 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification of the Virial Black Hole Mass with Conformal Prediction
Jul 11, 2023Precise measurements of the black hole mass are essential to gain insight on the black hole and host galaxy co-evolution. A direct measure of the black hole mass is often restricted to nearest galaxies and instead, an indirect method using the single-epoch virial black hole mass estimation is used for objects at high redshifts. However, this method is subjected to biases and uncertainties as it is reliant on the scaling relation from a small sample of local active galactic nuclei. In this study, we propose the application of conformalised quantile regression (CQR) to quantify the uncertainties of the black hole predictions in a machine learning setting. We compare CQR with various prediction interval techniques and demonstrated that CQR can provide a more useful prediction interval indicator. In contrast to baseline approaches for prediction interval estimation, we show that the CQR method provides prediction intervals that adjust to the black hole mass and its related properties. That is it yields a tighter constraint on the prediction interval (hence more certain) for a larger black hole mass, and accordingly, bright and broad spectral line width source. Using a combination of neural network model and CQR framework, the recovered virial black hole mass predictions and uncertainties are comparable to those measured from the Sloan Digital Sky Survey. The code is publicly available at https://github.com/yongsukyee/uncertain_blackholemass.
Squared Neural Families: A New Class of Tractable Density Models
May 22, 2023



Flexible models for probability distributions are an essential ingredient in many machine learning tasks. We develop and investigate a new class of probability distributions, which we call a Squared Neural Family (SNEFY), formed by squaring the 2-norm of a neural network and normalising it with respect to a base measure. Following the reasoning similar to the well established connections between infinitely wide neural networks and Gaussian processes, we show that SNEFYs admit a closed form normalising constants in many cases of interest, thereby resulting in flexible yet fully tractable density models. SNEFYs strictly generalise classical exponential families, are closed under conditioning, and have tractable marginal distributions. Their utility is illustrated on a variety of density estimation and conditional density estimation tasks. Software available at https://github.com/RussellTsuchida/snefy.
