 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTMGAN-PLC: Audio Packet Loss Concealment using Temporal Memory Generative Adversarial Network
Jul 04, 2022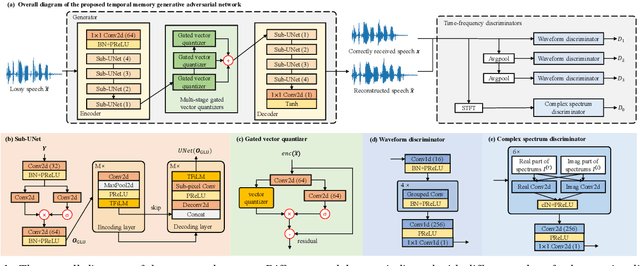
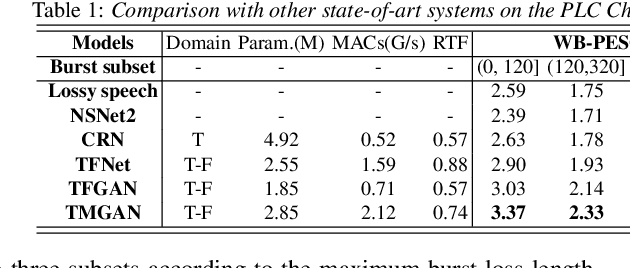
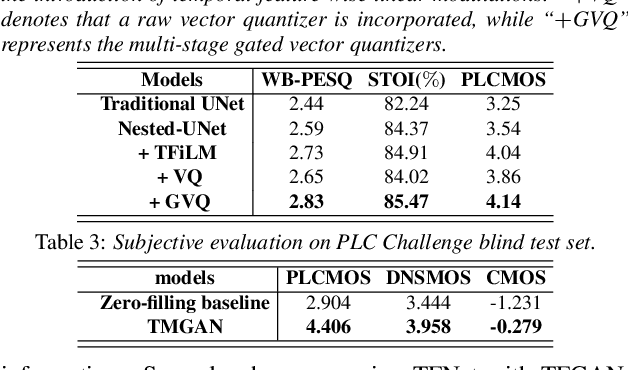
Real-time communications in packet-switched networks have become widely used in daily communication, while they inevitably suffer from network delays and data losses in constrained real-time conditions. To solve these problems, audio packet loss concealment (PLC) algorithms have been developed to mitigate voice transmission failures by reconstructing the lost information. Limited by the transmission latency and device memory, it is still intractable for PLC to accomplish high-quality voice reconstruction using a relatively small packet buffer. In this paper, we propose a temporal memory generative adversarial network for audio PLC, dubbed TMGAN-PLC, which is comprised of a novel nested-UNet generator and the time-domain/frequency-domain discriminators. Specifically, a combination of the nested-UNet and temporal feature-wise linear modulation is elaborately devised in the generator to finely adjust the intra-frame information and establish inter-frame temporal dependencies. To complement the missing speech content caused by longer loss bursts, we employ multi-stage gated vector quantizers to capture the correct content and reconstruct the near-real smooth audio. Extensive experiments on the PLC Challenge dataset demonstrate that the proposed method yields promising performance in terms of speech quality, intelligibility, and PLCMOS.
Taylor, Can You Hear Me Now? A Taylor-Unfolding Framework for Monaural Speech Enhancement
Apr 30, 2022
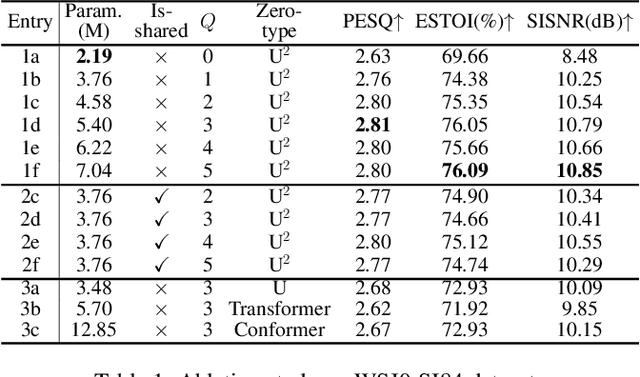
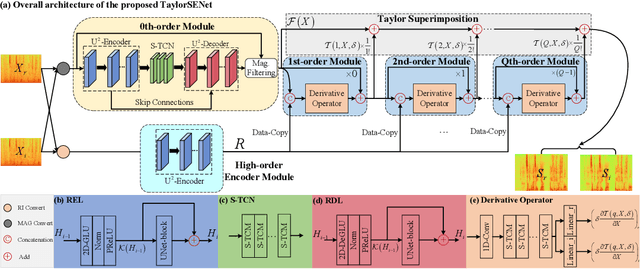
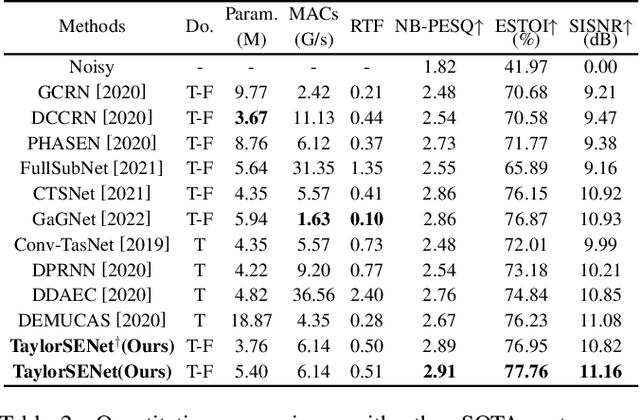
While the deep learning techniques promote the rapid development of the speech enhancement (SE) community, most schemes only pursue the performance in a black-box manner and lack adequate model interpretability. Inspired by Taylor's approximation theory, we propose an interpretable decoupling-style SE framework, which disentangles the complex spectrum recovery into two separate optimization problems \emph{i.e.