 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Reconstruction with Predictive Filter Flow
Nov 28, 2018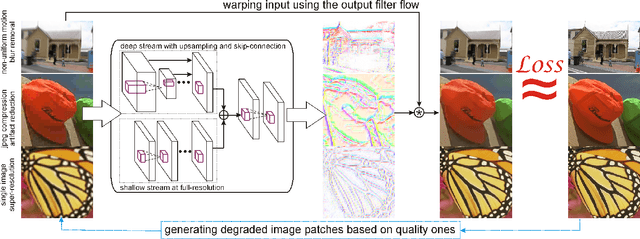
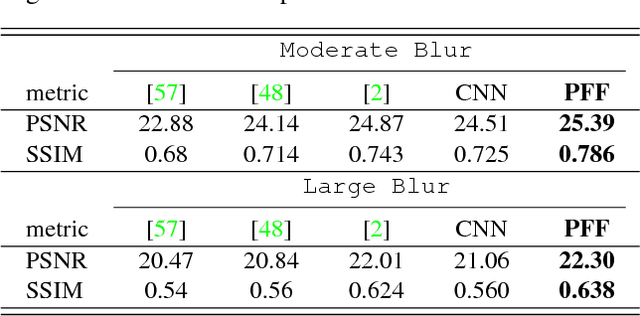

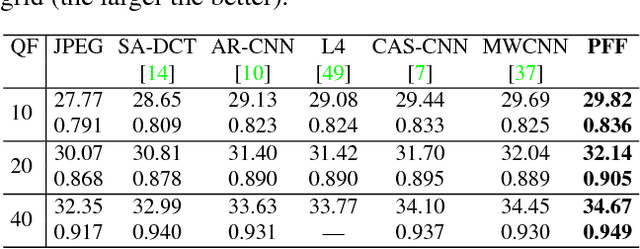
We propose a simple, interpretable framework for solving a wide range of image reconstruction problems such as denoising and deconvolution. Given a corrupted input image, the model synthesizes a spatially varying linear filter which, when applied to the input image, reconstructs the desired output. The model parameters are learned using supervised or self-supervised training. We test this model on three tasks: non-uniform motion blur removal, lossy-compression artifact reduction and single image super resolution. We demonstrate that our model substantially outperforms state-of-the-art methods on all these tasks and is significantly faster than optimization-based approaches to deconvolution. Unlike models that directly predict output pixel values, the predicted filter flow is controllable and interpretable, which we demonstrate by visualizing the space of predicted filters for different tasks.
Active Testing: An Efficient and Robust Framework for Estimating Accuracy
Jul 02, 2018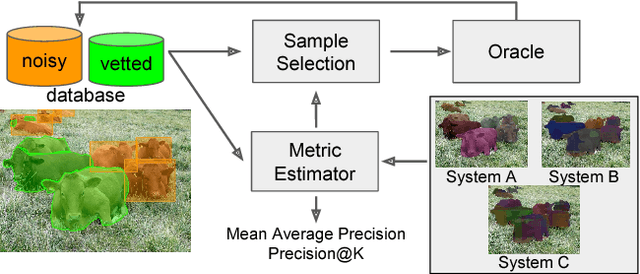
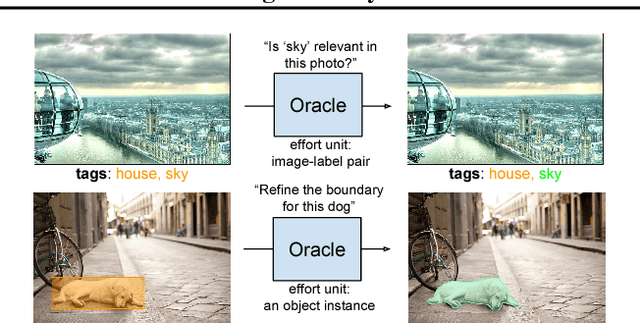
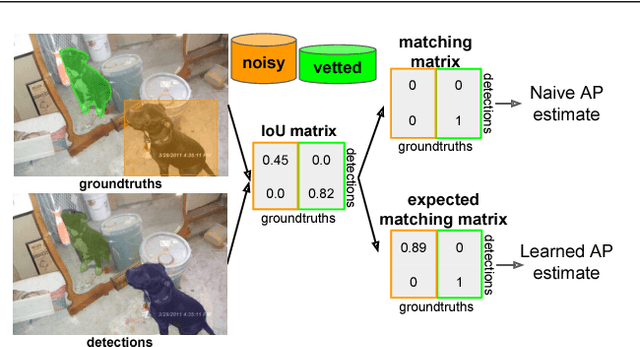

Much recent work on visual recognition aims to scale up learning to massive, noisily-annotated datasets. We address the problem of scaling- up the evaluation of such models to large-scale datasets with noisy labels. Current protocols for doing so require a human user to either vet (re-annotate) a small fraction of the test set and ignore the rest, or else correct errors in annotation as they are found through manual inspection of results. In this work, we re-formulate the problem as one of active testing, and examine strategies for efficiently querying a user so as to obtain an accu- rate performance estimate with