Deep equilibrium models as estimators for continuous latent variables
Nov 11, 2022



Principal Component Analysis (PCA) and its exponential family extensions have three components: observations, latents and parameters of a linear transformation. We consider a generalised setting where the canonical parameters of the exponential family are a nonlinear transformation of the latents. We show explicit relationships between particular neural network architectures and the corresponding statistical models. We find that deep equilibrium models -- a recently introduced class of implicit neural networks -- solve maximum a-posteriori (MAP) estimates for the latents and parameters of the transformation. Our analysis provides a systematic way to relate activation functions, dropout, and layer structure, to statistical assumptions about the observations, thus providing foundational principles for unsupervised DEQs. For hierarchical latents, individual neurons can be interpreted as nodes in a deep graphical model. Our DEQ feature maps are end-to-end differentiable, enabling fine-tuning for downstream tasks.
Two-Stage Neural Contextual Bandits for Personalised News Recommendation
Jun 26, 2022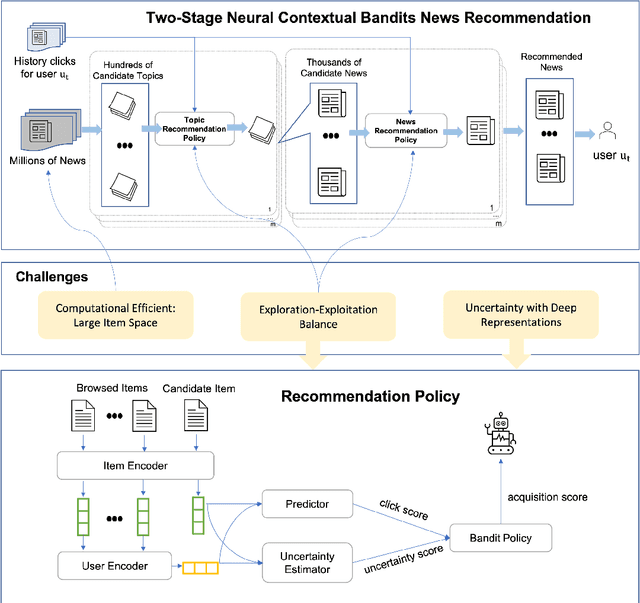

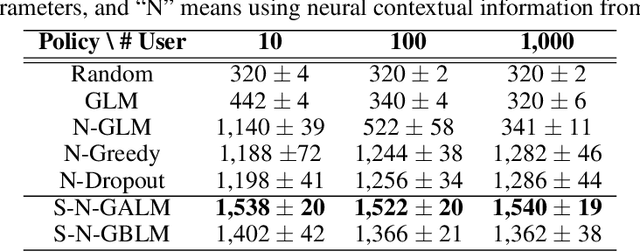
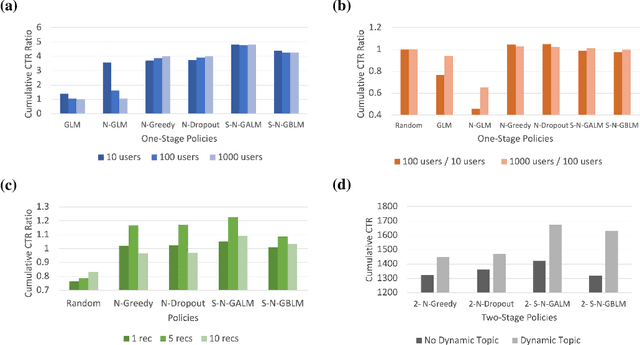
We consider the problem of personalised news recommendation where each user consumes news in a sequential fashion. Existing personalised news recommendation methods focus on exploiting user interests and ignores exploration in recommendation, which leads to biased feedback loops and hurt recommendation quality in the long term. We build on contextual bandits recommendation strategies which naturally address the exploitation-exploration trade-off. The main challenges are the computational efficiency for exploring the large-scale item space and utilising the deep representations with uncertainty. We propose a two-stage hierarchical topic-news deep contextual bandits framework to efficiently learn user preferences when there are many news items. We use deep learning representations for users and news, and generalise the neural upper confidence bound (UCB) policies to generalised additive UCB and bilinear UCB. Empirical results on a large-scale news recommendation dataset show that our proposed policies are efficient and outperform the baseline bandit policies.