}, magnitude and complex residual estimation. Specifically, serving as the 0th-order term in Taylor's series, a filter network is delicately devised to suppress the noise component only in the magnitude domain and obtain a coarse spectrum. To refine the phase distribution, we estimate the sparse complex residual, which is defined as the difference between target and coarse spectra, and measures the phase gap. In this study, we formulate the residual component as the combination of various high-order Taylor terms and propose a lightweight trainable module to replace the complicated derivative operator between adjacent terms. Finally, following Taylor's formula, we can reconstruct the target spectrum by the superimposition between 0th-order and high-order terms. Experimental results on two benchmark datasets show that our framework achieves state-of-the-art performance over previous competing baselines in various evaluation metrics. The source code is available at github.com/Andong-Lispeech/TaylorSENet.
Optimizing Shoulder to Shoulder: A Coordinated Sub-Band Fusion Model for Real-Time Full-Band Speech Enhancement
Mar 30, 2022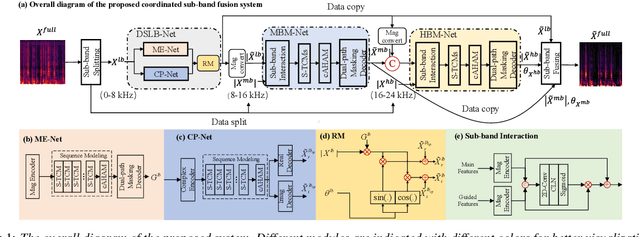
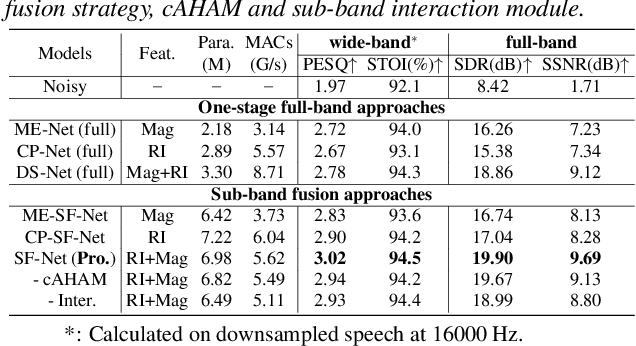
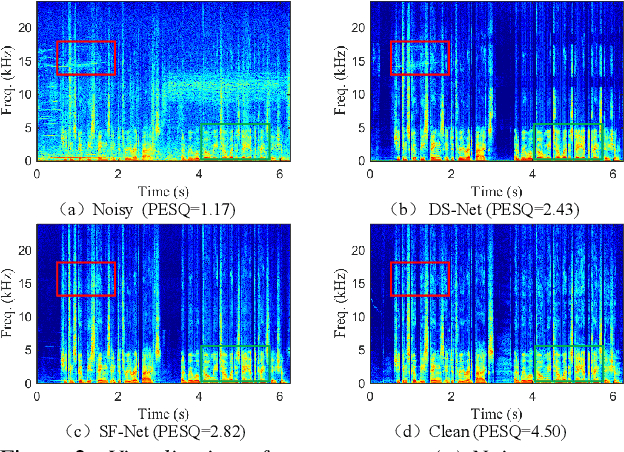
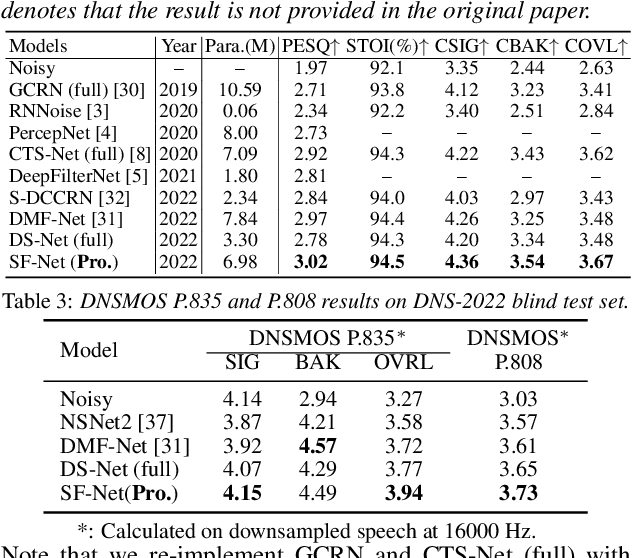
Due to the high computational complexity to model more frequency bands, it is still intractable to conduct real-time full-band speech enhancement based on deep neural networks. Recent studies typically utilize the compressed perceptually motivated features with relatively low frequency resolution to filter the full-band spectrum by one-stage networks, leading to limited speech quality improvements. In this paper, we propose a coordinated sub-band fusion network for full-band speech enhancement, which aims to recover the low- (0-8 kHz), middle- (8-16 kHz), and high-band (16-24 kHz) in a step-wise manner. Specifically, a dual-stream network is first pretrained to recover the low-band complex spectrum, and another two sub-networks are designed as the middle- and high-band noise suppressors in the magnitude-only domain. To fully capitalize on the information intercommunication, we employ a sub-band interaction module to provide external knowledge guidance across different frequency bands. Extensive experiments show that the proposed method yields consistent performance advantages over state-of-the-art full-band baselines.