minimal vetting. We demonstrate the effectiveness of our proposed active testing framework on estimating two performance metrics, Precision@K and mean Average Precision, for two popular computer vision tasks, multi-label classification and instance segmentation. We further show that our approach is able to save significant human annotation effort and is more robust than alternative evaluation protocols.
Pixel-wise Attentional Gating for Parsimonious Pixel Labeling
May 03, 2018
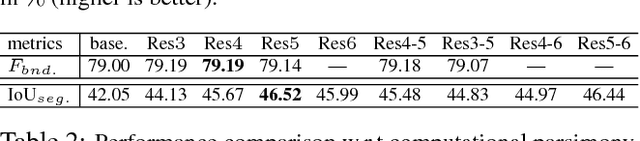

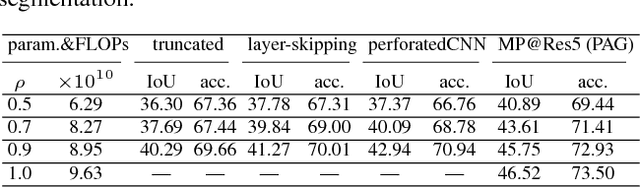
To achieve parsimonious inference in per-pixel labeling tasks with a limited computational budget, we propose a \emph{Pixel-wise Attentional Gating} unit (\emph{PAG}) that learns to selectively process a subset of spatial locations at each layer of a deep convolutional network. PAG is a generic, architecture-independent, problem-agnostic mechanism that can be readily "plugged in" to an existing model with fine-tuning. We utilize PAG in two ways: 1) learning spatially varying pooling fields that improve model performance without the extra computation cost associated with multi-scale pooling, and 2) learning a dynamic computation policy for each pixel to decrease total computation while maintaining accuracy. We extensively evaluate PAG on a variety of per-pixel labeling tasks, including semantic segmentation, boundary detection, monocular depth and surface normal estimation. We demonstrate that PAG allows competitive or state-of-the-art performance on these tasks. Our experiments show that PAG learns dynamic spatial allocation of computation over the input image which provides better performance trade-offs compared to related approaches (e.g., truncating deep models or dynamically skipping whole layers). Generally, we observe PAG can reduce computation by $10\%$ without noticeable loss in accuracy and performance degrades gracefully when imposing stronger computational constraints.