Gaussian Process Bandits with Aggregated Feedback
Dec 24, 2021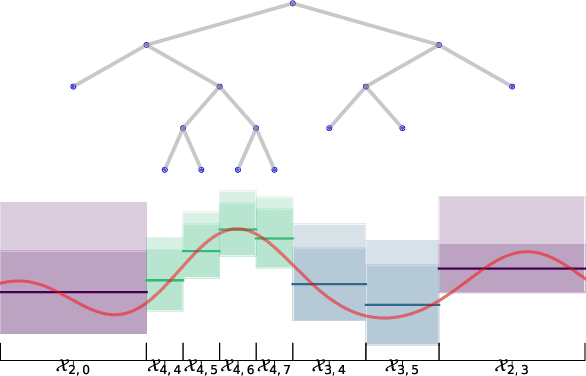
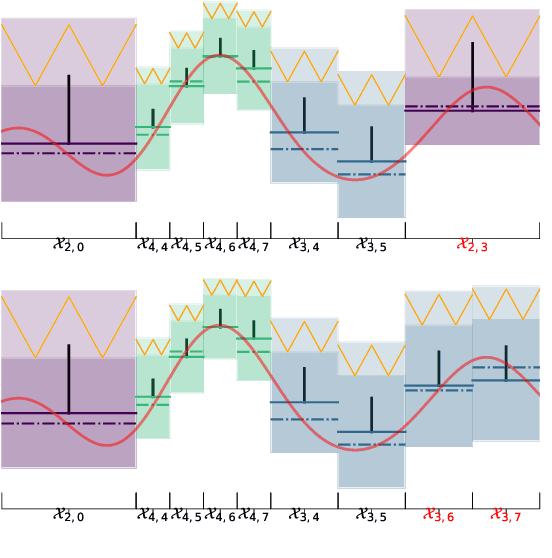
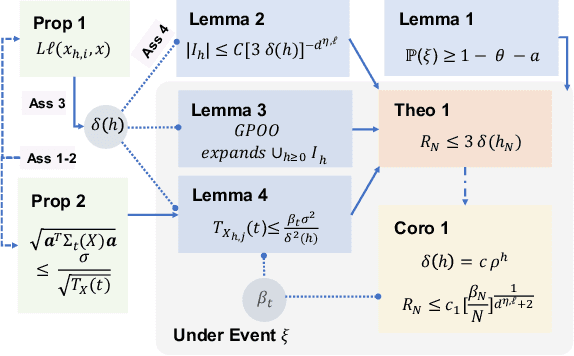
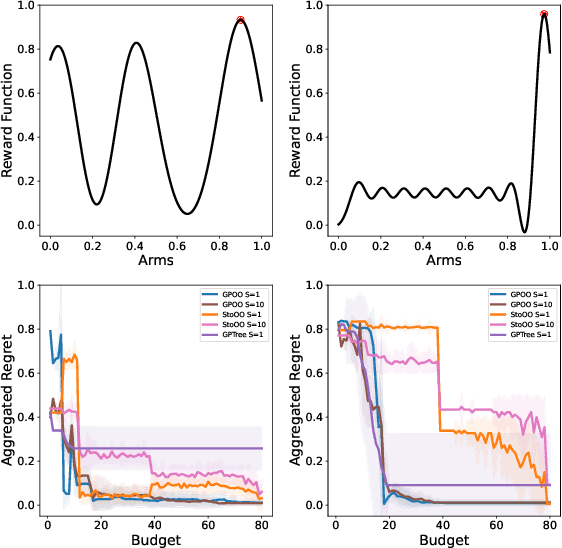
We consider the continuum-armed bandits problem, under a novel setting of recommending the best arms within a fixed budget under aggregated feedback. This is motivated by applications where the precise rewards are impossible or expensive to obtain, while an aggregated reward or feedback, such as the average over a subset, is available. We constrain the set of reward functions by assuming that they are from a Gaussian Process and propose the Gaussian Process Optimistic Optimisation (GPOO) algorithm. We adaptively construct a tree with nodes as subsets of the arm space, where the feedback is the aggregated reward of representatives of a node. We propose a new simple regret notion with respect to aggregated feedback on the recommended arms. We provide theoretical analysis for the proposed algorithm, and recover single point feedback as a special case. We illustrate GPOO and compare it with related algorithms on simulated data.
Factorized Fourier Neural Operators
Nov 30, 2021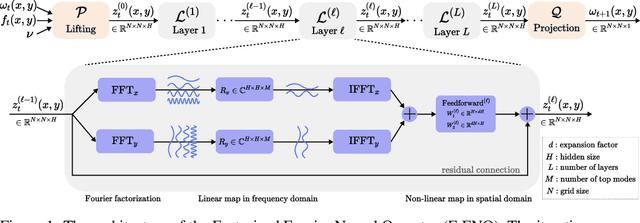
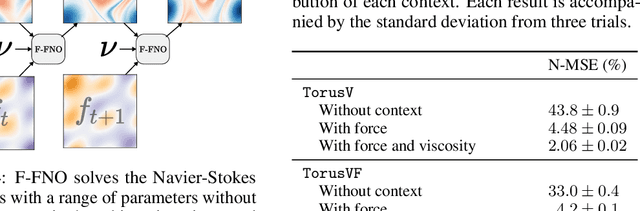
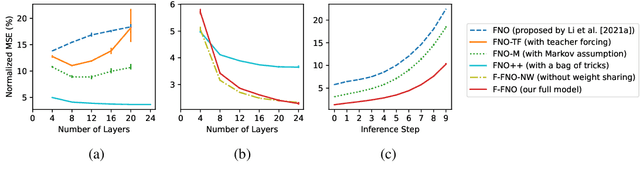

The Fourier Neural Operator (FNO) is a learning-based method for efficiently simulating partial differential equations. We propose the Factorized Fourier Neural Operator (F-FNO) that allows much better generalization with deeper networks. With a careful combination of the Fourier factorization, a shared kernel integral operator across all layers, the Markov property, and residual connections, F-FNOs achieve a six-fold reduction in error on the most turbulent setting of the Navier-Stokes benchmark dataset. We show that our model maintains an error rate of 2% while still running an order of magnitude faster than a numerical solver, even when the problem setting is extended to include additional contexts such as viscosity and time-varying forces. This enables the same pretrained neural network to model vastly different conditions.
