 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgents' Last Exam
Jun 03, 2026Recent AI systems have achieved strong results on a wide range of benchmarks, yet these gains have not translated into economically meaningful deployment across many professional domains. We argue that this gap is largely an evaluation problem: widely used benchmarks lack sustained performance measurement on real and economically valuable workflows. This paper introduces Agents' Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes. Developed in collaboration with 250+ industry experts, ALE covers non-physical industries defined with reference to O*NET / SOC 2018 (the U.S. federal occupational taxonomy). It is organized around a task taxonomy with 55 subfields grouped into 13 industry clusters covering 1K+ tasks. Current results show that the hardest tier remains far from saturated: across mainstream harness and backbone configurations, the average full pass rate is 2.6%. ALE is designed as a living benchmark: its task pool grows continuously as new workflows and industries are onboarded. More broadly, ALE is intended not merely as another leaderboard, but as an instrument for closing the gap between benchmark success and GDP-relevant impact.
RSC: Decentralized Rigid Formation Flocking for Large-Scale Swarms via Hybrid Predictive Control and Online Reconfiguration
Jun 02, 2026Decentralized rigid formation flocking requires a swarm of autonomous agents to maintain a predetermined geometric configuration while moving, relying solely on local sensing and communication. However, existing decentralized control methods struggle to maintain strict inter-agent distance constraints in cluttered environments, often suffering from local minima deadlocks, high frequency control oscillations, or limited flexibility during obstacle navigation, resulting in low success rate. To address these limitations, we propose Rigid Swarm Control (RSC), a decentralized control framework for large-scale rigid formation flocking. To escape local minima via robust long-term planning while ensuring short-term safety, RSC integrates finite-horizon trajectory predictions with a reactive artificial potential field (APF) safety controller within a hybrid architecture. Furthermore, to accelerate formation reassembly after obstacle traversal without interrupting task execution, RSC introduces an online leader-follower reconfiguration mechanism based on stable role exchange. Extensive evaluations in challenging cluttered environments with 25 UAVs demonstrate that RSC reliably unifies rigid formation maintenance, obstacle avoidance, and target tracking. Under strict success criteria - collision-free operation with a maximum relative edge-length error below 10%, RSC achieves an 83% success rate, significantly outperforming existing heuristic and learning-based baselines that fall below 5%.
ContractSkill: Repairable Contract-Based Skills for Multimodal Web Agents
Mar 20, 2026Despite rapid progress in multimodal GUI agents, reusable skill acquisition remains difficult because on-demand generated skills often leave action semantics, state assumptions, and success criteria implicit. This makes them brittle to execution errors, hard to verify, and difficult to repair. We present ContractSkill, a framework that converts a draft skill into a contracted executable artifact with explicit preconditions, step specifications, postconditions, recovery rules, and termination checks. This representation enables deterministic verification, step-level fault localization, and minimal patch-based repair, turning skill refinement into localized editing rather than full regeneration. Experiments on VisualWebArena and MiniWoB with GLM-4.6V and Qwen3.5-Plus show that ContractSkill improves self-generated skills from 9.4% and 10.9% to 28.1% and 37.5% on VisualWebArena, and from 66.5% and 60.5% to 77.5% and 81.0% on MiniWoB. Repaired artifacts also transfer across models, improving the target model's self-generated-skill baseline by up to 47.8 points and 12.8 points on the two benchmarks, respectively. These results suggest that agent skills are better treated as explicit procedural artifacts that can be verified, repaired, and shared across models.
