 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeButterfly Effect Attack: Tiny and Seemingly Unrelated Perturbations for Object Detection
Nov 14, 2022



This work aims to explore and identify tiny and seemingly unrelated perturbations of images in object detection that will lead to performance degradation. While tininess can naturally be defined using $L_p$ norms, we characterize the degree of "unrelatedness" of an object by the pixel distance between the occurred perturbation and the object. Triggering errors in prediction while satisfying two objectives can be formulated as a multi-objective optimization problem where we utilize genetic algorithms to guide the search. The result successfully demonstrates that (invisible) perturbations on the right part of the image can drastically change the outcome of object detection on the left. An extensive evaluation reaffirms our conjecture that transformer-based object detection networks are more susceptible to butterfly effects in comparison to single-stage object detection networks such as YOLOv5.
Safety Metrics and Losses for Object Detection in Autonomous Driving
Sep 21, 2022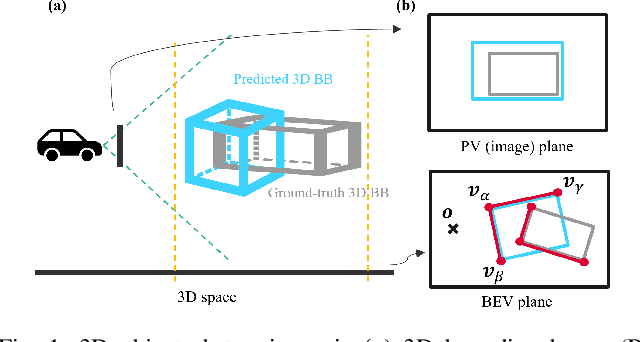
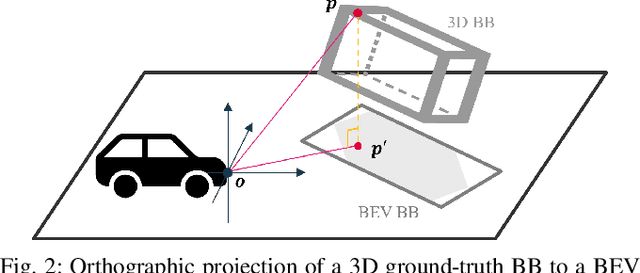
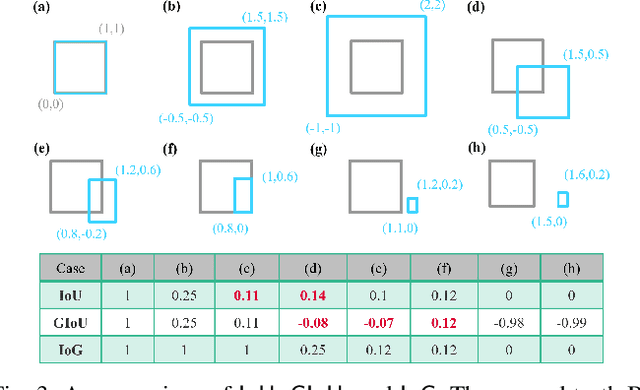
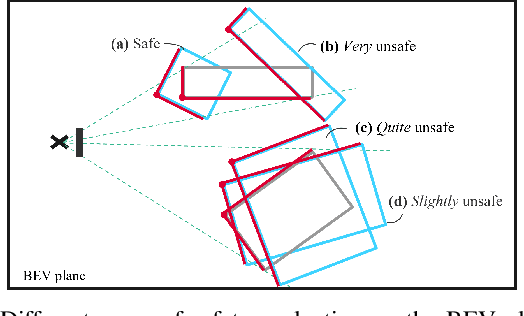
State-of-the-art object detectors have been shown effective in many applications. Usually, their performance is evaluated based on accuracy metrics such as mean Average Precision. In this paper, we consider a safety property of 3D object detectors in the context of Autonomous Driving (AD). In particular, we propose an essential safety requirement for object detectors in AD and formulate it into a specification. During the formulation, we find that abstracting 3D objects with projected 2D bounding boxes on the image and bird's-eye-view planes allows for a necessary and sufficient condition to the proposed safety requirement. We then leverage the analysis and derive qualitative and quantitative safety metrics based on the Intersection-over-Ground-Truth measure and a distance ratio between predictions and ground truths. Finally, for continual improvement, we formulate safety losses that can be used to optimize object detectors towards higher safety scores. Our experiments with public models on the MMDetection3D library and the nuScenes datasets demonstrate the validity of our consideration and proposals.
