 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRephrasing the Reference for Non-Autoregressive Machine Translation
Nov 30, 2022



Non-autoregressive neural machine translation (NAT) models suffer from the multi-modality problem that there may exist multiple possible translations of a source sentence, so the reference sentence may be inappropriate for the training when the NAT output is closer to other translations. In response to this problem, we introduce a rephraser to provide a better training target for NAT by rephrasing the reference sentence according to the NAT output. As we train NAT based on the rephraser output rather than the reference sentence, the rephraser output should fit well with the NAT output and not deviate too far from the reference, which can be quantified as reward functions and optimized by reinforcement learning. Experiments on major WMT benchmarks and NAT baselines show that our approach consistently improves the translation quality of NAT. Specifically, our best variant achieves comparable performance to the autoregressive Transformer, while being 14.7 times more efficient in inference.
Viterbi Decoding of Directed Acyclic Transformer for Non-Autoregressive Machine Translation
Oct 11, 2022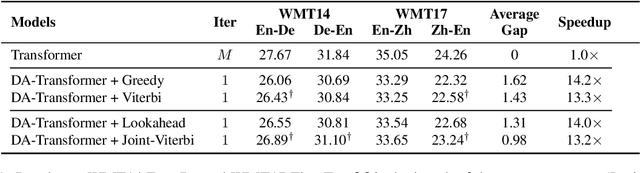
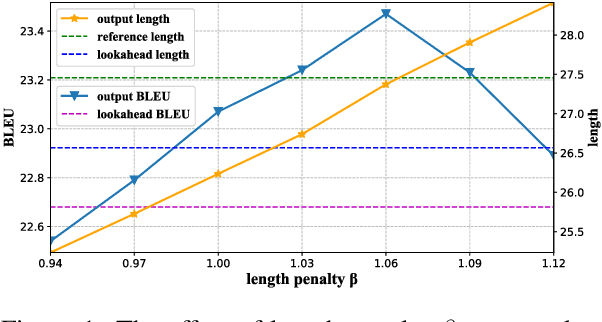
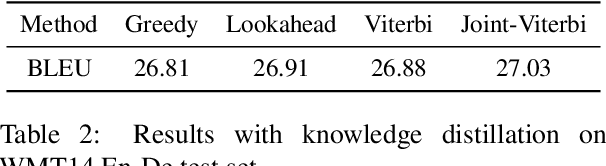
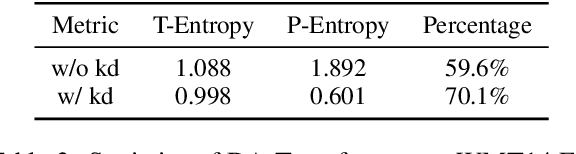
Non-autoregressive models achieve significant decoding speedup in neural machine translation but lack the ability to capture sequential dependency. Directed Acyclic Transformer (DA-Transformer) was recently proposed to model sequential dependency with a directed acyclic graph. Consequently, it has to apply a sequential decision process at inference time, which harms the global translation accuracy. In this paper, we present a Viterbi decoding framework for DA-Transformer, which guarantees to find the joint optimal solution for the translation and decoding path under any length constraint. Experimental results demonstrate that our approach consistently improves the performance of DA-Transformer while maintaining a similar decoding speedup.