Fine-Grained Facial Expression Analysis Using Dimensional Emotion Model
May 02, 2018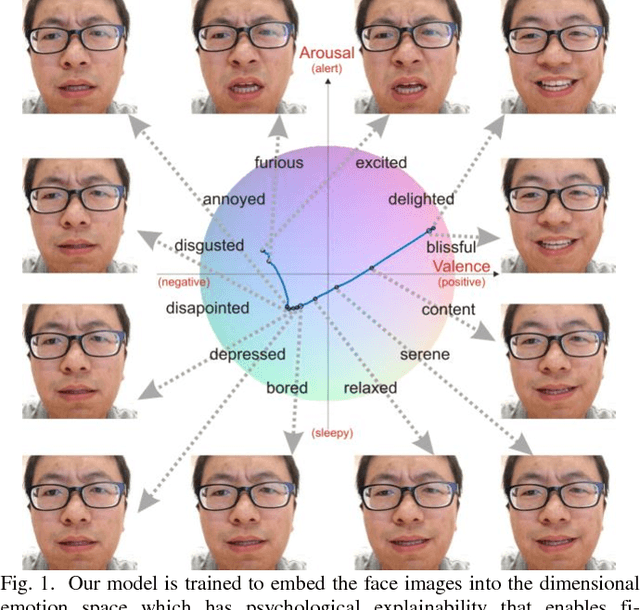
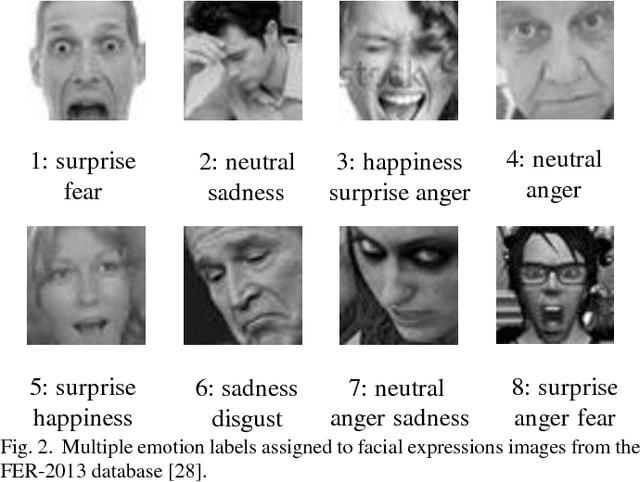
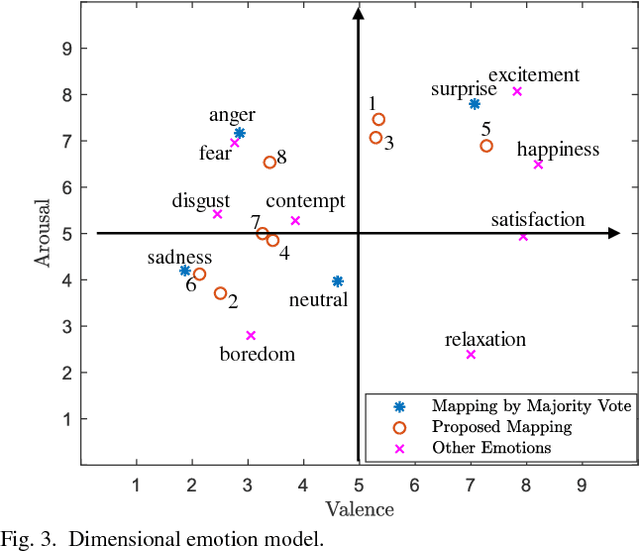
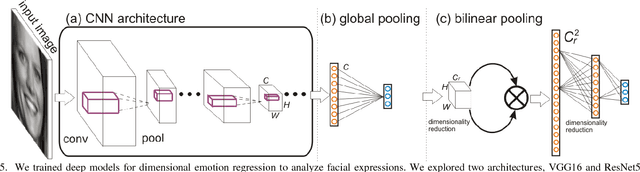
Automated facial expression analysis has a variety of applications in human-computer interaction. Traditional methods mainly analyze prototypical facial expressions of no more than eight discrete emotions as a classification task. However, in practice, spontaneous facial expressions in naturalistic environment can represent not only a wide range of emotions, but also different intensities within an emotion family. In such situation, these methods are not reliable or adequate. In this paper, we propose to train deep convolutional neural networks (CNNs) to analyze facial expressions explainable in a dimensional emotion model. The proposed method accommodates not only a set of basic emotion expressions, but also a full range of other emotions and subtle emotion intensities that we both feel in ourselves and perceive in others in our daily life. Specifically, we first mapped facial expressions into dimensional measures so that we transformed facial expression analysis from a classification problem to a regression one. We then tested our CNN-based methods for facial expression regression and these methods demonstrated promising performance. Moreover, we improved our method by a bilinear pooling which encodes second-order statistics of features. We showed such bilinear-CNN models significantly outperformed their respective baselines.