Prioritizing Corners in OoD Detectors via Symbolic String Manipulation
May 16, 2022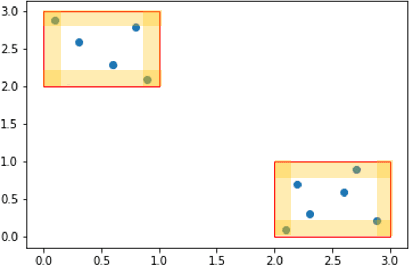

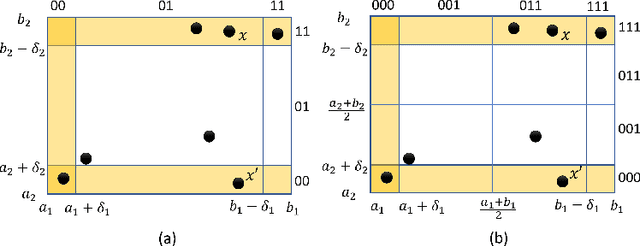
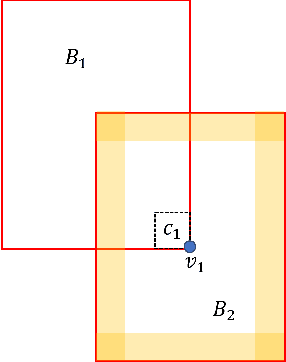
For safety assurance of deep neural networks (DNNs), out-of-distribution (OoD) monitoring techniques are essential as they filter spurious input that is distant from the training dataset. This paper studies the problem of systematically testing OoD monitors to avoid cases where an input data point is tested as in-distribution by the monitor, but the DNN produces spurious output predictions. We consider the definition of "in-distribution" characterized in the feature space by a union of hyperrectangles learned from the training dataset. Thus the testing is reduced to finding corners in hyperrectangles distant from the available training data in the feature space. Concretely, we encode the abstract location of every data point as a finite-length binary string, and the union of all binary strings is stored compactly using binary decision diagrams (BDDs). We demonstrate how to use BDDs to symbolically extract corners distant from all data points within the training set. Apart from test case generation, we explain how to use the proposed corners to fine-tune the DNN to ensure that it does not predict overly confidently. The result is evaluated over examples such as number and traffic sign recognition.
Unaligned but Safe -- Formally Compensating Performance Limitations for Imprecise 2D Object Detection
Feb 10, 2022



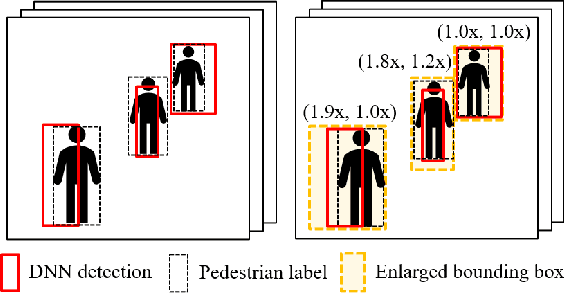
In this paper, we consider the imperfection within machine learning-based 2D object detection and its impact on safety. We address a special sub-type of performance limitations: the prediction bounding box cannot be perfectly aligned with the ground truth, but the computed Intersection-over-Union metric is always larger than a given threshold. Under such type of performance limitation, we formally prove the minimum required bounding box enlargement factor to cover the ground truth. We then demonstrate that the factor can be mathematically adjusted to a smaller value, provided that the motion planner takes a fixed-length buffer in making its decisions. Finally, observing the difference between an empirically measured enlargement factor and our formally derived worst-case enlargement factor offers an interesting connection between the quantitative evidence (demonstrated by statistics) and the qualitative evidence (demonstrated by worst-case analysis).