Non-Monotonic Latent Alignments for CTC-Based Non-Autoregressive Machine Translation
Oct 08, 2022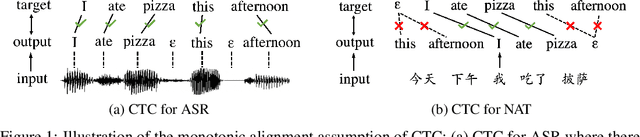
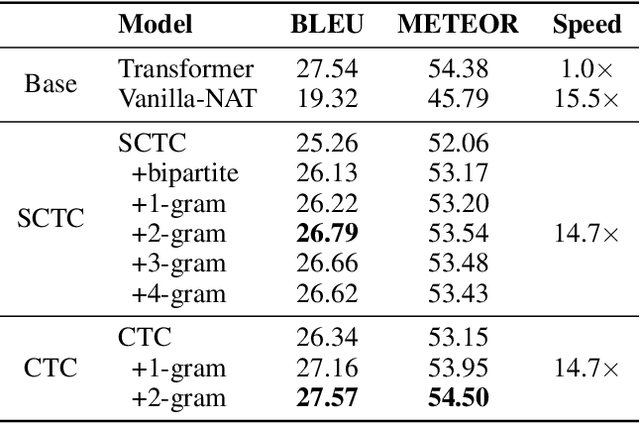
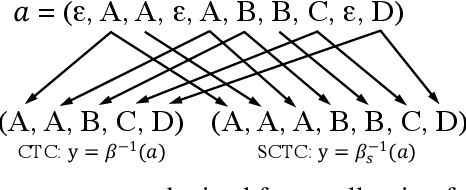
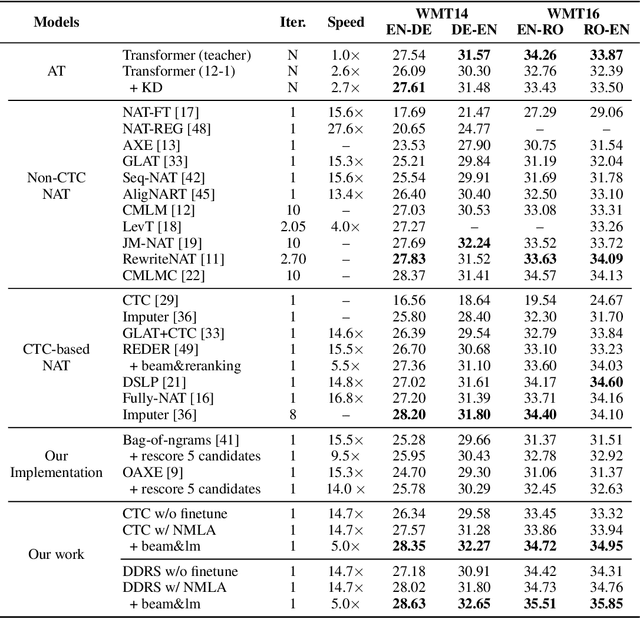
Non-autoregressive translation (NAT) models are typically trained with the cross-entropy loss, which forces the model outputs to be aligned verbatim with the target sentence and will highly penalize small shifts in word positions. Latent alignment models relax the explicit alignment by marginalizing out all monotonic latent alignments with the CTC loss. However, they cannot handle non-monotonic alignments, which is non-negligible as there is typically global word reordering in machine translation. In this work, we explore non-monotonic latent alignments for NAT. We extend the alignment space to non-monotonic alignments to allow for the global word reordering and further consider all alignments that overlap with the target sentence. We non-monotonically match the alignments to the target sentence and train the latent alignment model to maximize the F1 score of non-monotonic matching. Extensive experiments on major WMT benchmarks show that our method substantially improves the translation performance of CTC-based models. Our best model achieves 30.06 BLEU on WMT14 En-De with only one-iteration decoding, closing the gap between non-autoregressive and autoregressive models.
One Reference Is Not Enough: Diverse Distillation with Reference Selection for Non-Autoregressive Translation
May 28, 2022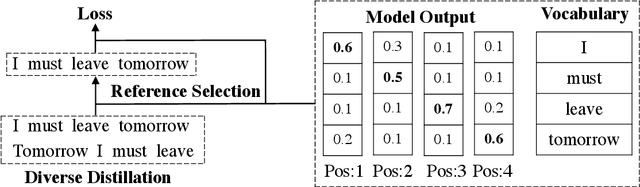

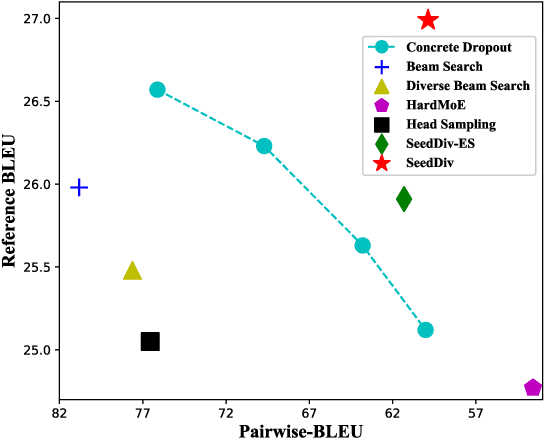
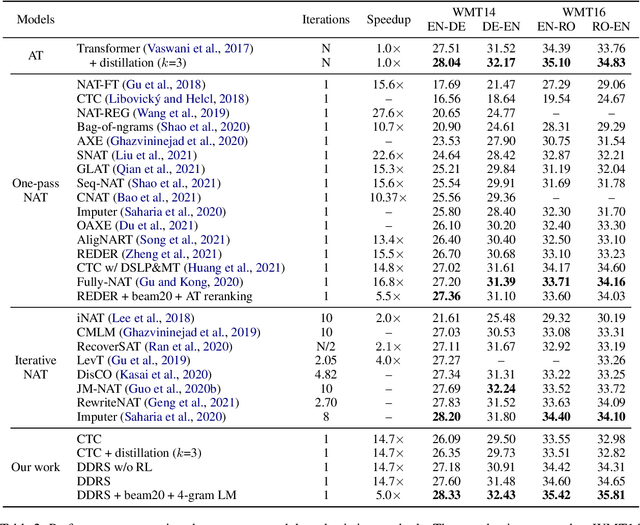
Non-autoregressive neural machine translation (NAT) suffers from the multi-modality problem: the source sentence may have multiple correct translations, but the loss function is calculated only according to the reference sentence. Sequence-level knowledge distillation makes the target more deterministic by replacing the target with the output from an autoregressive model. However, the multi-modality problem in the distilled dataset is still nonnegligible. Furthermore, learning from a specific teacher limits the upper bound of the model capability, restricting the potential of NAT models. In this paper, we