 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcedure Planning in Instructional Videos
Jul 02, 2019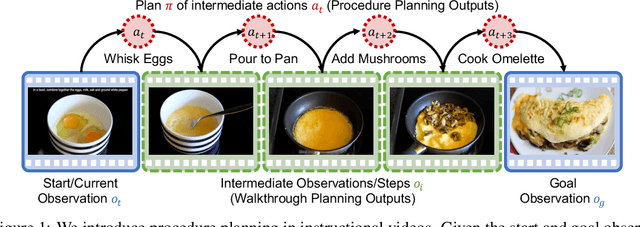
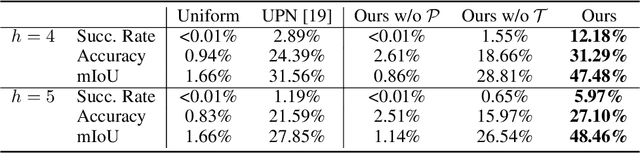
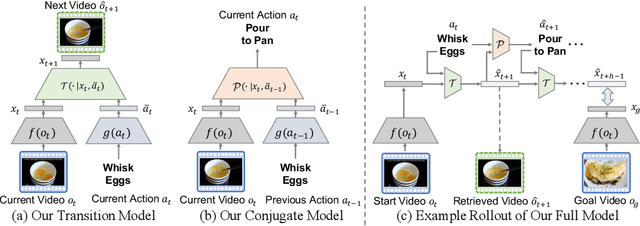
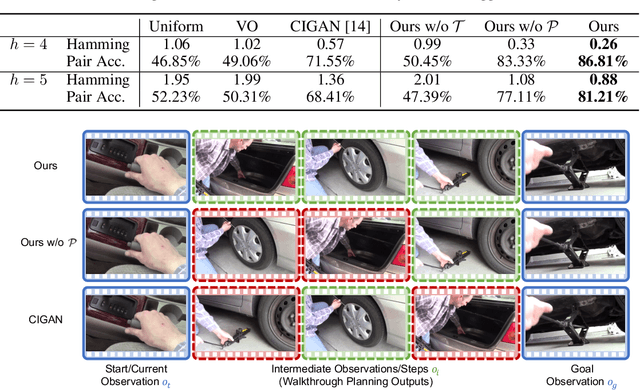
We propose a new challenging task: procedure planning in instructional videos. Unlike existing planning problems, where both the state and the action spaces are well-defined, the key challenge of planning in instructional videos is that both the state and the action spaces are open-vocabulary. We address this challenge with latent space planning, where we propose to explicitly leverage the constraints imposed by the conjugate relationships between states and actions in a learned plannable latent space. We evaluate both procedure planning and walkthrough planning on large-scale real-world instructional videos. Our experiments show that we are able to learn plannable semantic representations without explicit supervision. This enables sequential reasoning on real-world videos and leads to stronger generalization compared to existing planning approaches and neural network policies.