Robustness Verification for Attention Networks using Mixed Integer Programming
Feb 08, 2022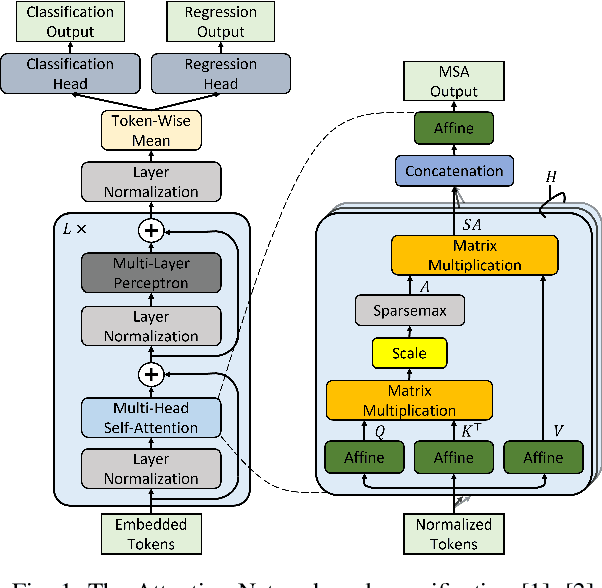
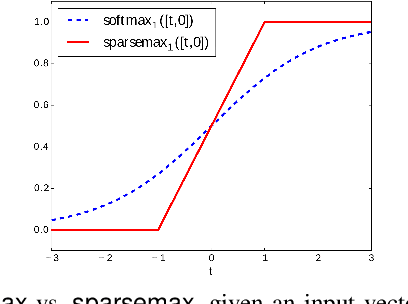
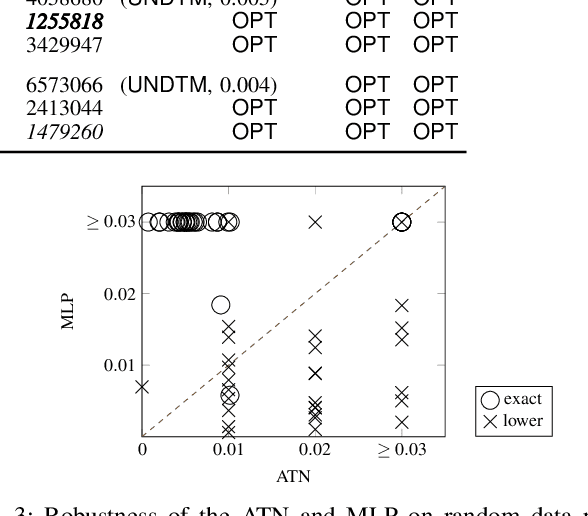
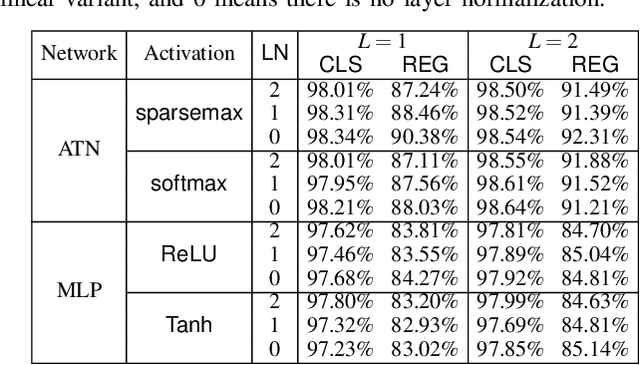
Attention networks such as transformers have been shown powerful in many applications ranging from natural language processing to object recognition. This paper further considers their robustness properties from both theoretical and empirical perspectives. Theoretically, we formulate a variant of attention networks containing linearized layer normalization and sparsemax activation, and reduce its robustness verification to a Mixed Integer Programming problem. Apart from a na\"ive encoding, we derive tight intervals from admissible perturbation regions and examine several heuristics to speed up the verification process. More specifically, we find a novel bounding technique for sparsemax activation, which is also applicable to softmax activation in general neural networks. Empirically, we evaluate our proposed techniques with a case study on lane departure warning and demonstrate a performance gain of approximately an order of magnitude. Furthermore, although attention networks typically deliver higher accuracy than general neural networks, contrasting its robustness against a similar-sized multi-layer perceptron surprisingly shows that they are not necessarily more robust.