argue that one reference is not enough and propose diverse distillation with reference selection (DDRS) for NAT. Specifically, we first propose a method called SeedDiv for diverse machine translation, which enables us to generate a dataset containing multiple high-quality reference translations for each source sentence. During the training, we compare the NAT output with all references and select the one that best fits the NAT output to train the model. Experiments on widely-used machine translation benchmarks demonstrate the effectiveness of DDRS, which achieves 29.82 BLEU with only one decoding pass on WMT14 En-De, improving the state-of-the-art performance for NAT by over 1 BLEU. Source code: https://github.com/ictnlp/DDRS-NAT
Overcoming Catastrophic Forgetting beyond Continual Learning: Balanced Training for Neural Machine Translation
Mar 18, 2022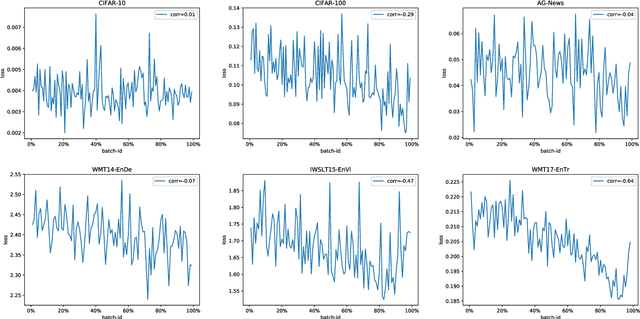
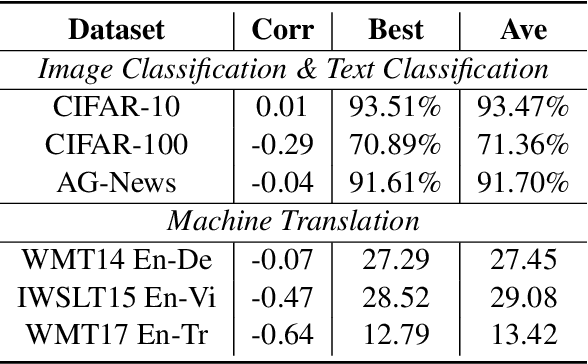

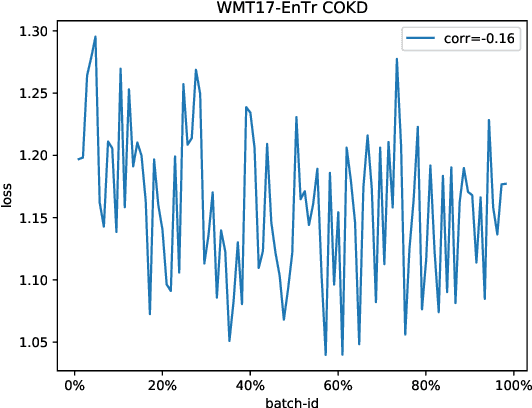
Neural networks tend to gradually forget the previously learned knowledge when learning multiple tasks sequentially from dynamic data distributions. This problem is called \textit{catastrophic forgetting}, which is a fundamental challenge in the continual learning of neural networks. In this work, we observe that catastrophic forgetting not only occurs in continual learning but also affects the traditional static training. Neural networks, especially neural machine translation models, suffer from catastrophic forgetting even if they learn from a static training set. To be specific, the final model pays imbalanced attention to training samples, where recently exposed samples attract more attention than earlier samples. The underlying cause is that training samples do not get balanced training in each model update, so we name this problem \textit{imbalanced training}. To alleviate this problem, we propose Complementary Online Knowledge Distillation (COKD), which uses dynamically updated teacher models trained on specific data orders to iteratively provide complementary knowledge to the student model. Experimental results on multiple machine translation tasks show that our method successfully alleviates the problem of imbalanced training and achieves substantial improvements over strong baseline systems.