From Plausibility to Verifiability: Risk-Controlled Generative OCR for Vision-Language Models
Mar 20, 2026Modern vision-language models (VLMs) can act as generative OCR engines, yet open-ended decoding can expose rare but consequential failures. We identify a core deployment misalignment in generative OCR. Autoregressive decoding favors semantic plausibility, whereas OCR requires outputs that are visually grounded and geometrically verifiable. This mismatch produces severe errors, especially over-generation and unsupported substitutions, creating deployment risk even when benchmark accuracy remains high. We therefore formulate frozen VLM OCR as a selective accept/abstain problem and propose a model-agnostic Geometric Risk Controller. The controller probes multiple structured views of the same input, applies lightweight structural screening, and accepts a transcription only when cross-view consensus and stability satisfy predefined criteria, yielding a small family of operating points. Experiments on frozen VLM backbones and standard OCR benchmarks show consistent reductions in extreme-error risk and catastrophic over-generation at predictable coverage costs. Reliable deployment of generative OCR with frozen VLMs benefits from explicit system-level risk control rather than unconstrained generation.
Fluid Antenna for Mobile Edge Computing
Mar 18, 2024



In the evolving environment of mobile edge computing (MEC), optimizing system performance to meet the growing demand for low-latency computing services is a top priority. Integrating fluidic antenna (FA) technology into MEC networks provides a new approach to address this challenge. This letter proposes an FA-enabled MEC scheme that aims to minimize the total system delay by leveraging the mobility of FA to enhance channel conditions and improve computational offloading efficiency. By establishing an optimization problem focusing on the joint optimization of computation offloading and antenna positioning, we introduce an alternating iterative algorithm based on the interior point method and particle swarm optimization (IPPSO). Numerical results demonstrate the advantages of our proposed scheme compared to traditional fixed antenna positions, showing significant improvements in transmission rates and reductions in delays. The proposed IPPSO algorithm exhibits robust convergence properties, further validating the effectiveness of our method.
Deep Fusion of Multi-Object Densities Using Transformer
Sep 23, 2022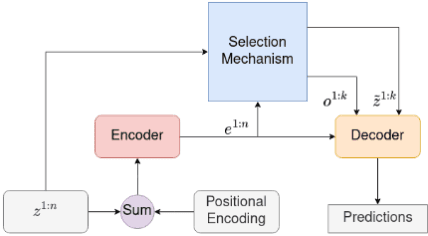

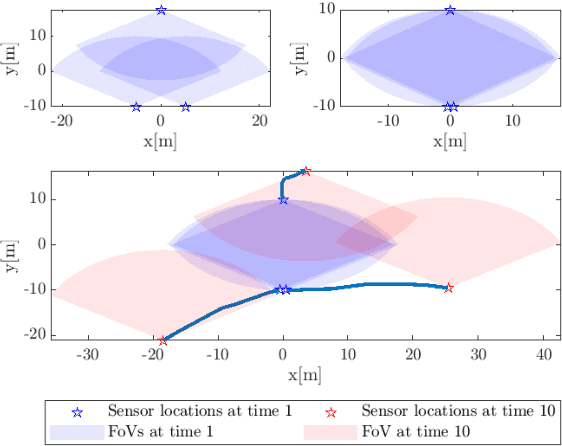
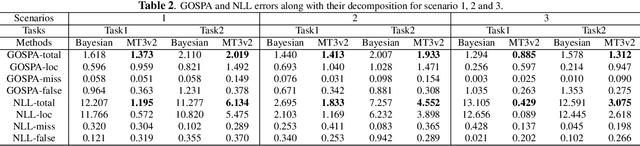
In this paper, we demonstrate that deep learning based method can be used to fuse multi-object densities. Given a scenario with several sensors with possibly different field-of-views, tracking is performed locally in each sensor by a tracker, which produces random finite set multi-object densities. To fuse outputs from different trackers, we adapt a recently proposed transformer-based multi-object tracker, where the fusion result is a global multi-object density, describing the set of all alive objects at the current time. We compare the performance of the transformer-based fusion method with a well-performing model-based Bayesian fusion method in several simulated scenarios with different parameter settings using synthetic data. The simulation results show that the transformer-based fusion method outperforms the model-based Bayesian method in our experimental scenarios.