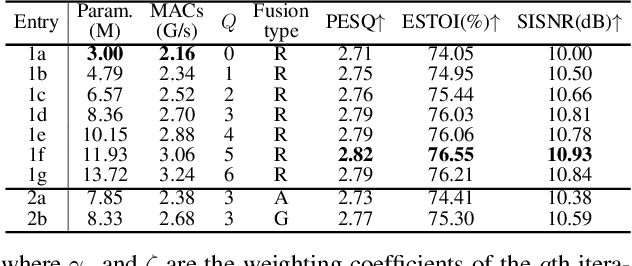
TaylorBeamformer: Learning All-Neural Beamformer for Multi-Channel Speech Enhancement from Taylor's Approximation Theory
Mar 16, 2022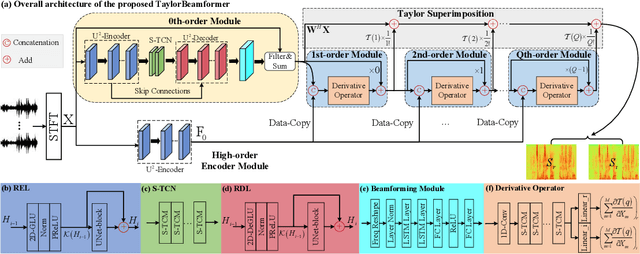
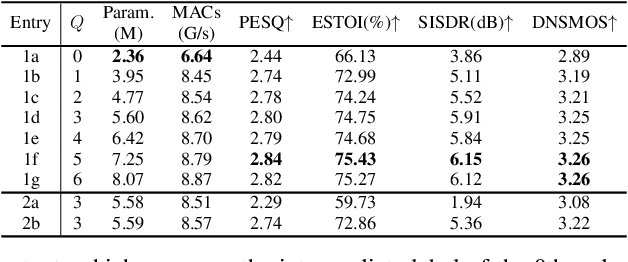
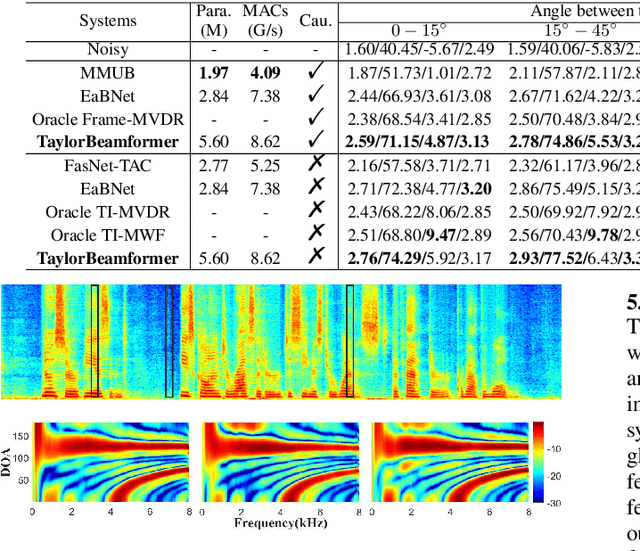
While existing end-to-end beamformers achieve impressive performance in various front-end speech processing tasks, they usually encapsulate the whole process into a black box and thus lack adequate interpretability. As an attempt to fill the blank, we propose a novel neural beamformer inspired by Taylor's approximation theory called TaylorBeamformer for multi-channel speech enhancement. The core idea is that the recovery process can be formulated as the spatial filtering in the neighborhood of the input mixture. Based on that, we decompose it into the superimposition of the 0th-order non-derivative and high-order derivative terms, where the former serves as the spatial filter and the latter is viewed as the residual noise canceller to further improve the speech quality. To enable end-to-end training, we replace the derivative operations with trainable networks and thus can learn from training data. Extensive experiments are conducted on the synthesized dataset based on LibriSpeech and results show that the proposed approach performs favorably against the previous advanced baselines.