Sequence-Level Training for Non-Autoregressive Neural Machine Translation
Jun 15, 2021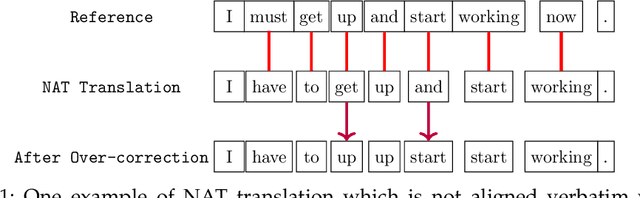


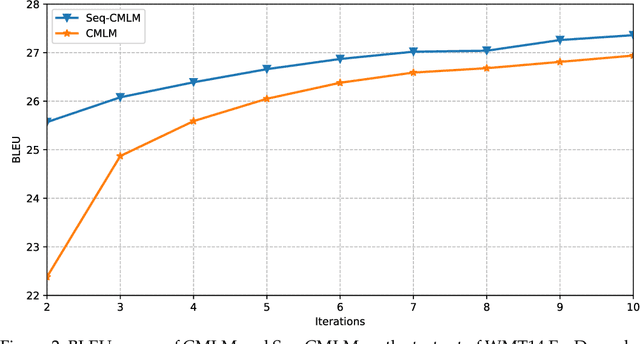
In recent years, Neural Machine Translation (NMT) has achieved notable results in various translation tasks. However, the word-by-word generation manner determined by the autoregressive mechanism leads to high translation latency of the NMT and restricts its low-latency applications. Non-Autoregressive Neural Machine Translation (NAT) removes the autoregressive mechanism and achieves significant decoding speedup through generating target words independently and simultaneously. Nevertheless, NAT still takes the word-level cross-entropy loss as the training objective, which is not optimal because the output of NAT cannot be properly evaluated due to the multimodality problem. In this paper, we propose using sequence-level training objectives to train NAT models, which evaluate the NAT outputs as a whole and correlates well with the real translation quality. Firstly, we propose training NAT models to optimize sequence-level evaluation metrics (e.g., BLEU) based on several novel reinforcement algorithms customized for NAT, which outperforms the conventional method by reducing the variance of gradient estimation. Secondly, we introduce a novel training objective for NAT models, which aims to minimize the Bag-of-Ngrams (BoN) difference between the model output and the reference sentence. The BoN training objective is differentiable and can be calculated efficiently without doing any approximations. Finally, we apply a three-stage training strategy to combine these two methods to train the NAT model. We validate our approach on four translation tasks (WMT14 En$\leftrightarrow$De, WMT16 En$\leftrightarrow$Ro), which shows that our approach largely outperforms NAT baselines and achieves remarkable performance on all translation tasks.