Radflow: A Recurrent, Aggregated, and Decomposable Model for Networks of Time Series
Feb 15, 2021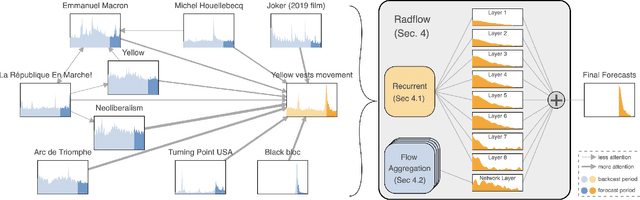
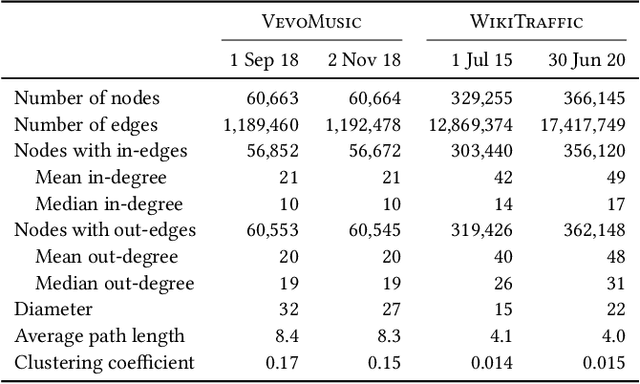
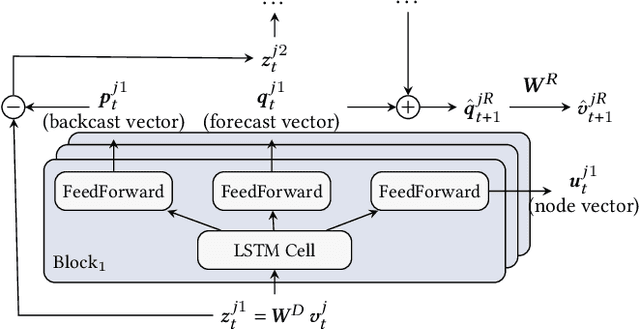
We propose a new model for networks of time series that influence each other. Graph structures among time series are found in diverse domains, such as web traffic influenced by hyperlinks, product sales influenced by recommendation, or urban transport volume influenced by road networks and weather. There has been recent progress in graph modeling and in time series forecasting, respectively, but an expressive and scalable approach for a network of series does not yet exist. We introduce Radflow, a novel model that embodies three key ideas: a recurrent neural network to obtain node embeddings that depend on time, the aggregation of the flow of influence from neighboring nodes with multi-head attention, and the multi-layer decomposition of time series. Radflow naturally takes into account dynamic networks where nodes and edges change over time, and it can be used for prediction and data imputation tasks. On real-world datasets ranging from a few hundred to a few hundred thousand nodes, we observe that Radflow variants are the best performing model across a wide range of settings. The recurrent component in Radflow also outperforms N-BEATS, the state-of-the-art time series model. We show that Radflow can learn different trends and seasonal patterns, that it is robust to missing nodes and edges, and that correlated temporal patterns among network neighbors reflect influence strength. We curate WikiTraffic, the largest dynamic network of time series with 366K nodes and 22M time-dependent links spanning five years. This dataset provides an open benchmark for developing models in this area, with applications that include optimizing resources for the web. More broadly, Radflow has the potential to improve forecasts in correlated time series networks such as the stock market, and impute missing measurements in geographically dispersed networks of natural phenomena.