MDNet: Learning Monaural Speech Enhancement from Deep Prior Gradient
Mar 16, 2022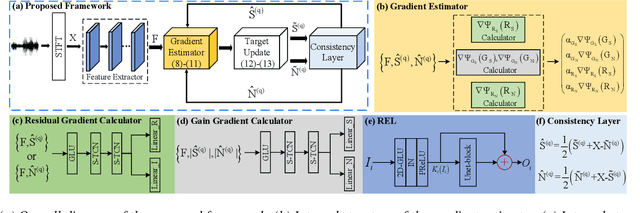
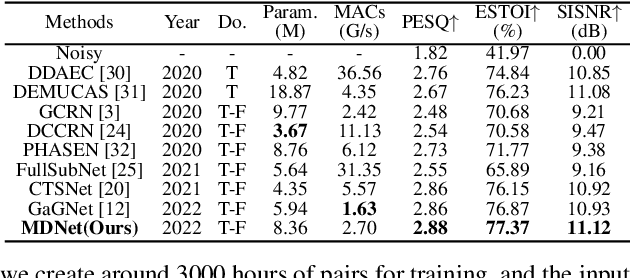
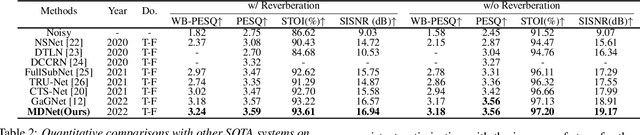
While traditional statistical signal processing model-based methods can derive the optimal estimators relying on specific statistical assumptions, current learning-based methods further promote the performance upper bound via deep neural networks but at the expense of high encapsulation and lack adequate interpretability. Standing upon the intersection between traditional model-based methods and learning-based methods, we propose a model-driven approach based on the maximum a posteriori (MAP) framework, termed as MDNet, for single-channel speech enhancement. Specifically, the original problem is formulated into the joint posterior estimation w.r.t. speech and noise components. Different from the manual assumption toward the prior terms, we propose to model the prior distribution via networks and thus can learn from training data. The framework takes the unfolding structure and in each step, the target parameters can be progressively estimated through explicit gradient descent operations. Besides, another network serves as the fusion module to further refine the previous speech estimation. The experiments are conducted on the WSJ0-SI84 and Interspeech2020 DNS-Challenge datasets, and quantitative results show that the proposed approach outshines previous state-of-the-art baselines.
DMF-Net: A decoupling-style multi-band fusion model for real-time full-band speech enhancement
Mar 02, 2022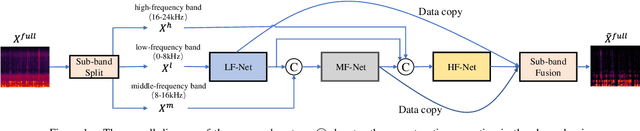
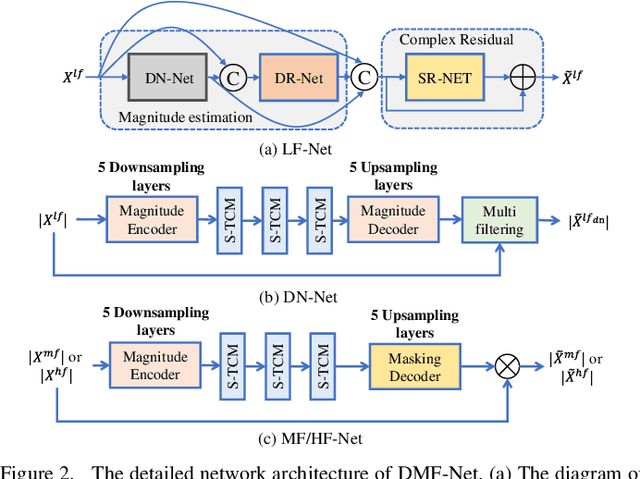
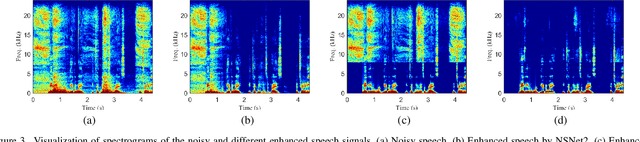
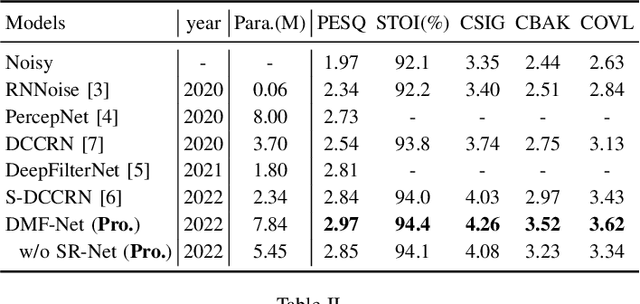
Full-band speech enhancement based on deep neural networks is still challenging for the difficulty of modeling more frequency bands and real-time implementation. Previous studies usually adopt compressed full-band speech features in Bark and ERB scale with relatively low frequency resolution, leading to degraded performance, especially in the high-frequency region. In this paper, we propose a decoupling-style multi-band fusion model to perform full-band speech denoising and dereverberation. Instead of optimizing the full-band speech by a single network structure, we decompose the full-band target into multi sub bands and then employ a multi-stage chain optimization strategy to estimate clean spectrum stage by stage. Specifically, the low- (0-8 kHz), middle- (8-16 kHz), and high-frequency (16-24 kHz) regions are mapped by three separate sub-networks and are then fused to obtain the full-band clean target STFT spectrum. Comprehensive experiments on two public datasets demonstrate that the proposed method outperforms previous advanced systems and yields promising performance in terms of speech quality and intelligibility in real complex scenarios.