Structured Triplet Learning with POS-tag Guided Attention for Visual Question Answering
Jan 24, 2018

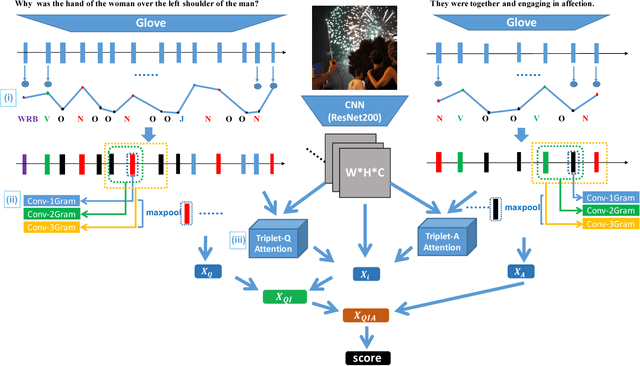
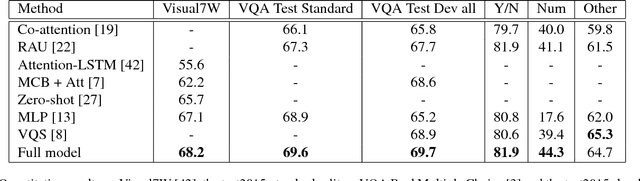
Visual question answering (VQA) is of significant interest due to its potential to be a strong test of image understanding systems and to probe the connection between language and vision. Despite much recent progress, general VQA is far from a solved problem. In this paper, we focus on the VQA multiple-choice task, and provide some good practices for designing an effective VQA model that can capture language-vision interactions and perform joint reasoning. We explore mechanisms of incorporating part-of-speech (POS) tag guided attention, convolutional n-grams, triplet attention interactions between the image, question and candidate answer, and structured learning for triplets based on image-question pairs. We evaluate our models on two popular datasets: Visual7W and VQA Real Multiple Choice. Our final model achieves the state-of-the-art performance of 68.2% on Visual7W, and a very competitive performance of 69.6% on the test-standard split of VQA Real Multiple Choice.
Recurrent Pixel Embedding for Instance Grouping
Dec 22, 2017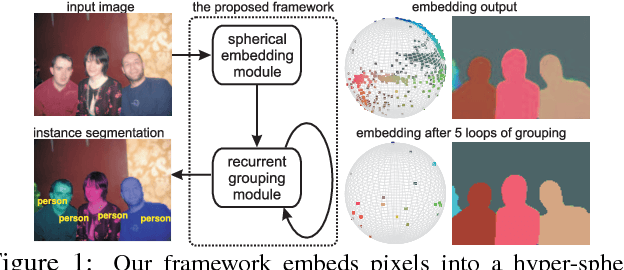
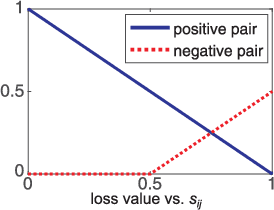
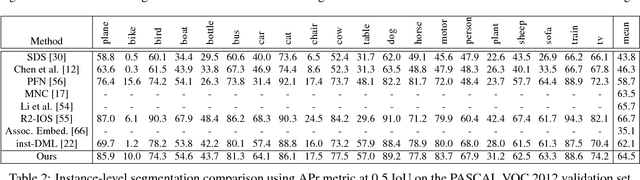
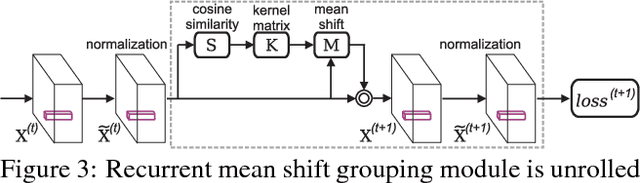
We introduce a differentiable, end-to-end trainable framework for solving pixel-level grouping problems such as instance segmentation consisting of two novel components. First, we regress pixels into a hyper-spherical embedding space so that pixels from the same group have high cosine similarity while those from different groups have similarity below a specified margin. We analyze the choice of embedding dimension and margin, relating them to theoretical results on the problem of distributing points uniformly on the sphere. Second, to group instances, we utilize a variant of mean-shift clustering, implemented as a recurrent neural network parameterized by kernel bandwidth. This recurrent grouping module is differentiable, enjoys convergent dynamics and probabilistic interpretability. Backpropagating the group-weighted loss through this module allows learning to focus on only correcting embedding errors that won't be resolved during subsequent clustering. Our framework, while conceptually simple and theoretically abundant, is also practically effective and computationally efficient. We demonstrate substantial improvements over state-of-the-art instance segmentation for object proposal generation, as well as demonstrating the benefits of grouping loss for classification tasks such as boundary detection and semantic segmentation.
