 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobot-Assisted Group Tours for Blind People
Feb 04, 2026Group interactions are essential to social functioning, yet effective engagement relies on the ability to recognize and interpret visual cues, making such engagement a significant challenge for blind people. In this paper, we investigate how a mobile robot can support group interactions for blind people. We used the scenario of a guided tour with mixed-visual groups involving blind and sighted visitors. Based on insights from an interview study with blind people (n=5) and museum experts (n=5), we designed and prototyped a robotic system that supported blind visitors to join group tours. We conducted a field study in a science museum where each blind participant (n=8) joined a group tour with one guide and two sighted participants (n=8). Findings indicated users' sense of safety from the robot's navigational support, concerns in the group participation, and preferences for obtaining environmental information. We present design implications for future robotic systems to support blind people's mixed-visual group participation.
How Does Delegation in Social Interaction Evolve Over Time? Navigation with a Robot for Blind People
Jan 27, 2026Autonomy and independent navigation are vital to daily life but remain challenging for individuals with blindness. Robotic systems can enhance mobility and confidence by providing intelligent navigation assistance. However, fully autonomous systems may reduce users' sense of control, even when they wish to remain actively involved. Although collaboration between user and robot has been recognized as important, little is known about how perceptions of this relationship change with repeated use. We present a repeated exposure study with six blind participants who interacted with a navigation-assistive robot in a real-world museum. Participants completed tasks such as navigating crowds, approaching lines, and encountering obstacles. Findings show that participants refined their strategies over time, developing clearer preferences about when to rely on the robot versus act independently. This work provides insights into how strategies and preferences evolve with repeated interaction and offers design implications for robots that adapt to user needs over time.
Beyond Omakase: Designing Shared Control for Navigation Robots with Blind People
Mar 31, 2025



Autonomous navigation robots can increase the independence of blind people but often limit user control, following what is called in Japanese an "omakase" approach where decisions are left to the robot. This research investigates ways to enhance user control in social robot navigation, based on two studies conducted with blind participants. The first study, involving structured interviews (N=14), identified crowded spaces as key areas with significant social challenges. The second study (N=13) explored navigation tasks with an autonomous robot in these environments and identified design strategies across different modes of autonomy. Participants preferred an active role, termed the "boss" mode, where they managed crowd interactions, while the "monitor" mode helped them assess the environment, negotiate movements, and interact with the robot. These findings highlight the importance of shared control and user involvement for blind users, offering valuable insights for designing future social navigation robots.
"We are at the mercy of others' opinion": Supporting Blind People in Recreational Window Shopping with AI-infused Technology
May 10, 2024


Engaging in recreational activities in public spaces poses challenges for blind people, often involving dependency on sighted help. Window shopping is a key recreational activity that remains inaccessible. In this paper, we investigate the information needs, challenges, and current approaches blind people have to recreational window shopping to inform the design of existing wayfinding and navigation technology for supporting blind shoppers in exploration and serendipitous discovery. We conduct a formative study with a total of 18 blind participants that include both focus groups (N=8) and interviews for requirements analysis (N=10). We find that there is a desire for push notifications of promotional information and pull notifications about shops of interest such as the targeted audience of a brand. Information about obstacles and points-of-interest required customization depending on one's mobility aid as well as presence of a crowd, children, and wheelchair users. We translate these findings into specific information modalities and rendering in the context of two existing AI-infused assistive applications: NavCog (a turn-by-turn navigation app) and Cabot (a navigation robot).
Pedestrian Detection with Wearable Cameras for the Blind: A Two-way Perspective
Mar 26, 2020

