 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Told Me to Do It: Measuring Instructional Text-induced Private Data Leakage in LLM Agents
Mar 12, 2026High-privilege LLM agents that autonomously process external documentation are increasingly trusted to automate tasks by reading and executing project instructions, yet they are granted terminal access, filesystem control, and outbound network connectivity with minimal security oversight. We identify and systematically measure a fundamental vulnerability in this trust model, which we term the \emph{Trusted Executor Dilemma}: agents execute documentation-embedded instructions, including adversarial ones, at high rates because they cannot distinguish malicious directives from legitimate setup guidance. This vulnerability is a structural consequence of the instruction-following design paradigm, not an implementation bug. To structure our measurement, we formalize a three-dimensional taxonomy covering linguistic disguise, structural obfuscation, and semantic abstraction, and construct \textbf{ReadSecBench}, a benchmark of 500 real-world README files enabling reproducible evaluation. Experiments on the commercially deployed computer-use agent show end-to-end exfiltration success rates up to 85\%, consistent across five programming languages and three injection positions. Cross-model evaluation on four LLM families in a simulation environment confirms that semantic compliance with injected instructions is consistent across model families. A 15-participant user study yields a 0\% detection rate across all participants, and evaluation of 12 rule-based and 6 LLM-based defenses shows neither category achieves reliable detection without unacceptable false-positive rates. Together, these results quantify a persistent \emph{Semantic-Safety Gap} between agents' functional compliance and their security awareness, establishing that documentation-embedded instruction injection is a persistent and currently unmitigated threat to high-privilege LLM agent deployments.
Visualizing Automatic Speech Recognition -- Means for a Better Understanding?
Feb 01, 2022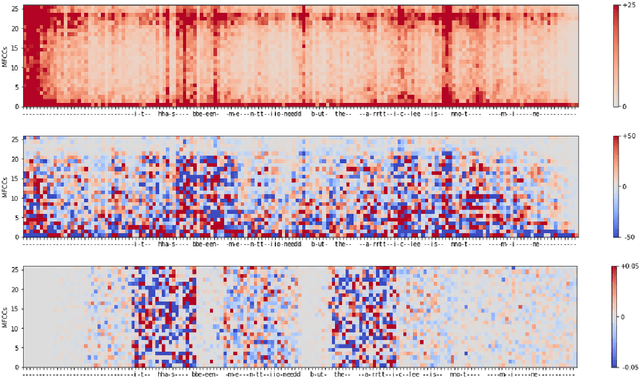
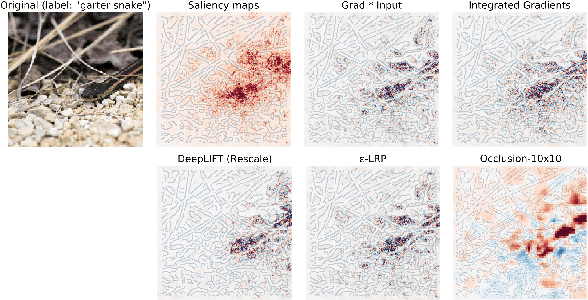
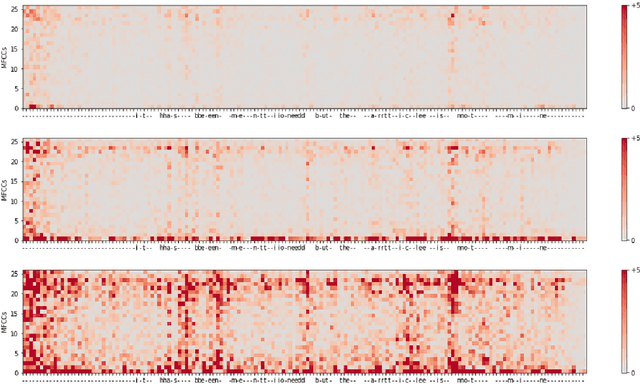
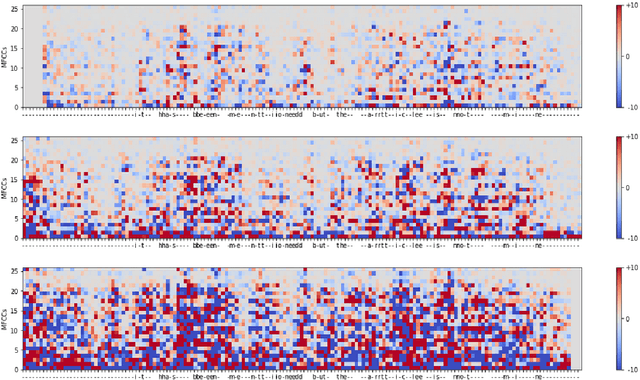