DBT-Net: Dual-branch federative magnitude and phase estimation with attention-in-attention transformer for monaural speech enhancement
Feb 16, 2022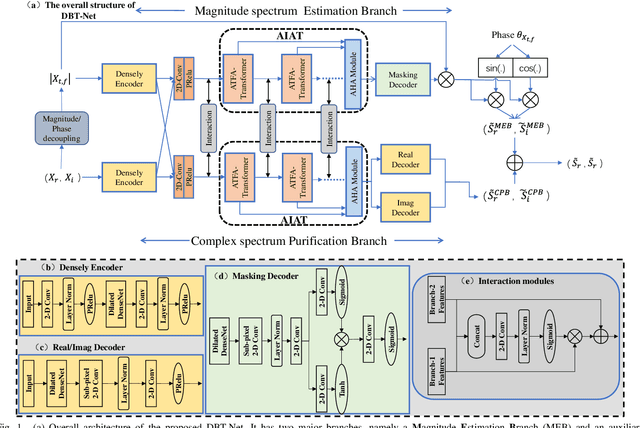
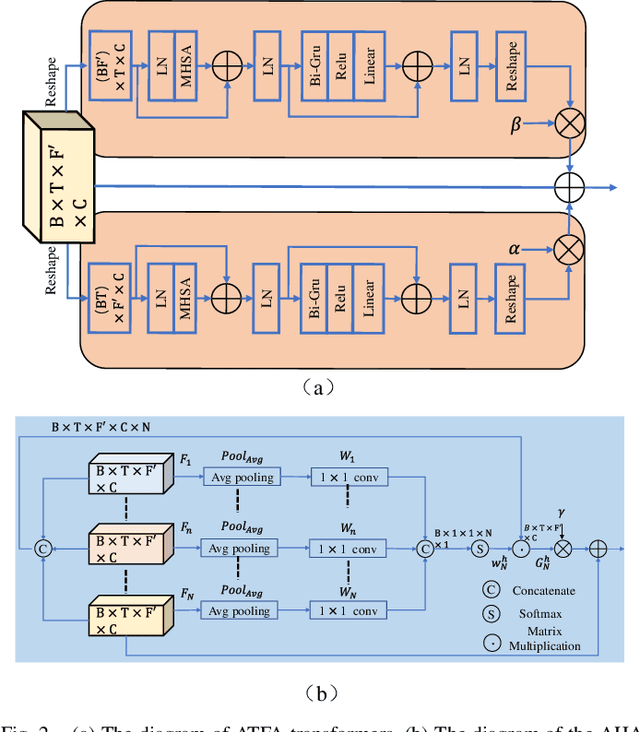
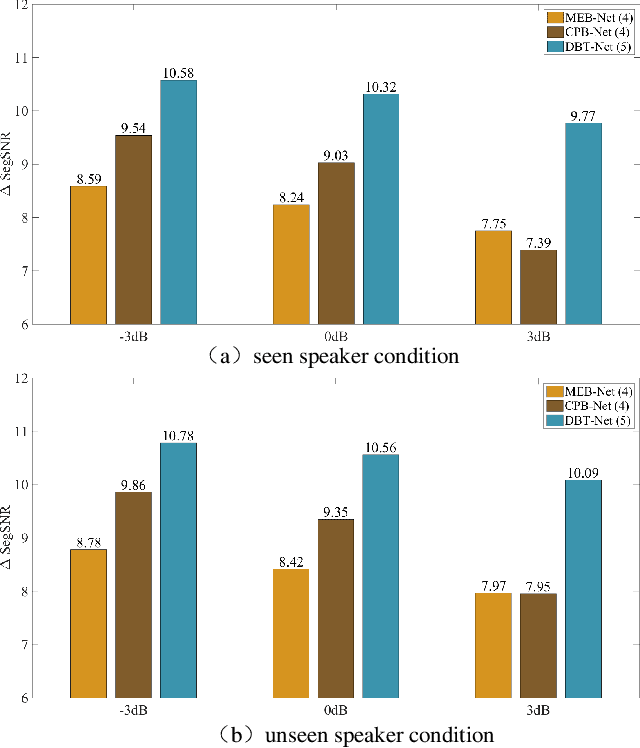
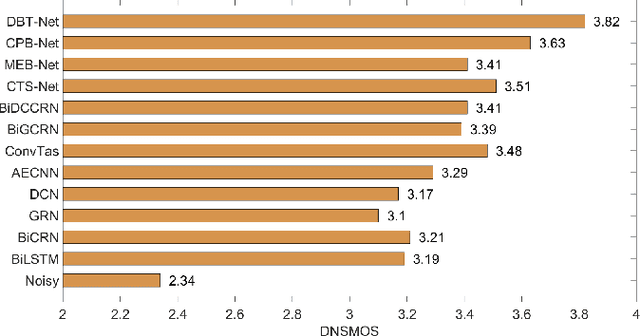
The decoupling-style concept begins to ignite in the speech enhancement area, which decouples the original complex spectrum estimation task into multiple easier sub-tasks (i.e., magnitude and phase), resulting in better performance and easier interpretability. In this paper, we propose a dual-branch federative magnitude and phase estimation framework, dubbed DBT-Net, for monaural speech enhancement, which aims at recovering the coarse- and fine-grained regions of the overall spectrum in parallel. From the complementary perspective, the magnitude estimation branch is designed to filter out dominant noise components in the magnitude domain, while the complex spectrum purification branch is elaborately designed to inpaint the missing spectral details and implicitly estimate the phase information in the complex domain. To facilitate the information flow between each branch, interaction modules are introduced to leverage features learned from one branch, so as to suppress the undesired parts and recover the missing components of the other branch. Instead of adopting the conventional RNNs and temporal convolutional networks for sequence modeling, we propose a novel attention-in-attention transformer-based network within each branch for better feature learning. More specially, it is composed of several adaptive spectro-temporal