Logically Sound Arguments for the Effectiveness of ML Safety Measures
Nov 04, 2021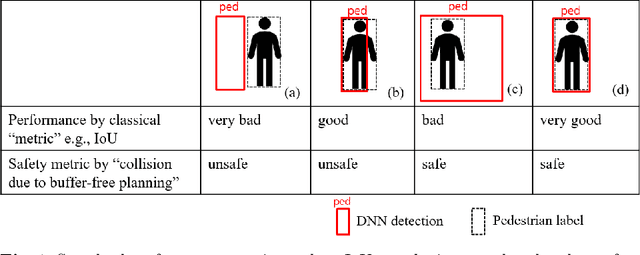


We investigate the issues of achieving sufficient rigor in the arguments for the safety of machine learning functions. By considering the known weaknesses of DNN-based 2D bounding box detection algorithms, we sharpen the metric of imprecise pedestrian localization by associating it with the safety goal. The sharpening leads to introducing a conservative post-processor after the standard non-max-suppression as a counter-measure. We then propose a semi-formal assurance case for arguing the effectiveness of the post-processor, which is further translated into formal proof obligations for demonstrating the soundness of the arguments. Applying theorem proving not only discovers the need to introduce missing claims and mathematical concepts but also reveals the limitation of Dempster-Shafer's rules used in semi-formal argumentation.
ComOpT: Combination and Optimization for Testing Autonomous Driving Systems
Oct 02, 2021



ComOpT is an open-source research tool for coverage-driven testing of autonomous driving systems, focusing on planning and control. Starting with (i) a meta-model characterizing discrete conditions to be considered and (ii) constraints specifying the impossibility of certain combinations, ComOpT first generates constraint-feasible abstract scenarios while maximally increasing the coverage of k-way combinatorial testing. Each abstract scenario can be viewed as a conceptual equivalence class, which is then instantiated into multiple concrete scenarios by (1) randomly picking one local map that fulfills the specified geographical condition, and (2) assigning all actors accordingly with parameters within the range. Finally, ComOpT evaluates each concrete scenario against a set of KPIs and performs local scenario variation via spawning a new agent that might lead to a collision at designated points. We use ComOpT to test the Apollo~6 autonomous driving software stack. ComOpT can generate highly diversified scenarios with limited test budgets while uncovering problematic situations such as inabilities to make simple right turns, uncomfortable accelerations, and dangerous driving patterns. ComOpT participated in the 2021 IEEE AI Autonomous Vehicle Testing Challenge and won first place among more than 110 contending teams.
