 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoc2Query++: Topic-Coverage based Document Expansion and its Application to Dense Retrieval via Dual-Index Fusion
Oct 10, 2025
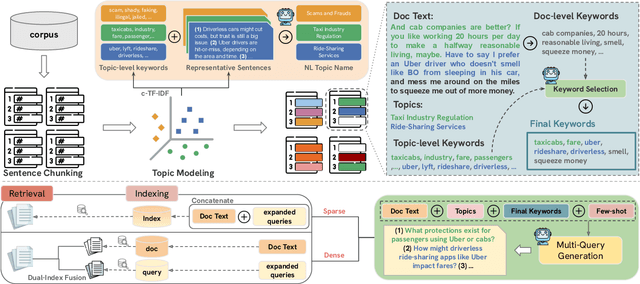
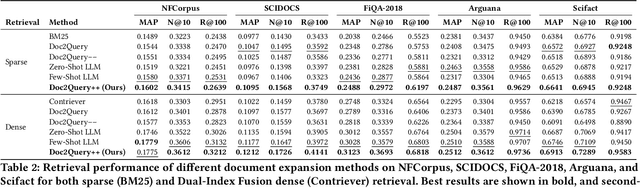
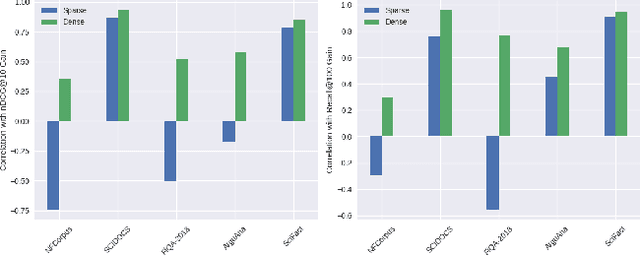
Document expansion (DE) via query generation tackles vocabulary mismatch in sparse retrieval, yet faces limitations: uncontrolled generation producing hallucinated or redundant queries with low diversity; poor generalization from in-domain training (e.g., MS MARCO) to out-of-domain data like BEIR; and noise from concatenation harming dense retrieval. While Large Language Models (LLMs) enable cross-domain query generation, basic prompting lacks control, and taxonomy-based methods rely on domain-specific structures, limiting applicability. To address these challenges, we introduce Doc2Query++, a DE framework that structures query generation by first inferring a document's latent topics via unsupervised topic modeling for cross-domain applicability, then using hybrid keyword selection to create a diverse and relevant keyword set per document. This guides LLM not only to leverage keywords, which ensure comprehensive topic representation, but also to reduce redundancy through diverse, relevant terms. To prevent noise from query appending in dense retrieval, we propose Dual-Index Fusion strategy that isolates text and query signals, boosting performance in dense settings. Extensive experiments show Doc2Query++ significantly outperforms state-of-the-art baselines, achieving substantial gains in MAP, nDCG@10 and Recall@100 across diverse datasets on both sparse and dense retrieval.
A Survey of Generative Information Retrieval
Jun 04, 2024Generative Retrieval (GR) is an emerging paradigm in information retrieval that leverages generative models to directly map queries to relevant document identifiers (DocIDs) without the need for traditional query processing or document reranking. This survey provides a comprehensive overview of GR, highlighting key developments, indexing and retrieval strategies, and challenges. We discuss various document identifier strategies, including numerical and string-based identifiers, and explore different document representation methods. Our primary contribution lies in outlining future research directions that could profoundly impact the field: improving the quality of query generation, exploring learnable document identifiers, enhancing scalability, and integrating GR with multi-task learning frameworks. By examining state-of-the-art GR techniques and their applications, this survey aims to provide a foundational understanding of GR and inspire further innovations in this transformative approach to information retrieval. We also make the complementary materials such as paper collection publicly available at https://github.com/MiuLab/GenIR-Survey/