attention transformer-based modules and an adaptive hierarchical attention module, aiming to capture long-term time-frequency dependencies and further aggregate intermediate hierarchical contextual information. Comprehensive evaluations on the WSJ0-SI84 + DNS-Challenge and VoiceBank + DEMAND dataset demonstrate that the proposed approach consistently outperforms previous advanced systems and yields state-of-the-art performance in terms of speech quality and intelligibility.
Low-latency Monaural Speech Enhancement with Deep Filter-bank Equalizer
Feb 14, 2022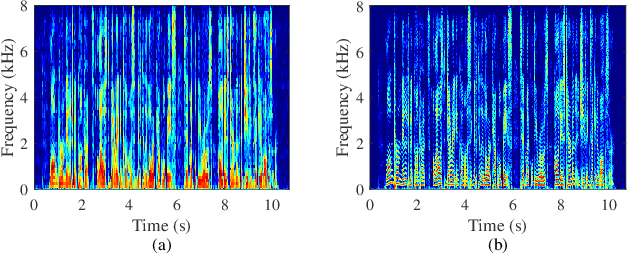

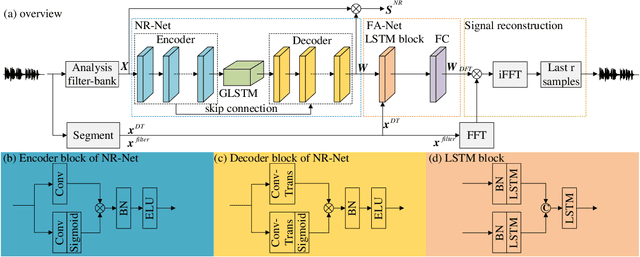
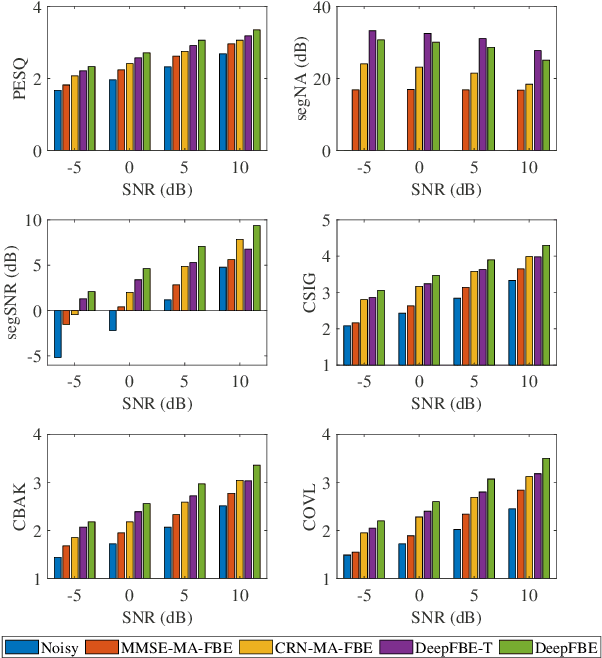
It is highly desirable that speech enhancement algorithms can achieve good performance while keeping low latency for many applications, such as digital hearing aids, acoustically transparent hearing devices, and public address systems. To improve the performance of traditional low-latency speech enhancement algorithms, a deep filter-bank equalizer (FBE) framework was proposed, which integrated a deep learning-based subband noise reduction network with a deep learning-based shortened digital filter mapping network. In the first network, a deep learning model was trained with a controllable small frame shift to satisfy the low-latency demand, i.e., $\le$ 4 ms, so as to obtain (complex) subband gains, which could be regarded as an adaptive digital filter in each frame. In the second network, to reduce the latency, this adaptive digital filter was implicitly shortened by a deep learning-based framework, and was then applied to noisy speech to reconstruct the