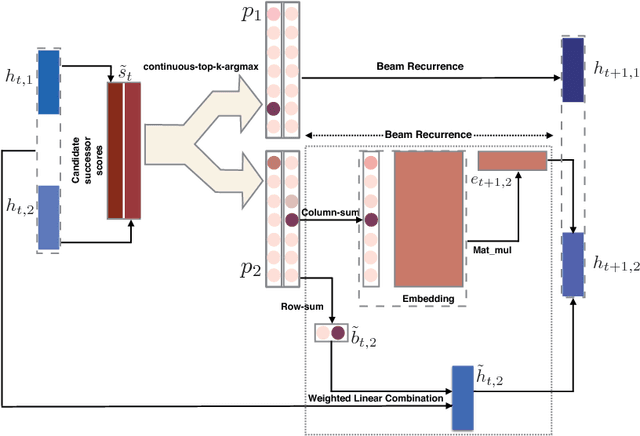
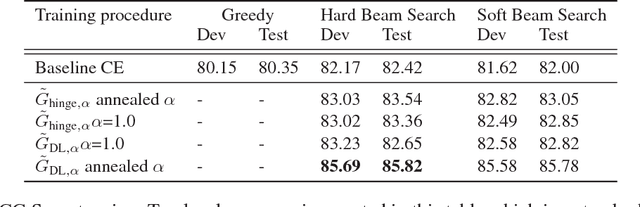
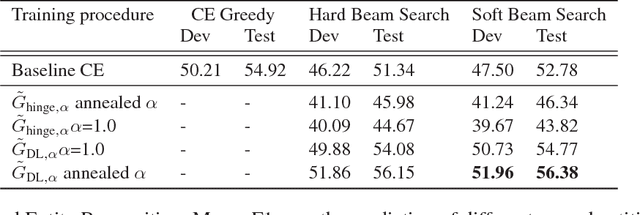
Beam search is a desirable choice of test-time decoding algorithm for neural sequence models because it potentially avoids search errors made by simpler greedy methods. However, typical cross entropy training procedures for these models do not directly consider the behaviour of the final decoding method. As a result, for cross-entropy trained models, beam decoding can sometimes yield reduced test performance when compared with greedy decoding. In order to train models that can more effectively make use of beam search, we propose a new training procedure that focuses on the final loss metric (e.g. Hamming loss) evaluated on the output of beam search. While well-defined, this "direct loss" objective is itself discontinuous and thus difficult to optimize. Hence, in our approach, we form a sub-differentiable surrogate objective by introducing a novel continuous approximation of the beam search decoding procedure. In experiments, we show that optimizing this new training objective yields substantially better results on two sequence tasks (Named Entity Recognition and CCG Supertagging) when compared with both cross entropy trained greedy decoding and cross entropy trained beam decoding baselines.