Few-Shot Video Classification via Temporal Alignment
Jun 27, 2019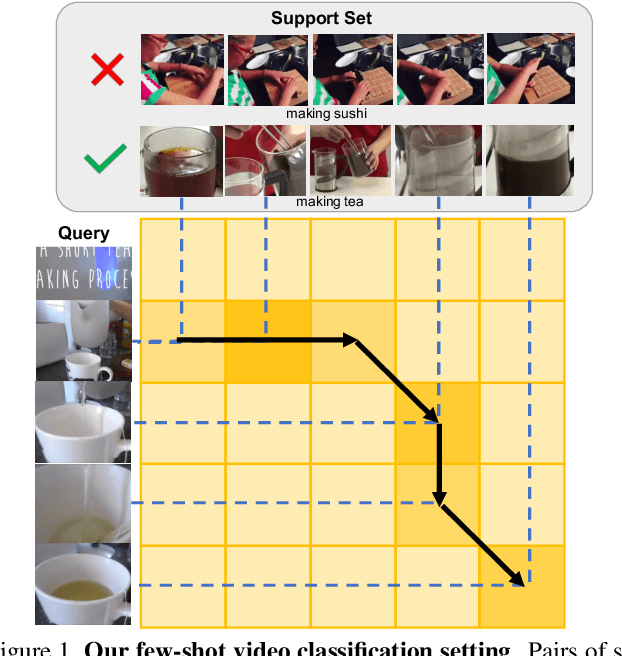
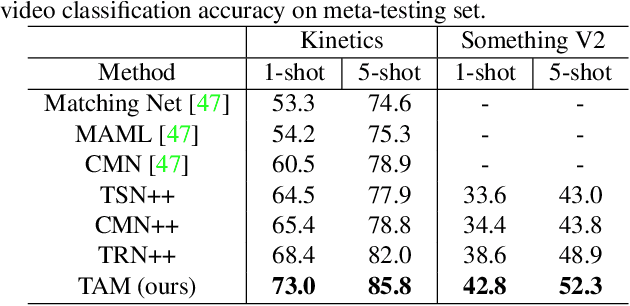
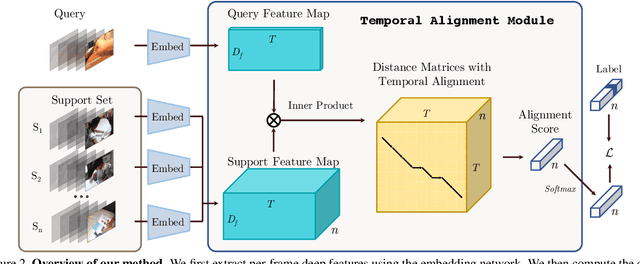
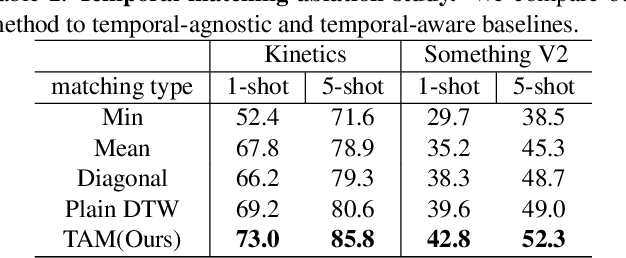
There is a growing interest in learning a model which could recognize novel classes with only a few labeled examples. In this paper, we propose Temporal Alignment Module (TAM), a novel few-shot learning framework that can learn to classify a previous unseen video. While most previous works neglect long-term temporal ordering information, our proposed model explicitly leverages the temporal ordering information in video data through temporal alignment. This leads to strong data-efficiency for few-shot learning. In concrete, TAM calculates the distance value of query video with respect to novel class proxies by averaging the per frame distances along its alignment path. We introduce continuous relaxation to TAM so the model can be learned in an end-to-end fashion to directly optimize the few-shot learning objective. We evaluate TAM on two challenging real-world datasets, Kinetics and Something-Something-V2, and show that our model leads to significant improvement of few-shot video classification over a wide range of competitive baselines.