* Published in The Web Conference 2021. Code is available at https://github.com/alasdairtran/radflow
Quantile Bandits for Best Arms Identification with Concentration Inequalities
Oct 22, 2020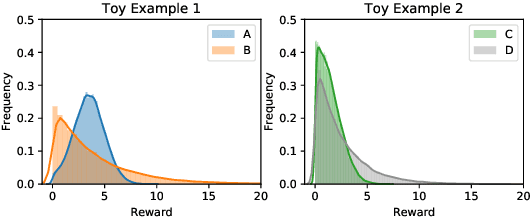
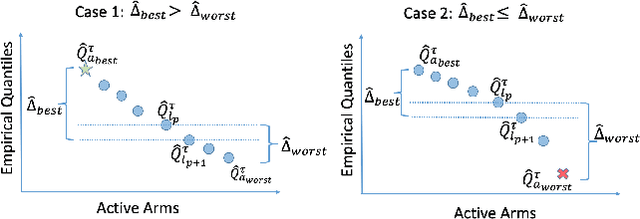
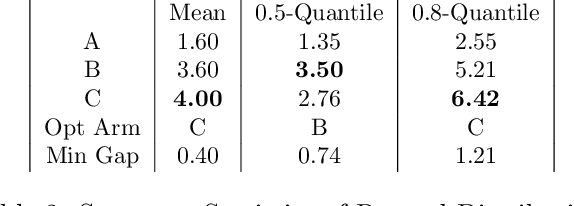
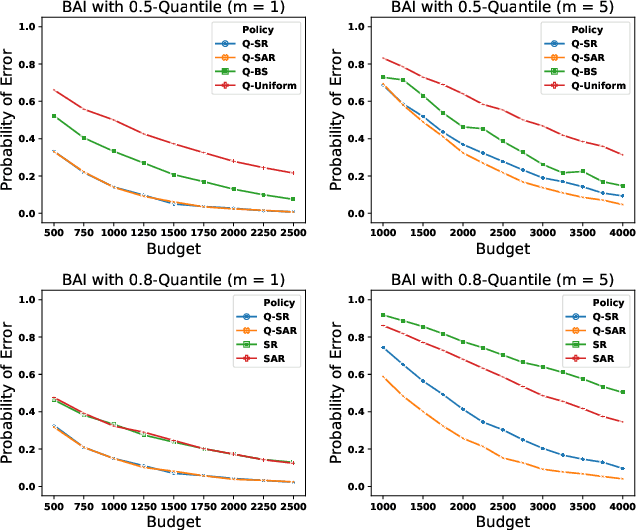
We consider a variant of the best arm identification task in stochastic multi-armed bandits. Motivated by risk-averse decision-making problems in fields like medicine, biology and finance, our goal is to identify a set of $m$ arms with the highest $\tau$-quantile values under a fixed budget. We propose Quantile Successive Accepts and Rejects algorithm (Q-SAR), the first quantile based algorithm for fixed budget multiple arms identification. We prove two-sided asymmetric concentration inequalities for order statistics and quantiles of random variables that have non-decreasing hazard rate, which may be of independent interest. With the proposed concentration inequalities, we upper bound the probability of arm misidentification for the bandit task. We show illustrative experiments for best arm identification.
New Tricks for Estimating Gradients of Expectations
Jan 31, 2019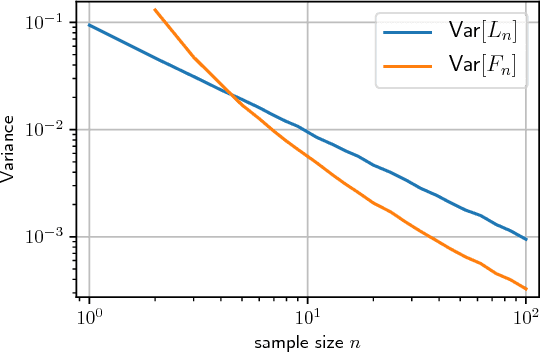

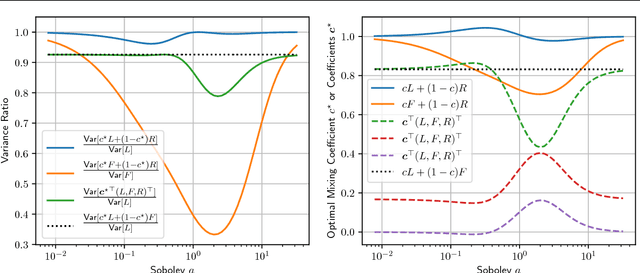
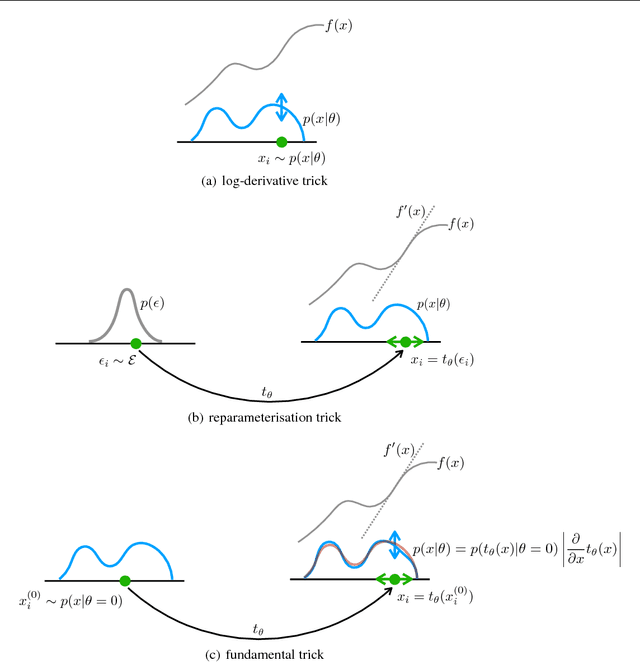
We derive a family of Monte Carlo estimators for gradients of expectations of univariate distributions, which is related to the log-derivative trick, but involves pairwise interactions between samples. The first of these comes from either a) introducing and approximating an integral representation based on the fundamental theorem of calculus, or b) applying the reparameterisation