Recurrent Scene Parsing with Perspective Understanding in the Loop
Dec 06, 2017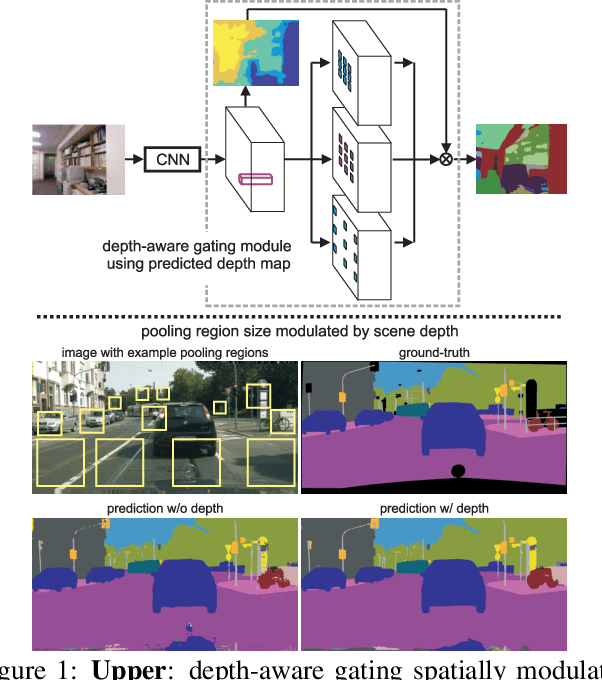
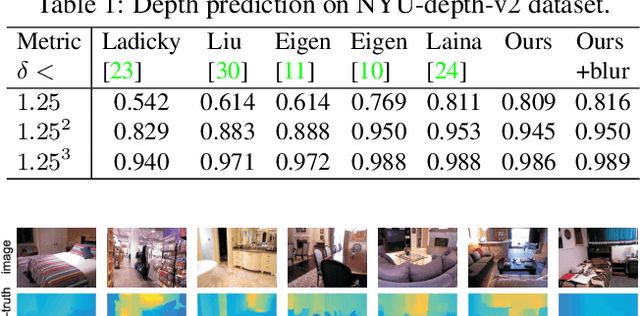
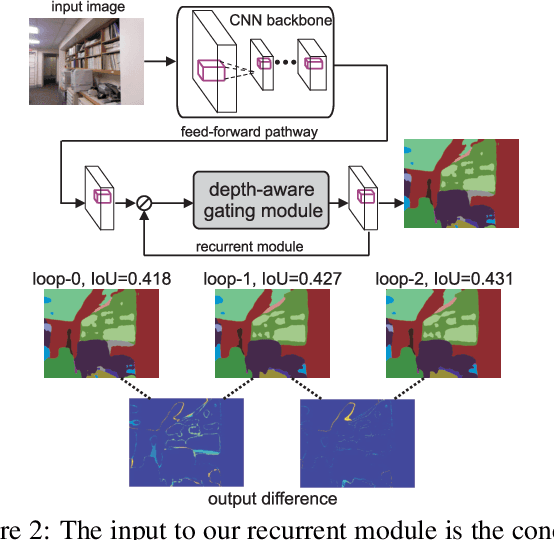
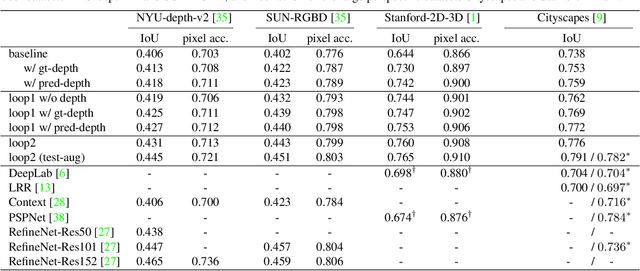
Objects may appear at arbitrary scales in perspective images of a scene, posing a challenge for recognition systems that process images at a fixed resolution. We propose a depth-aware gating module that adaptively selects the pooling field size in a convolutional network architecture according to the object scale (inversely proportional to the depth) so that small details are preserved for distant objects while larger receptive fields are used for those nearby. The depth gating signal is provided by stereo disparity or estimated directly from monocular input. We integrate this depth-aware gating into a recurrent convolutional neural network to perform semantic segmentation. Our recurrent module iteratively refines the segmentation results, leveraging the depth and semantic predictions from the previous iterations. Through extensive experiments on four popular large-scale RGB-D datasets, we demonstrate this approach achieves competitive semantic segmentation performance with a model which is substantially more compact. We carry out extensive analysis of this architecture including variants that operate on monocular RGB but use depth as side-information during training, unsupervised gating as a generic attentional mechanism, and multi-resolution gating. We find that gated pooling for joint semantic segmentation and depth yields state-of-the-art results for quantitative monocular depth estimation.