D${}^3$TW: Discriminative Differentiable Dynamic Time Warping for Weakly Supervised Action Alignment and Segmentation
Jan 09, 2019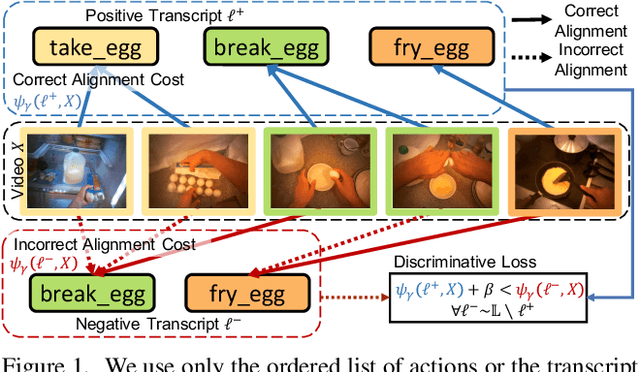
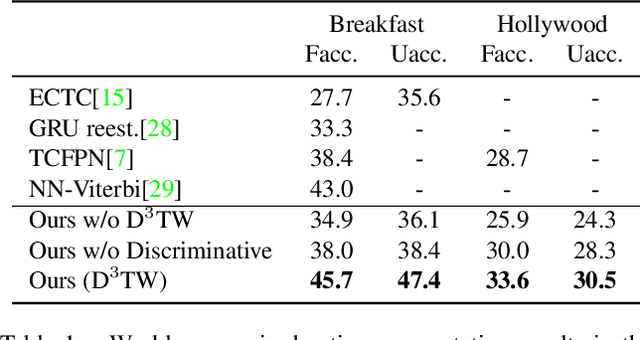
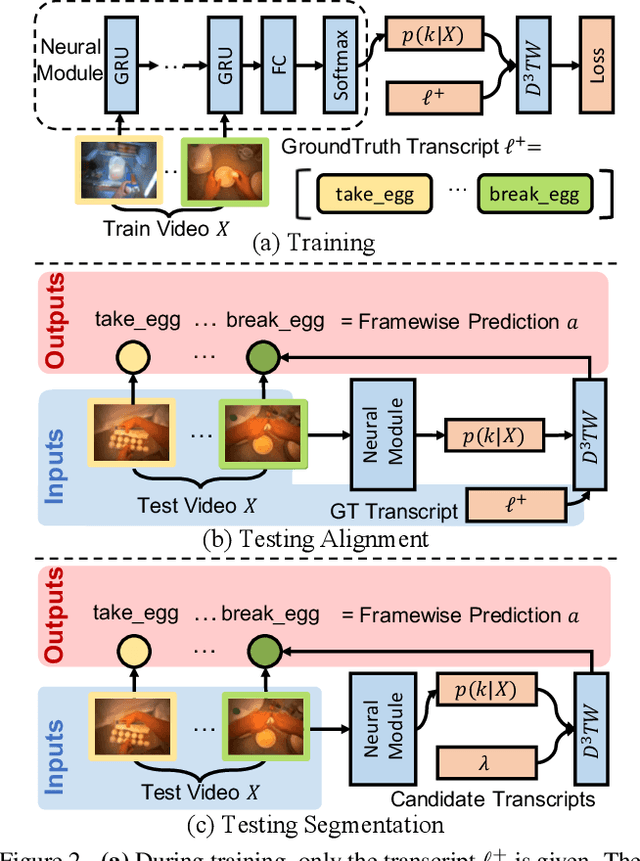
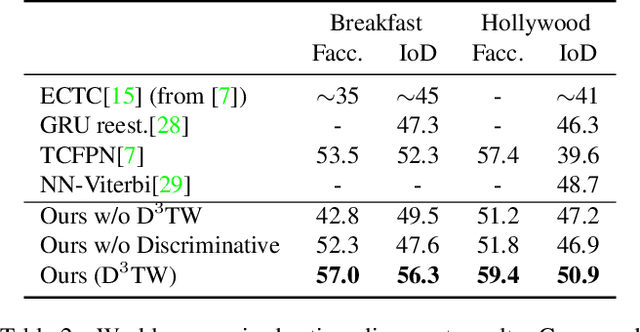
We address weakly-supervised action alignment and segmentation in videos, where only the order of occurring actions is available during training. We propose Discriminative Differentiable Dynamic Time Warping (D${}^3$TW), which is the first discriminative model for weak ordering supervision. This allows us to bypass the degenerated sequence problem usually encountered in previous work. The key technical challenge for discriminative modeling with weak-supervision is that the loss function of the ordering supervision is usually formulated using dynamic programming and is thus not differentiable. We address this challenge by continuous relaxation of the min-operator in dynamic programming and extend the DTW alignment loss to be differentiable. The proposed D${}^3$TW innovatively solves sequence alignment with discriminative modeling and end-to-end training, which substantially improves the performance in weakly supervised action alignment and segmentation tasks. We show that our model outperforms the current state-of-the-art across three evaluation metrics in two challenging datasets.