trick to an implicit parameterisation under infinitesimal perturbation of the parameters. From the former perspective we generalise to a reproducing kernel Hilbert space representation, giving rise to locality parameter in the pairwise interactions mentioned above. The resulting estimators are unbiased and shown to offer an independent component of useful information in comparison with the log-derivative estimator. Promising analytical and numerical examples confirm the intuitions behind the new estimators.
Cold-start Playlist Recommendation with Multitask Learning
Jan 18, 2019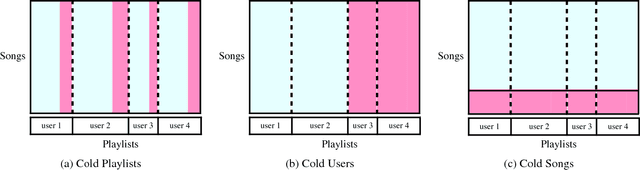
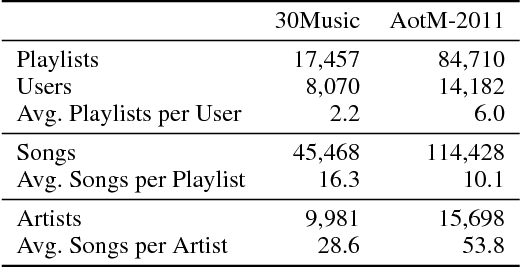

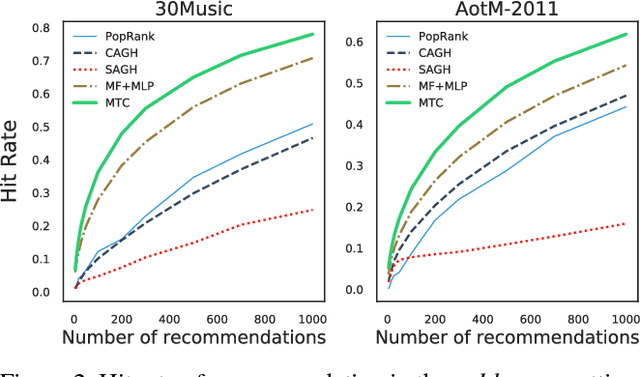
Playlist recommendation involves producing a set of songs that a user might enjoy. We investigate this problem in three cold-start scenarios: (i) cold playlists, where we recommend songs to form new personalised playlists for an existing user; (ii) cold users, where we recommend songs to form new playlists for a new user; and (iii) cold songs, where we recommend newly released songs to extend users' existing playlists. We propose a flexible multitask learning method to deal with all three settings. The method learns from user-curated playlists, and encourages songs in a playlist to be ranked higher than those that are not by minimising a bipartite ranking loss. Inspired by an equivalence between bipartite ranking and binary classification, we show how one can efficiently approximate an optimal solution of the multitask learning objective by minimising a classification loss. Empirical results on two real playlist datasets show the proposed approach has good performance for cold-start playlist recommendation.