Safety Metrics for Semantic Segmentation in Autonomous Driving
May 21, 2021
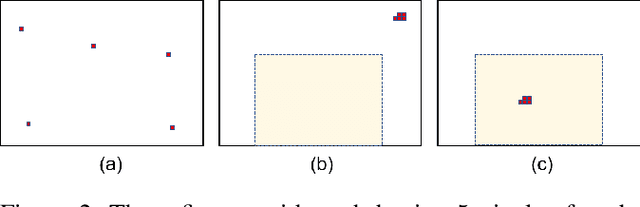
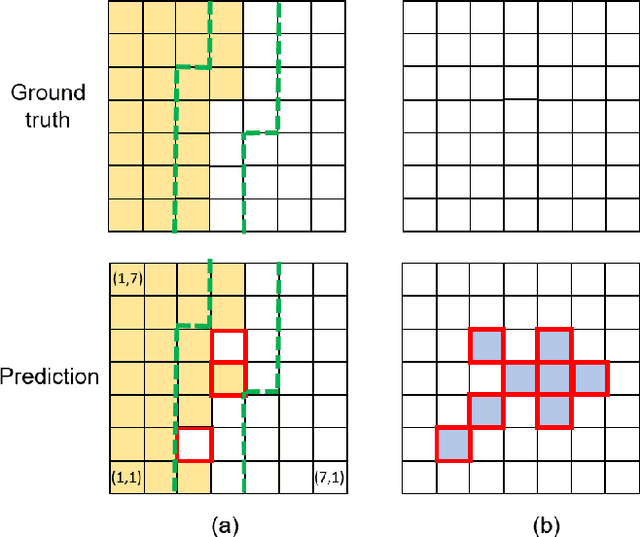
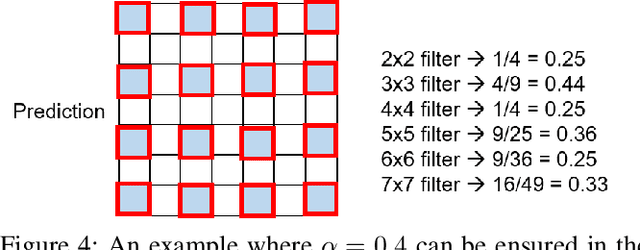
Within the context of autonomous driving, safety-related metrics for deep neural networks have been widely studied for image classification and object detection. In this paper, we further consider safety-aware correctness and robustness metrics specialized for semantic segmentation. The novelty of our proposal is to move beyond pixel-level metrics: Given two images with each having N pixels being class-flipped, the designed metrics should, depending on the clustering of pixels being class-flipped or the location of occurrence, reflect a different level of safety criticality. The result evaluated on an autonomous driving dataset demonstrates the validity and practicality of our proposed methodology.
Monitoring Object Detection Abnormalities via Data-Label and Post-Algorithm Abstractions
Mar 29, 2021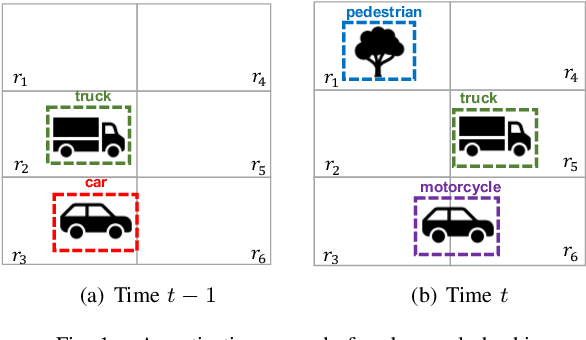
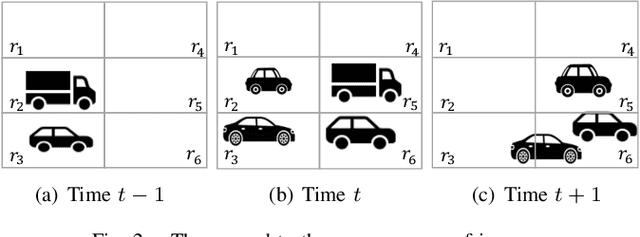
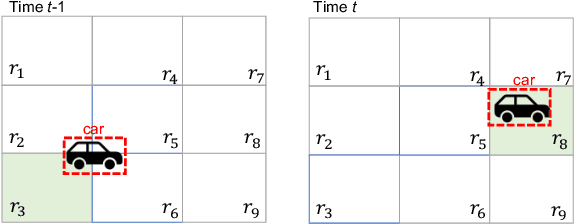
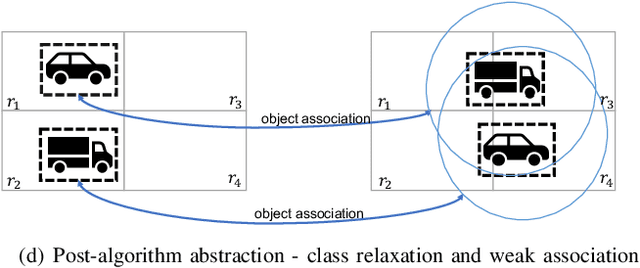
While object detection modules are essential functionalities for any autonomous vehicle, the performance of such modules that are implemented using deep neural networks can be, in many cases, unreliable. In this paper, we develop abstraction-based monitoring as a logical framework for filtering potentially erroneous detection results. Concretely, we consider two types of abstraction, namely data-label abstraction and post-algorithm abstraction. Operated on the training dataset, the construction of data-label abstraction iterates each input, aggregates region-wise information over its associated labels, and stores the vector under a finite history length. Post-algorithm abstraction builds an abstract transformer for the tracking algorithm. Elements being associated together by the abstract transformer can be checked against consistency over their original values. We have implemented the overall framework to a research prototype and validated it using publicly available object detection datasets.