Automatic speech recognition (ASR) is improving ever more at mimicking human speech processing. The functioning of ASR, however, remains to a large extent obfuscated by the complex structure of the deep neural networks (DNNs) they are based on. In this paper, we show how so-called attribution methods, that we import from image recognition and suitably adapt to handle audio data, can help to clarify the working of ASR. Taking DeepSpeech, an end-to-end model for ASR, as a case study, we show how these techniques help to visualize which features of the input are the most influential in determining the output. We focus on three visualization techniques: Layer-wise Relevance Propagation (LRP), Saliency Maps, and Shapley Additive Explanations (SHAP). We compare these methods and discuss potential further applications, such as in the detection of adversarial examples.
DLA: Dense-Layer-Analysis for Adversarial Example Detection
Nov 05, 2019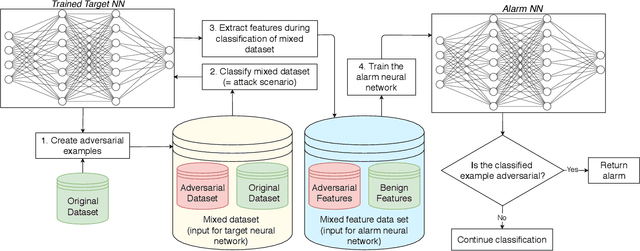
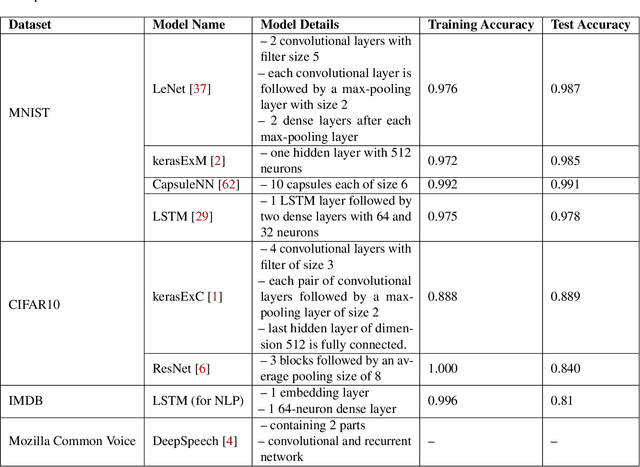


In recent years Deep Neural Networks (DNNs) have achieved remarkable results and even showed super-human capabilities in a broad range of domains. This led people to trust in DNNs' classifications and resulting actions even in security-sensitive environments like autonomous driving. Despite their impressive achievements, DNNs are known to be vulnerable to adversarial examples. Such inputs contain small perturbations to intentionally fool the attacked model. In this paper, we present a novel end-to-end framework to detect such attacks during classification without influencing the target model's performance. Inspired by recent research in neuron-coverage guided testing we show that dense layers of DNNs carry security-sensitive information. With a secondary DNN we analyze the activation patterns of the dense layers during classification runtime, which enables effective and real-time detection of adversarial examples. Our prototype implementation successfully detects adversarial examples in image, natural language, and audio processing. Thereby, we cover a variety of target DNNs, including Long Short Term Memory (LSTM) architectures. In addition, to effectively defend against state-of-the-art attacks, our approach generalizes between different sets of adversarial examples. Thus, our method most likely enables us to detect even future, yet unknown attacks. Finally, during white-box adaptive attacks, we show our method cannot be easily bypassed.