Guiding Teacher Forcing with Seer Forcing for Neural Machine Translation
Jun 12, 2021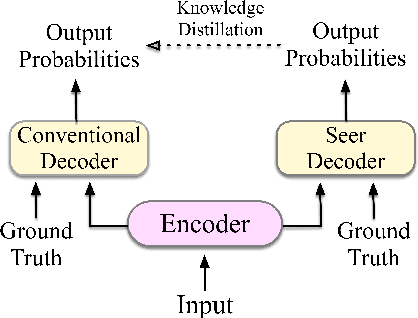
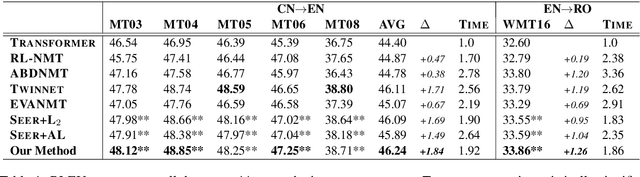
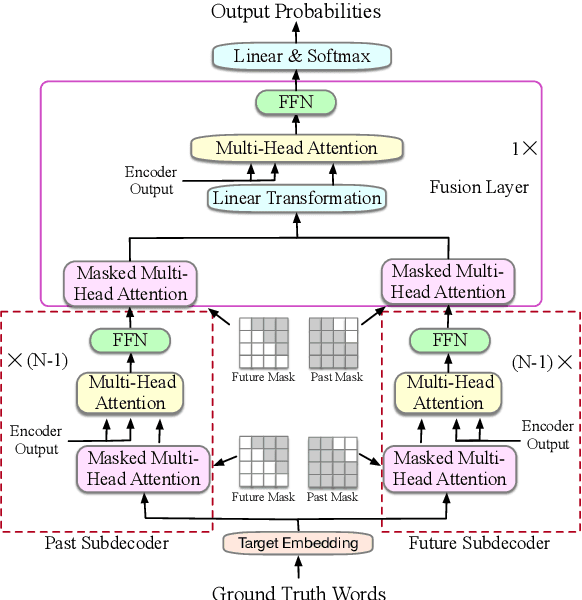
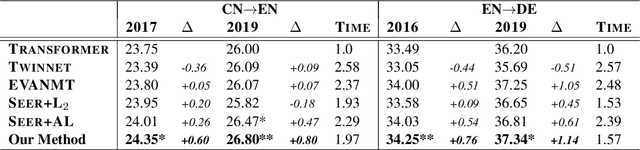
Although teacher forcing has become the main training paradigm for neural machine translation, it usually makes predictions only conditioned on past information, and hence lacks global planning for the future. To address this problem, we introduce another decoder, called seer decoder, into the encoder-decoder framework during training, which involves future information in target predictions. Meanwhile, we force the conventional decoder to simulate the behaviors of the seer decoder via knowledge distillation. In this way, at test the conventional decoder can perform like the seer decoder without the attendance of it. Experiment results on the Chinese-English, English-German and English-Romanian translation tasks show our method can outperform competitive baselines significantly and achieves greater improvements on the bigger data sets. Besides, the experiments also prove knowledge distillation the best way to transfer knowledge from the seer decoder to the conventional decoder compared to adversarial learning and L2 regularization.
Modeling Coverage for Non-Autoregressive Neural Machine Translation
Apr 24, 2021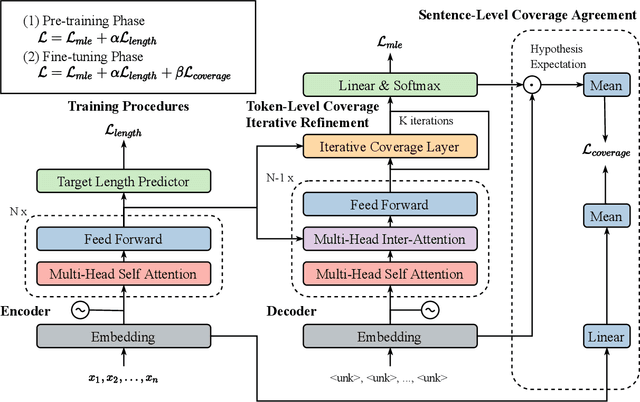
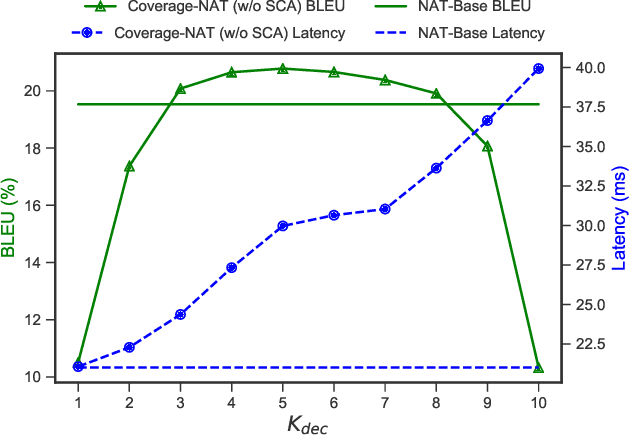
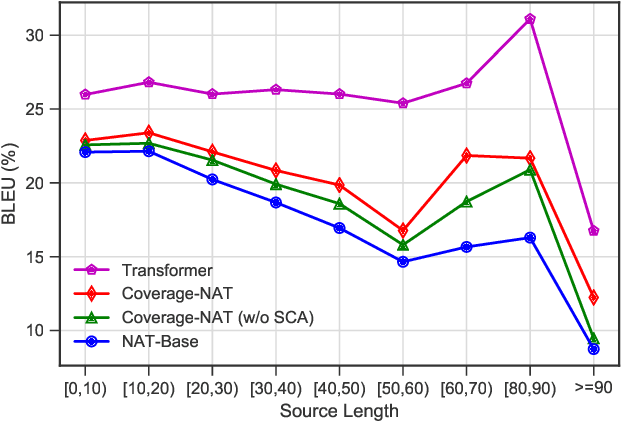
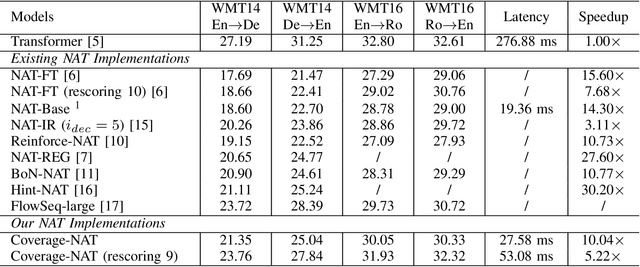