enhanced speech without the overlap-add method. Experimental results on the WSJ0-SI84 corpus indicated that the proposed deep FBE with only 4-ms latency achieved much better performance than traditional low-latency speech enhancement algorithms in terms of the indices such as PESQ, STOI, and the amount of noise reduction.
A Neural Beam Filter for Real-time Multi-channel Speech Enhancement
Feb 05, 2022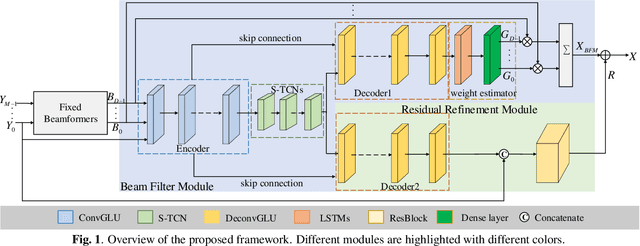
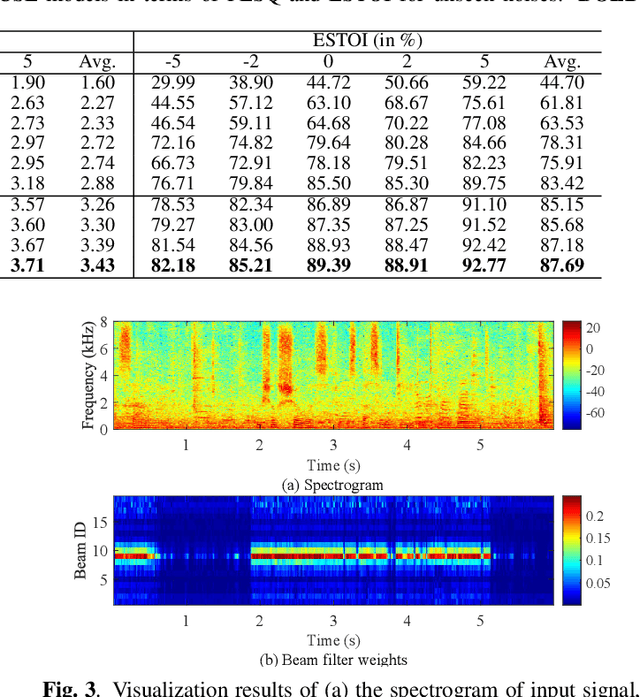
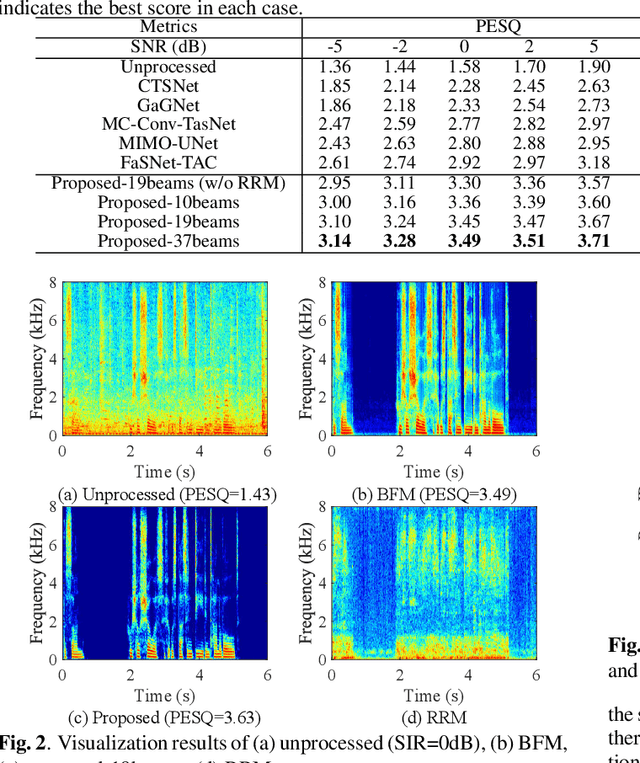
Most deep learning-based multi-channel speech enhancement methods focus on designing a set of beamforming coefficients to directly filter the low signal-to-noise ratio signals received by microphones, which hinders the performance of these approaches. To handle these problems, this paper designs a causal neural beam filter that fully exploits the spatial-spectral information in the beam domain. Specifically, multiple beams are designed to steer towards all directions using a parameterized super-directive beamformer in the first stage. After that, the neural spatial filter is learned by simultaneously modeling the spatial and spectral discriminability of the speech and the interference, so as to extract the desired speech coarsely in the second stage. Finally, to further suppress the interference components especially at low frequencies, a residual estimation module is adopted to refine the output of the second stage. Experimental results demonstrate that the proposed approach outperforms many state-of-the-art multi-channel methods on the generated multi-channel speech dataset based on the DNS-Challenge dataset.
