 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Critical Point (CritPt) of AI Reasoning: a Frontier Physics Research Benchmark
Oct 01, 2025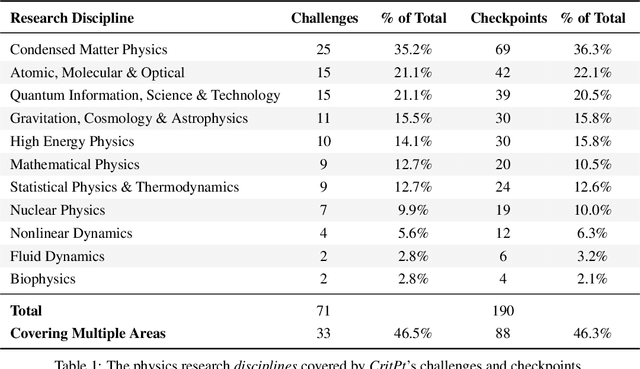



While large language models (LLMs) with reasoning capabilities are progressing rapidly on high-school math competitions and coding, can they reason effectively through complex, open-ended challenges found in frontier physics research? And crucially, what kinds of reasoning tasks do physicists want LLMs to assist with? To address these questions, we present the CritPt (Complex Research using Integrated Thinking - Physics Test, pronounced "critical point"), the first benchmark designed to test LLMs on unpublished, research-level reasoning tasks that broadly covers modern physics research areas, including condensed matter, quantum physics, atomic, molecular & optical physics, astrophysics, high energy physics, mathematical physics, statistical physics, nuclear physics, nonlinear dynamics, fluid dynamics and biophysics. CritPt consists of 71 composite research challenges designed to simulate full-scale research projects at the entry level, which are also decomposed to 190 simpler checkpoint tasks for more fine-grained insights. All problems are newly created by 50+ active physics researchers based on their own research. Every problem is hand-curated to admit a guess-resistant and machine-verifiable answer and is evaluated by an automated grading pipeline heavily customized for advanced physics-specific output formats. We find that while current state-of-the-art LLMs show early promise on isolated checkpoints, they remain far from being able to reliably solve full research-scale challenges: the best average accuracy among base models is only 4.0% , achieved by GPT-5 (high), moderately rising to around 10% when equipped with coding tools. Through the realistic yet standardized evaluation offered by CritPt, we highlight a large disconnect between current model capabilities and realistic physics research demands, offering a foundation to guide the development of scientifically grounded AI tools.
Quantifying Fairness in LLMs Beyond Tokens: A Semantic and Statistical Perspective
Jun 23, 2025Large Language Models (LLMs) often generate responses with inherent biases, undermining their reliability in real-world applications. Existing evaluation methods often overlook biases in long-form responses and the intrinsic variability of LLM outputs. To address these challenges, we propose FiSCo(Fine-grained Semantic Computation), a novel statistical framework to evaluate group-level fairness in LLMs by detecting subtle semantic differences in long-form responses across demographic groups. Unlike prior work focusing on sentiment or token-level comparisons, FiSCo goes beyond surface-level analysis by operating at the claim level, leveraging entailment checks to assess the consistency of meaning across responses. We decompose model outputs into semantically distinct claims and apply statistical hypothesis testing to compare inter- and intra-group similarities, enabling robust detection of subtle biases. We formalize a new group counterfactual fairness definition and validate FiSCo on both synthetic and human-annotated datasets spanning gender, race, and age. Experiments show that FiSco more reliably identifies nuanced biases while reducing the impact of stochastic LLM variability, outperforming various evaluation metrics.
Mitigating Selection Bias with Node Pruning and Auxiliary Options
Sep 27, 2024



Large language models (LLMs) often show unwarranted preference for certain choice options when responding to multiple-choice questions, posing significant reliability concerns in LLM-automated systems. To mitigate this selection bias problem, previous solutions utilized debiasing methods to adjust the model's input and/or output. Our work, in contrast, investigates the model's internal representation of the selection bias. Specifically, we introduce a novel debiasing approach, Bias Node Pruning (BNP), which eliminates the linear layer parameters that contribute to the bias. Furthermore, we present Auxiliary Option Injection (AOI), a simple yet effective input modification technique for debiasing, which is compatible even with black-box LLMs. To provide a more systematic evaluation of selection bias, we review existing metrics and introduce Choice Kullback-Leibler Divergence (CKLD), which addresses the insensitivity of the commonly used metrics to label imbalance. Experiments show that our methods are robust and adaptable across various datasets when applied to three LLMs.