Low-rank Bilinear Pooling for Fine-Grained Classification
Nov 30, 2016

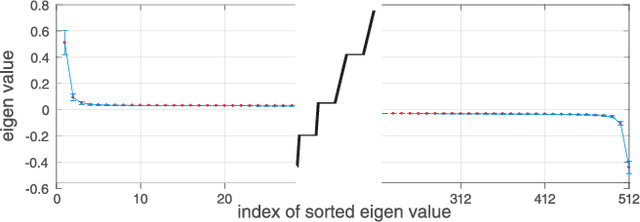
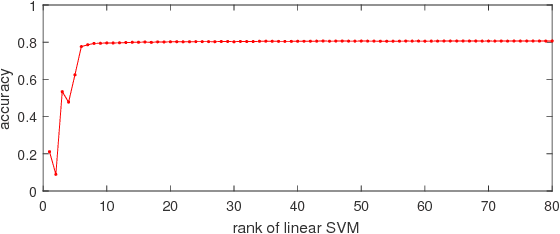
Pooling second-order local feature statistics to form a high-dimensional bilinear feature has been shown to achieve state-of-the-art performance on a variety of fine-grained classification tasks. To address the computational demands of high feature dimensionality, we propose to represent the covariance features as a matrix and apply a low-rank bilinear classifier. The resulting classifier can be evaluated without explicitly computing the bilinear feature map which allows for a large reduction in the compute time as well as decreasing the effective number of parameters to be learned. To further compress the model, we propose classifier co-decomposition that factorizes the collection of bilinear classifiers into a common factor and compact per-class terms. The co-decomposition idea can be deployed through two convolutional layers and trained in an end-to-end architecture. We suggest a simple yet effective initialization that avoids explicitly first training and factorizing the larger bilinear classifiers. Through extensive experiments, we show that our model achieves state-of-the-art performance on several public datasets for fine-grained classification trained with only category labels. Importantly, our final model is an order of magnitude smaller than the recently proposed compact bilinear model, and three orders smaller than the standard bilinear CNN model.