A deep complex network with multi-frame filtering for stereophonic acoustic echo cancellation
Feb 03, 2022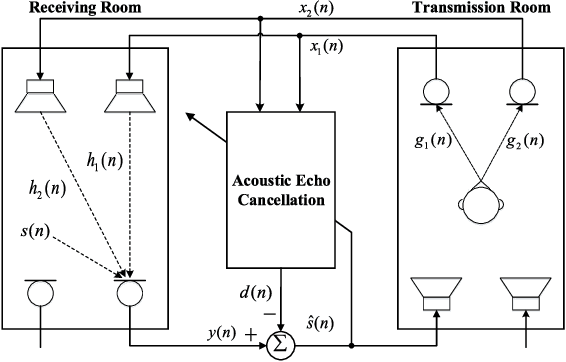
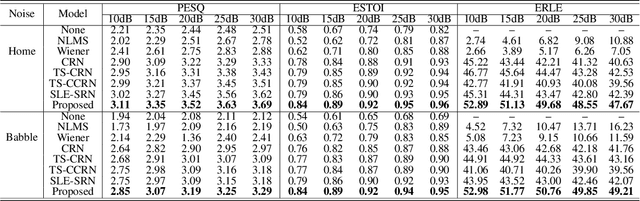
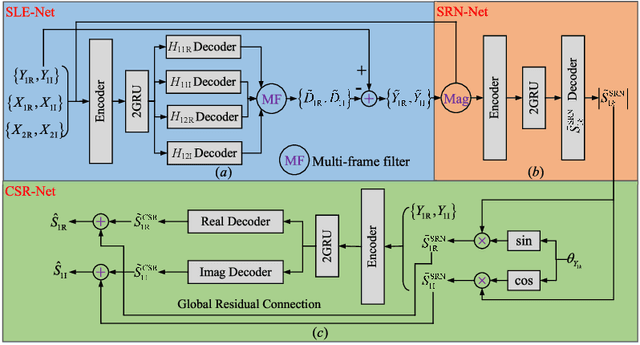
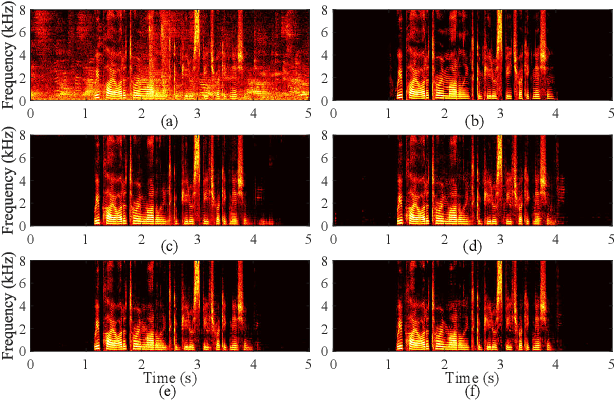
In hands-free communication system, the coupling between the loudspeaker and the microphone will generate echo signal, which can severely impair the quality of communication. Meanwhile, various types of noise in the communication environment further destroy the speech quality and intelligibility. It is hard to extract the near-end signal from the microphone input signal within one step, especially in low signal-to-noise ratios. In this paper, we propose a multi-stage approach to address this issue. On the one hand, we decompose the echo cancellation into two stages, including linear echo cancellation module and residual echo suppression module. A multi-frame filtering strategy is introduced to benefit estimating linear echo by utilizing more inter-frame information. On the other hand, we decouple the complex spectral mapping into magnitude estimation and complex spectra refine. Experimental results demonstrate that our proposed approach achieves stage-of-the-art performance over previous advanced algorithms under various conditions.