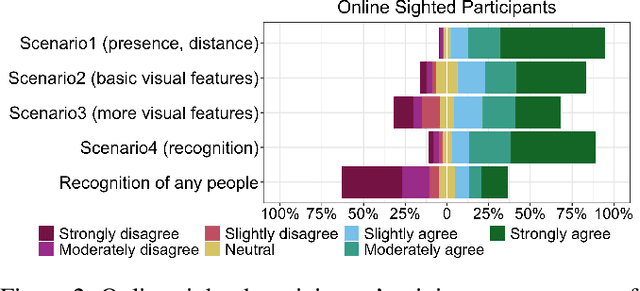
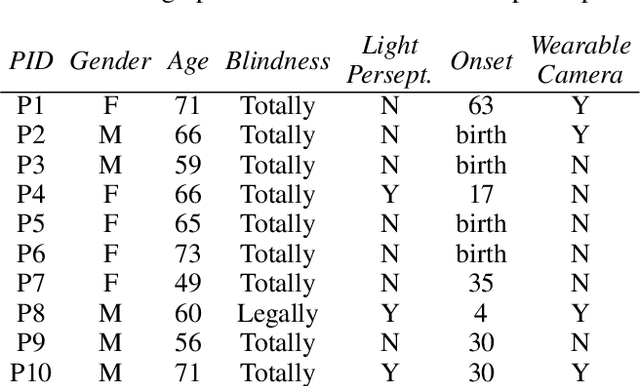
Blind people have limited access to information about their surroundings, which is important for ensuring one's safety, managing social interactions, and identifying approaching pedestrians. With advances in computer vision, wearable cameras can provide equitable access to such information. However, the always-on nature of these assistive technologies poses privacy concerns for parties that may get recorded. We explore this tension from both perspectives, those of sighted passersby and blind users, taking into account camera visibility, in-person versus remote experience, and extracted visual information. We conduct two studies: an online survey with MTurkers (N=206) and an in-person experience study between pairs of blind (N=10) and sighted (N=40) participants, where blind participants wear a working prototype for pedestrian detection and pass by sighted participants. Our results suggest that both of the perspectives of users and bystanders and the several factors mentioned above need to be carefully considered to mitigate potential social tensions.
Personalized Dynamics Models for Adaptive Assistive Navigation Systems
Oct 08, 2018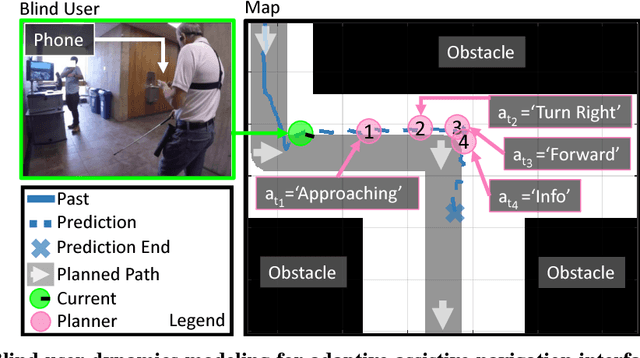

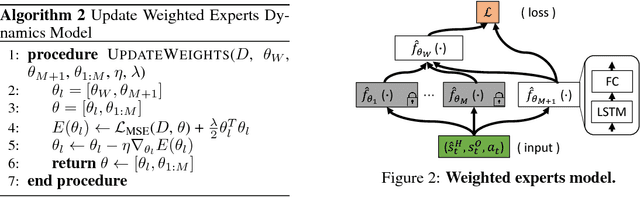
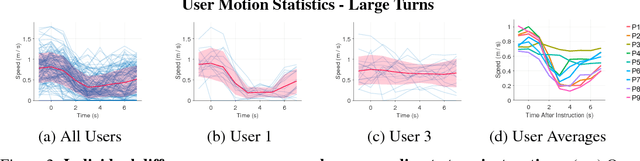
Consider an assistive system that guides visually impaired users through speech and haptic feedback to their destination. Existing robotic and ubiquitous navigation technologies (e.g., portable, ground, or wearable systems) often operate in a generic, user-agnostic manner. However, to minimize confusion and navigation errors, our real-world analysis reveals a crucial need to adapt the instructional guidance across different end-users with diverse mobility skills. To address this practical issue in scalable system design, we propose a novel model-based reinforcement learning framework for personalizing the system-user interaction experience. When incrementally adapting the system to new users, we propose to use a weighted experts model for addressing data-efficiency limitations in transfer learning with deep models. A real-world dataset of navigation by blind users is used to show that the proposed approach allows for (1) more accurate long-term human behavior prediction (up to 20 seconds into the future) through improved reasoning over personal mobility characteristics, interaction with surrounding obstacles, and the current navigation goal, and (2) quick adaptation at the onset of learning, when data is limited.