Tracking Objects with Higher Order Interactions using Delayed Column Generation
Aug 09, 2016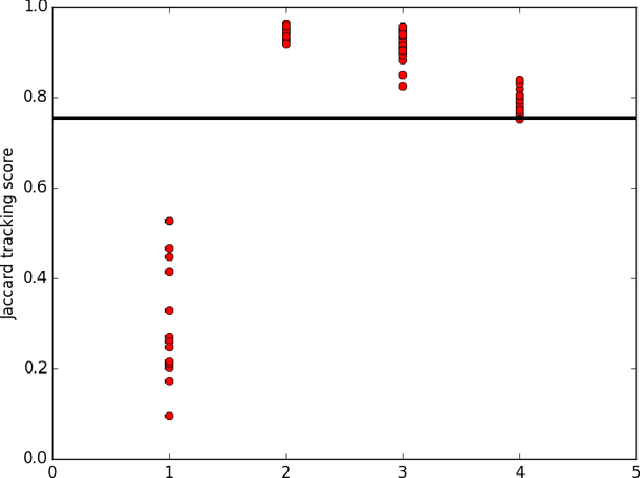
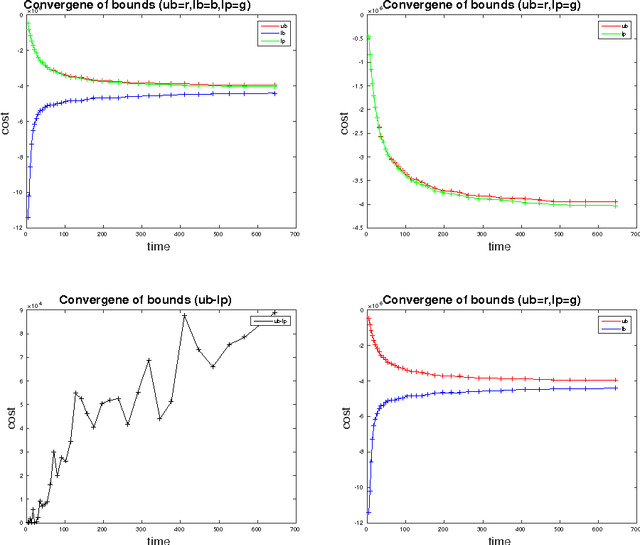
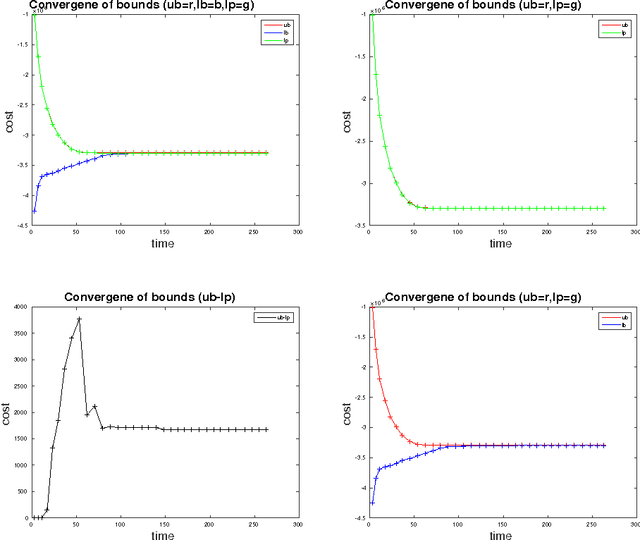
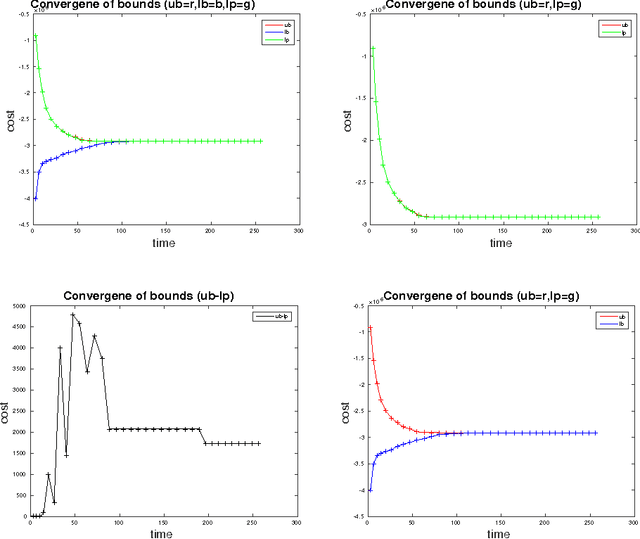
We study the problem of multi-target tracking and data association in video. We formulate this in terms of selecting a subset of high-quality tracks subject to the constraint that no pair of selected tracks is associated with a common detection (of an object). This objective is equivalent to the classic NP-hard problem of finding a maximum-weight set packing (MWSP) where tracks correspond to sets and is made further difficult since the number of candidate tracks grows exponentially in the number of detections. We present a relaxation of this combinatorial problem that uses a column generation formulation where the pricing problem is solved via dynamic programming to efficiently explore the space of tracks. We employ row generation to tighten the bound in such a way as to preserve efficient inference in the pricing problem. We show the practical utility of this algorithm for tracking problems in natural and biological video datasets.
