 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMapAgent: Trajectory-Constructed Memory-Augmented Planning for Mobile Task Automation
Jul 29, 2025



The recent advancement of autonomous agents powered by Large Language Models (LLMs) has demonstrated significant potential for automating tasks on mobile devices through graphical user interfaces (GUIs). Despite initial progress, these agents still face challenges when handling complex real-world tasks. These challenges arise from a lack of knowledge about real-life mobile applications in LLM-based agents, which may lead to ineffective task planning and even cause hallucinations. To address these challenges, we propose a novel LLM-based agent framework called MapAgent that leverages memory constructed from historical trajectories to augment current task planning. Specifically, we first propose a trajectory-based memory mechanism that transforms task execution trajectories into a reusable and structured page-memory database. Each page within a trajectory is extracted as a compact yet comprehensive snapshot, capturing both its UI layout and functional context. Secondly, we introduce a coarse-to-fine task planning approach that retrieves relevant pages from the memory database based on similarity and injects them into the LLM planner to compensate for potential deficiencies in understanding real-world app scenarios, thereby achieving more informed and context-aware task planning. Finally, planned tasks are transformed into executable actions through a task executor supported by a dual-LLM architecture, ensuring effective tracking of task progress. Experimental results in real-world scenarios demonstrate that MapAgent achieves superior performance to existing methods. The code will be open-sourced to support further research.
FedProf: Optimizing Federated Learning with Dynamic Data Profiling
Feb 02, 2021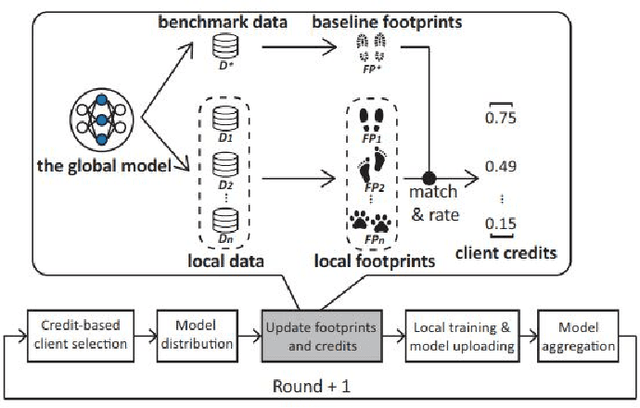
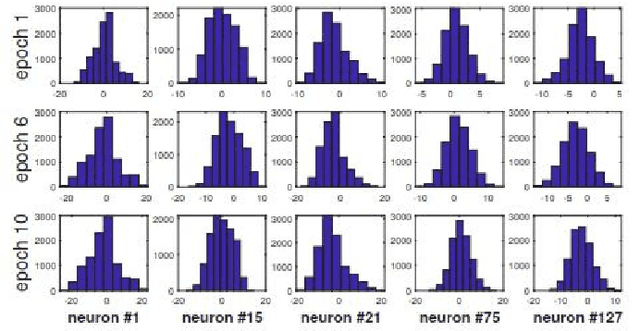
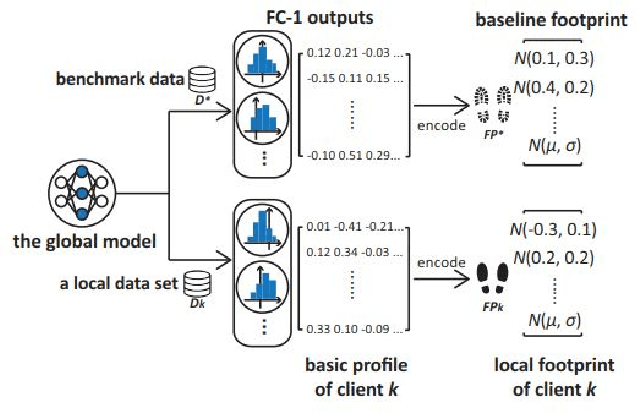
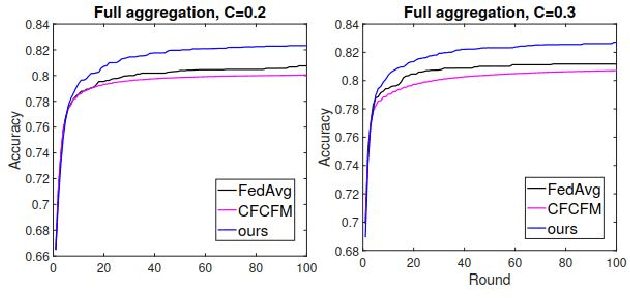
Federated Learning (FL) has shown great potential as a privacy-preserving solution to learning from decentralized data which are only accessible locally on end devices (i.e., clients). In many scenarios, however, a large proportion of the clients are probably in possession of only low-quality data that are biased, noisy or even irrelevant. As a result, they could significantly degrade the quality of the global model we aim to build and slow down its convergence in the course of FL. In light of this, we propose a novel approach to optimizing FL under such circumstances without breaching data privacy. The key of our approach is a dynamic data profiling method for generating model-data footprints on each client and the server. The footprint encodes the representation of the global model on the corresponding data partition based on the output distribution of the model's first fully-connected layer (FC-1). By matching the footprints from clients and the server, we adaptively adjust each client's opportunity of participation in each FL round to mitigate the impact from the clients with low-quality data. We have conducted extensive experiments on public data sets using various FL settings. Results show that our method significantly reduces the number of rounds (by up to 75\%) and overall time (by up to 68\%) required to have the global model converge whiling increasing the global model's accuracy by up to 2.5\%.