Testing Autonomous Systems with Believed Equivalence Refinement
Mar 08, 2021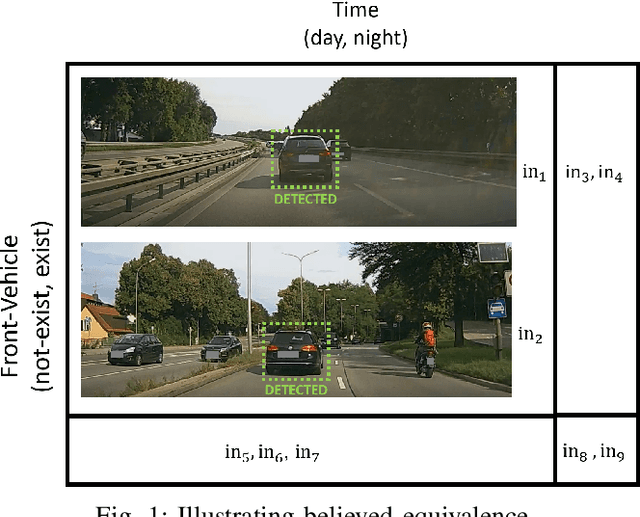
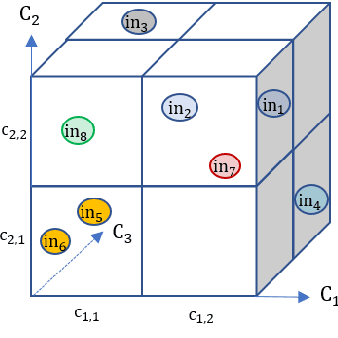
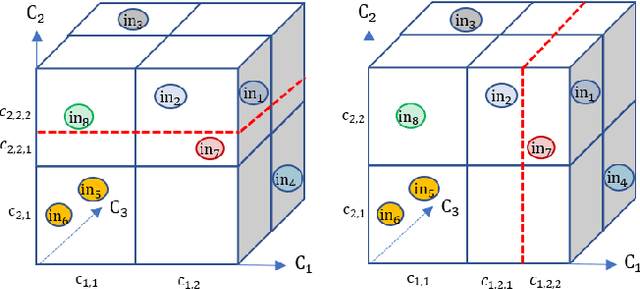

Continuous engineering of autonomous driving functions commonly requires deploying vehicles in road testing to obtain inputs that cause problematic decisions. Although the discovery leads to producing an improved system, it also challenges the foundation of testing using equivalence classes and the associated relative test coverage criterion. In this paper, we propose believed equivalence, where the establishment of an equivalence class is initially based on expert belief and is subject to a set of available test cases having a consistent valuation. Upon a newly encountered test case that breaks the consistency, one may need to refine the established categorization in order to split the originally believed equivalence into two. Finally, we focus on modules implemented using deep neural networks where every category partitions an input over the real domain. We establish new equivalence classes by guiding the new test cases following directions suggested by its k-nearest neighbors, complemented by local robustness testing. The concept is demonstrated in a lane-keeping assist module indicating the potential of our proposed approach.