Non-Autoregressive Neural Machine Translation (NAT) has achieved significant inference speedup by generating all tokens simultaneously. Despite its high efficiency, NAT usually suffers from two kinds of translation errors: over-translation (e.g. repeated tokens) and under-translation (e.g. missing translations), which eventually limits the translation quality. In this paper, we argue that these issues of NAT can be addressed through coverage modeling, which has been proved to be useful in autoregressive decoding. We propose a novel Coverage-NAT to model the coverage information directly by a token-level coverage iterative refinement mechanism and a sentence-level coverage agreement, which can remind the model if a source token has been translated or not and improve the semantics consistency between the translation and the source, respectively. Experimental results on WMT14 En-De and WMT16 En-Ro translation tasks show that our method can alleviate those errors and achieve strong improvements over the baseline system.
Generating Diverse Translation from Model Distribution with Dropout
Oct 16, 2020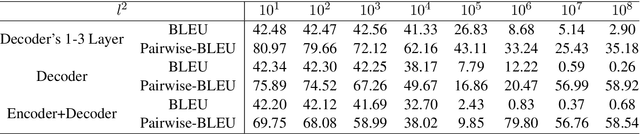
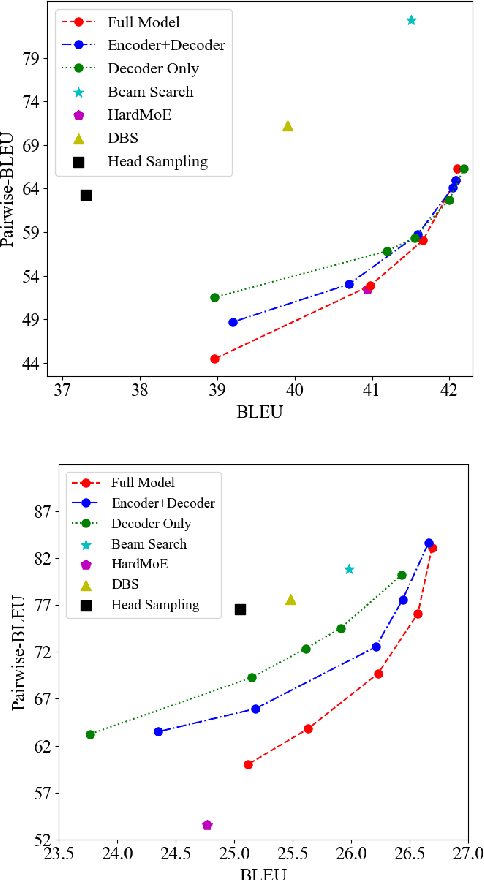

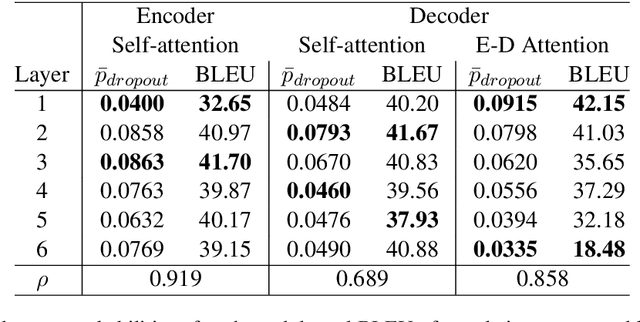
Despite the improvement of translation quality, neural machine translation (NMT) often suffers from the lack of diversity in its generation. In this paper, we propose to generate diverse translations by deriving a large number of possible models with Bayesian modelling and sampling models from them for inference. The possible models are obtained by applying concrete dropout to the NMT model and each of them has specific confidence for its prediction, which corresponds to a posterior model