Photo Aesthetics Ranking Network with Attributes and Content Adaptation
Jul 27, 2016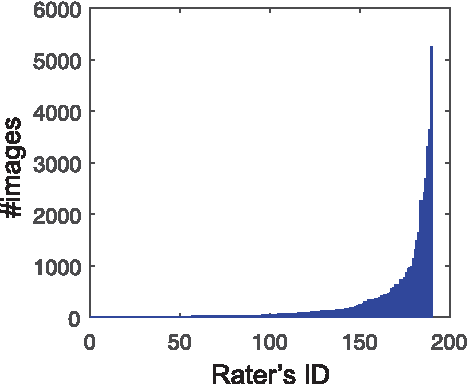

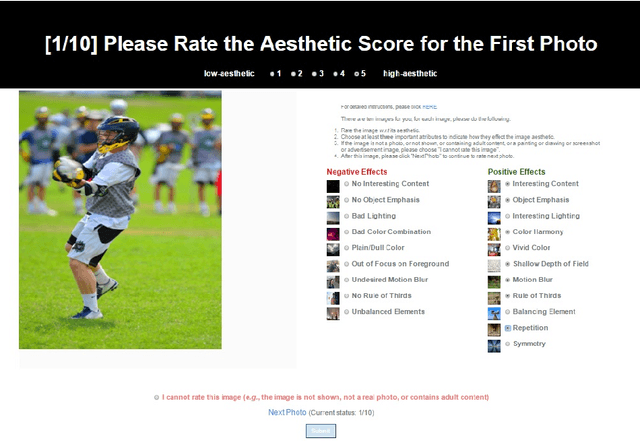
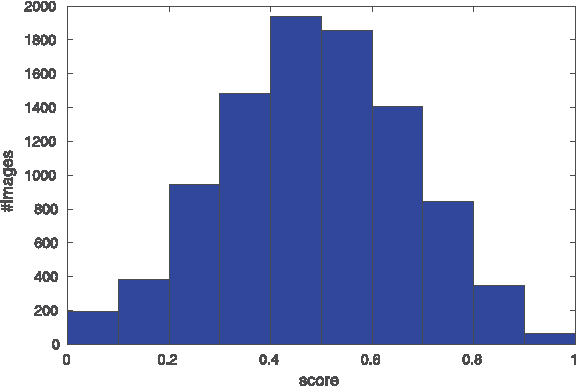
Real-world applications could benefit from the ability to automatically generate a fine-grained ranking of photo aesthetics. However, previous methods for image aesthetics analysis have primarily focused on the coarse, binary categorization of images into high- or low-aesthetic categories. In this work, we propose to learn a deep convolutional neural network to rank photo aesthetics in which the relative ranking of photo aesthetics are directly modeled in the loss function. Our model incorporates joint learning of meaningful photographic attributes and image content information which can help regularize the complicated photo aesthetics rating problem. To train and analyze this model, we have assembled a new aesthetics and attributes database (AADB) which contains aesthetic scores and meaningful attributes assigned to each image by multiple human raters. Anonymized rater identities are recorded across images allowing us to exploit intra-rater consistency using a novel sampling strategy when computing the ranking loss of training image pairs. We show the proposed sampling strategy is very effective and robust in face of subjective judgement of image aesthetics by individuals with different aesthetic tastes. Experiments demonstrate that our unified model can generate aesthetic rankings that are more consistent with human ratings. To further validate our model, we show that by simply thresholding the estimated aesthetic scores, we are able to achieve state-or-the-art classification performance on the existing AVA dataset benchmark.