distribution under specific training data in the principle of Bayesian modeling. With variational inference, the posterior model distribution can be approximated with a variational distribution, from which the final models for inference are sampled. We conducted experiments on Chinese-English and English-German translation tasks and the results shows that our method makes a better trade-off between diversity and accuracy.
Modeling Fluency and Faithfulness for Diverse Neural Machine Translation
Nov 30, 2019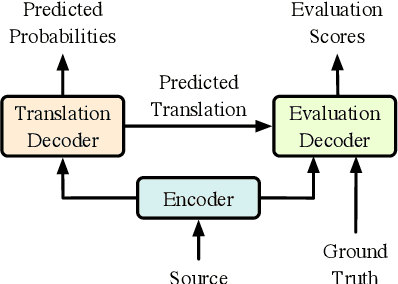

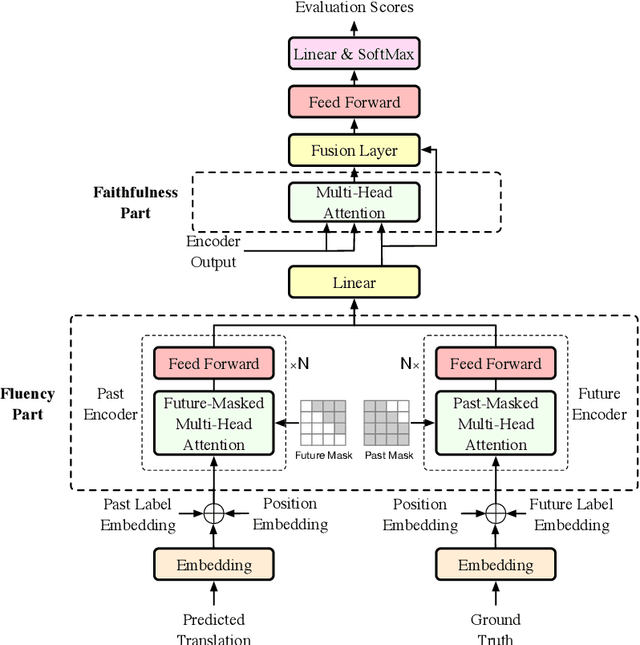
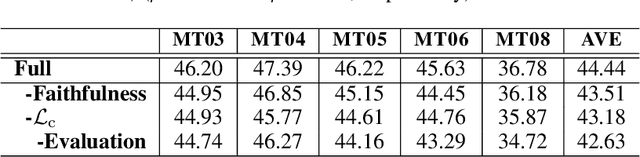
Neural machine translation models usually adopt the teacher forcing strategy for training which requires the predicted sequence matches ground truth word by word and forces the probability of each prediction to approach a 0-1 distribution. However, the strategy casts all the portion of the distribution to the ground truth word and ignores other words in the target vocabulary even when the ground truth word cannot dominate the distribution. To address the problem of teacher forcing, we propose a method to introduce an evaluation module to guide the distribution of the prediction. The evaluation module accesses each prediction from the perspectives of fluency and faithfulness to encourage the model to generate the word which has a fluent connection with its past and future translation and meanwhile tends to form a translation equivalent in meaning to the source. The experiments on multiple translation tasks show that our method can achieve significant improvements over strong baselines.